一、相关概念 1 历史背景
传统AI :机器学习、深度学习、强化学习
2017年提出的Transformer架构,奠定了大模型领域主流算法架构的基石
大模型时代 :神经网络、自注意力机制、Transformer
两者之间的区别:
模型结构和算法
灵活性和可扩展性 数据规模和多样性
任务范围和性能方面 计算资源和成本
2 什么是AI大模型
大语言模型(英文:Large Language Model,缩写LLM)
概念:大型语言模型(LLM)之所以大,是指具有大规模参数和复杂计算结构(超过 10 亿个参数),LLM通常基于 Transformer 模型架构,由深度神经网络构建,对海量数据进行预训练处理。
LLM的特点:
LLM的特点是规模庞大,包含数十亿的参数,(GPT-3有1750亿个参数)
LLM是在大量文本数据集(如书籍、网站或用户生成内容)上进行训练的。
模型组成
3 大模型分类 按照输入数据类型 的不同,大模型主要可以分为以下三大类:
语言大模型:是指在自然语言处理(Natural Language Processing,NLP)领域中的一类大模型,通常用于处理文本数据和理解自然语言。
视觉大模型:是指在计算机视觉(Computer Vision,CV)领域中使用的大模型通常用于图像处理和分析。资源代找 网课代下+V备用:
多模态大模型:是指能够处理多种不同类型数据的大模型,例如文本、图像、音频等多模态数据。这类模型结合了NLP和CV的能力。
4 现有模型 当前比较好的、令人瞩目的AI产品:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 LLaMA3 (✳):开源controlNet :他的成果奠定了AI能局部修改Alpaca :开源,在LLaMA的基础上进行微调,奠定了微调的基石Vicuna 13 B:开源,非常值得看源码Mistral 7 B:开源Yi_34B :开源Qwen deepseek GLM -4 (新一代基座大模型)
二、专有名词 1 普通名词 RAG(Retrieval-Augmented Generation,检索增强生成) :是一种 AI 框架,它将传统信息检索系统(例如数据库)的优势与生成式大语言模型 (LLM) 的功能结合在一起。
TopN :相似度最高的前N个
**AIGC(AI Generated Content,AI生成内容):**利用AI技术生成内容,例如文本、图像、音频、视频等
AGI(Artificial General Intelligence,通用人工智能) :像人类一样思考、学习、执行多种任务的系统
2 开发名词 Prompt:
要让ChatGPT干活,你得把要干什么活(Prompt)告诉ChatGPT
Prompt Engieering:
通过开发和优化提示词(Prompt),帮助大语言模型应用于各个场景,并且工作的专业,准确。
temperature:
可以增加模型输出的随机性,增加 temperature 可以增加模型输出的随机性,从而提高了回复的多样性,但降低了质量。
**Top P **:
控制多样性,值越小 ,生成结果越保守;越大,结果越多样。
Frequency_penalty:
控制生成文本中单词或短语的整体频率。值越高 ,模型更倾向于生成包含低频词汇和短语的文本,以增加文本的多样性。较低 ,模型可能更倾向于生成包含高频词汇和短语的女小
presence_penalty:
控制生成文本中特定单词或短语的存在频率。较高 ,会模型更倾向于在生成的文本中包含多样性更大的单词和短语,减少重复性。较低的presence_penalty 模型可能更倾向于生成包含和输入相近的文本重复性
**零样本思维链:**lets think step by step
自治性(Self-consistency):
是对 CoT|CoT prompting的一个补充,它不仅仅生成一个思路链,而是生成多个思路链,然后取多数答案作为最终答案。例如给出三种推理过程,将结果少数服从多数。
思维树(ToT:Tree-of-Thought):
是一种新的语言模型推理方法允许对连贯文本单元“思想”进行探索,这些单元作为解决问题的中间步骤。ToT将任何问题框定为在树上搜索,其中每个节点都是一个状态,由文本输入和语言模型生成的一系列思想组成 。ToT允许语言模型通过考虑**多个不同的推理路径和自我评估选择来进行有意识的决策,**并在必要时向前或后跟踪以做出全局选择
三、HuggingFace 1 安装
pip install transformers
pip install datasets
2 基本使用 2.1 编码器 1 自定义编码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 sentence = 'hello everyone , today is a good day .' '<SOS>' : 0 ,'<EOS>' : 1 ,'hello' : 2 ,'everyone' : 3 ,'today' : 4 ,'is' : 5 ,'a' : 6 ,'good' : 7 ,'day' : 8 ,',' : 9 ,'.' : 10 '<SOS> ' + sentence + ' <EOS>' print (new_sentence)for i in words]
2 使用编码器工具
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 from transformers import BertTokenizer'bert-base-chinese' ,'../runs/cache' ,False '你站在桥上看风景' ,'看风景的人在楼上看你' ,'明月装饰了你的窗子' ,'你装饰了别人的梦' 0 ],1 ],True , 'max_length' ,True , 25 ,None print (out)
进阶版:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 0 ],1 ],True ,'max_length' ,True ,25 ,None ,True ,True ,True ,True for k, v in out.items():print (k, ':' , v)
自定义新词:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 '明月' , '装饰' , '你的' , '窗子' ])'eos_token' : '[EOS]' })for word in ['明月' , '装饰' , '你的' , '窗子' , '[EOS]' ]:print (tokenizer.get_vocab()[word])'明月装饰了你的窗子[EOS]' ,None ,True ,'max_length' ,True ,10 ,None print (out)
2.2 数据集操作 一般数据集:
1 2 3 4 5 6 7 from datasets import load_dataset'lansinuote/ChnSentiCorp' ,'../runs/cache' ,
大的数据集下加载小的数据集:
1 2 3 4 5 6 7 8 'glue' ,'sst2' ,'train' ,'../runs/cache'
基本操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 dataset = dataset['train' ]print (train)'label' )10 )for i in range (0 , 51 , 10 )])print (select_dataset)def func (data ):return data['text' ].startswith('非常不错' )print (dataset.filter (func))print (dataset.train_test_split(test_size=0.1 ))print (dataset.shard(num_shards=10 , index=0 ))print (dataset.rename_column('text' , 'text_name' ))print (train)'label' ])print (remove_dataset)def add_prefix (data ):'text' ] = 'sentences: ' + data['text' ]return datamap (function=add_prefix)print (map_dataset['text' ][:5 ])def batch_speed (data ):'text' ]'sentences:' + i for i in text]'text' ] = textreturn datamap (True ,1000 ,4 print (batch_map['text' ][0 ])print (dataset['text' ][0 ])type ='torch' , columns=['label' ], output_all_columns=True )20 ]
文件保存:
1 2 3 4 5 6 7 8 9 10 11 12 './ChnSentiCorp.csv' )'csv' , data_files='./ChnSentiCorp.csv' , split='train' )'./ChnSentiCorp.json' )'json' , data_files='./ChnSentiCorp.json' , split='train' )
2.3 模型评估 1 2 3 4 5 6 from evaluate import *"accuracy" )'glue' , config_name='mrpc' , cache_dir='../runs/cache' )
四、Langchain框架 1 概念 LangChain是一个用于开发由大型语言模型(LLMS) 驱动的应用程序的框架。
LangChain 简化了 LLM 应用程序生命周期的每个阶段:
开发:使用 LangChàin 的开源构建模块、组件 第三方集成
生产化:使用LangSmith
部署:将您的LangGraph LangGraph Cloud
2 组成 Langchain框架由以下开源库组成:
langchain-core: **langchain-community:**第三方集成。
合作伙伴库(例如 langchain-openai、langchain-anthropic 等):一些集成已进一步拆分为自己的轻量级库,仅依赖于langchain-core。
langchain:组成应用程序认知架构的链、代理和检索策略。
LangGraph: LangServe:将LangChain链部署为REST API。
LangSmith:一个开发者平台,让您调试、测试、评估和监控LLM应用程序。
3 demo 3.1 demo1记忆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 from langchain_community.chat_message_histories import SQLChatMessageHistoryfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderfrom langchain_core.runnables import RunnableWithMessageHistoryfrom langchain_openai import ChatOpenAIfrom pydantic import SecretStr'https://api.openai.com/v1' ,'gpt-4o-mini' ,1.0 'system' , '你是一个幽默的聊天机器人。' ),'history' ),'user' , '{input}' )def get_session_history (sid ):""" 根据会话的ID,读取和保存历史记录,必须返回BaseChatMessageHistory :param sid: :return: """ return SQLChatMessageHistory(sid, connection='sqlite:///history.db' )'input' ,'history' 'input' : '中国一共有哪些直辖市' },'configurable' : {'session_id' : 'no.1' }})print (resp1)print ('--' * 30 )'input' : '这些城市中哪个最大?' },'configurable' : {'session_id' : 'no.1' }})print (resp2)print ('--' * 30 )
3.2 链式调用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain_openai import ChatOpenAIfrom pydantic import SecretStr0.5 ,'https://open.bigmodel.cn/api/paas/v4/' ,'glm-4' '给我写一篇关于{key_word}的{type},字数不得超过{count}字。' )'如果满分是10分,请评价一下这篇文章并给短文打分:{text_content}。' )def print_chain1 (text_content ):print (text_content)print ('---' * 30 )return {'text_content' : text_content}print (chain2.invoke({'key_word' : '青春' ,'type' : '散文' ,'count' : 400
3.3 订餐demo 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 from langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import PromptTemplatefrom langchain_core.runnables import RunnableLambdafrom langchain_openai import ChatOpenAIfrom pydantic import SecretStr0.5 ,'https://api.deepseek.com' ,'deepseek-chat' '用户输入了一些餐厅偏好:{input_text1}\n' '请将用户的偏好总结为清晰的需求:' )'请根据用户的需求:{input_text2}\n,' '请推荐3家合适的餐厅,并说明推荐理由:' )'以下是餐厅推荐和推荐理由:\n{input_text3}\n' '请总结成 2-3 句话,供用户快速参考:' )print (chain.invoke({'input_text1' : '我喜欢安静的地方,不喜欢人多的地方,价格不贵,环境好,有包间,有停车位' }))
3.4 动态路由调用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 from langchain_core.output_parsers import StrOutputParser, JsonOutputParserfrom langchain_core.prompts import PromptTemplate, ChatPromptTemplatefrom langchain_core.runnables import RunnableLambda, RouterRunnable, RunnableSequencefrom langchain_openai import ChatOpenAIfrom pydantic import SecretStr0 ,'https://api.deepseek.com' ,'deepseek-chat' '你是一位物理学教授,稍长用简洁易懂的方式回答物理问题。以下是问题内容:{input}' '你是一位数学教授,擅长分步骤解决数学问题,并提供详细的解决过程。以下是问题的内容:{input}' '你是一位历史教授,对历史事件和背景有深入研究。以下是问题的内容:{input}' '你是一位计算机科学专家,擅长算法、数据结构和编程问题。以下是问题的内容:{input}' "你是一位专家,请你用简洁易懂的方式回答问题。以下是问题的内容:{input}" def route (input if "物理" in input ["type" ]:print ("物理mode" )return {"key" : "physics" , "input" : input ["input" ]}elif "数学" in input ["type" ]:print ("数学mode" )return {"key" : "math" , "input" : input ["input" ]}elif "历史" in input ["type" ]:print ("历史mode" )return {"key" : "history" , "input" : input ["input" ]}elif "计算机" in input ["type" ]:print ("计算机mode" )return {"key" : "computer_science" , "input" : input ["input" ]}else :print ("default mode" )return {"key" : "default" , "input" : input ["input" ]}"physics" : physics_chain,"math" : math_chain,"history" : history_chain,"computer_science" : computer_science_chain,"default" : default_chain"不要回答下面用户的问题,只要根据用户的输入来判断分类,一共有[物理、历史、计算机、数学、其他]5种类别。\n\n \ 用户输入:{input}\n\n \ 最后的输出包含分类的类别和用户输入的内容,输出格式为json。其中,类别的key为type,用户输入内容的key为input。" "input" : "什么是黑体辐射?" }, "input" : "计算 2+2 的结果。" }, "input" : "介绍一次世界大战的背景。" }, "input" : "如何实现快速排序算法?" } for i in inputs:print (f"问题:{i} \n 结果:{res} \n" )
4 语法 4.1 节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import timefrom langchain_core.runnables import RunnableLambda, RunnableParallel, RunnablePassthroughfrom langchain_core.tracers import Rundef test (x: int ):return x + 10 def test2 (prompt: str ):for item in prompt.split(' ' ):yield itemlambda x: x * 2 )
4.2 批量、流式调用 1 2 3 4 5 6 7 8 9 10 11 12 13 4 , 5 , 6 ])'How are you?' ) for chunk in res:print (chunk)print (chain.invoke(2 ))
4.3 并行运行并打印流程 1 2 3 4 5 6 7 8 9 10 11 print (chain2.invoke(2 , config={'max_concurrency' : 1 }))print (chain3.invoke(2 ))
4.4 合并处理中间数据 1 2 3 4 5 6 7 8 9 10 lambda x: {'key1' : x})lambda x: x['key1' ]+ 10 )'dict2' ])print (chain_dict.invoke(2 ))
4.5 异常处理 1 2 3 4 5 lambda x: int (x) + 20 )print (chain.invoke('2' ))
4.6 重复执行 1 2 3 4 5 6 7 8 9 10 11 12 13 0 def test3 (x ):global counter1 print (f'执行了{counter} 次' )return x / 0 3 )print (r4.invoke(2 ))
4.7 动态链 1 2 3 4 5 6 lambda x: [x] * 2 )lambda x: r5 if x > 10 else RunnablePassthrough().assign(res=x))print (chain.invoke(2 ))
4.8 生命周期管理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def test4 (x: int ):return x * 2 def on_start (run_obj: Run ):print ('r6开始执行的时间:' , run_obj.start_time)def on_end (run_obj: Run ):print ('r6结束执行的时间:' , run_obj.end_time)print (chain.invoke(2 ))
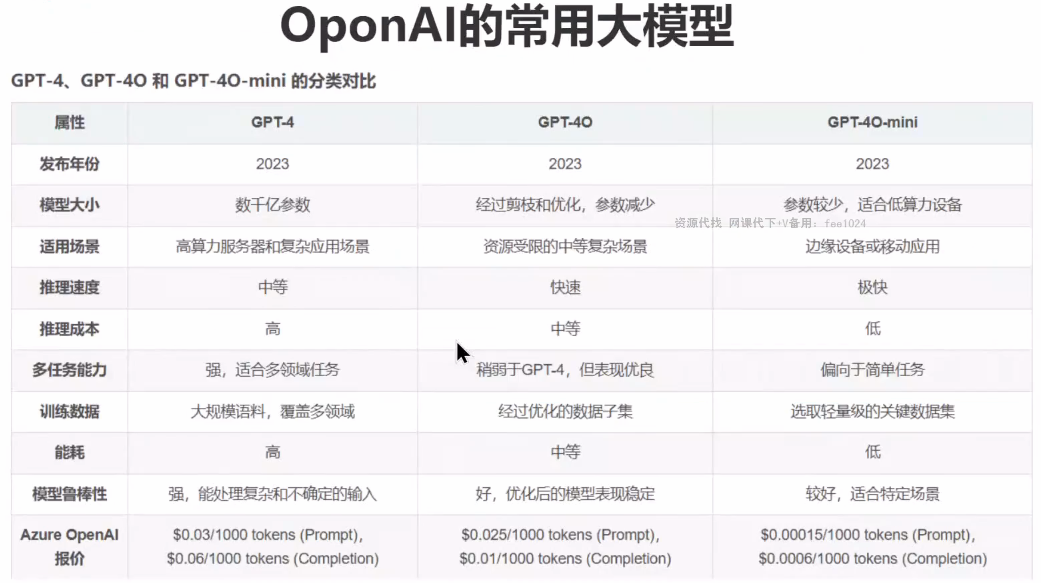
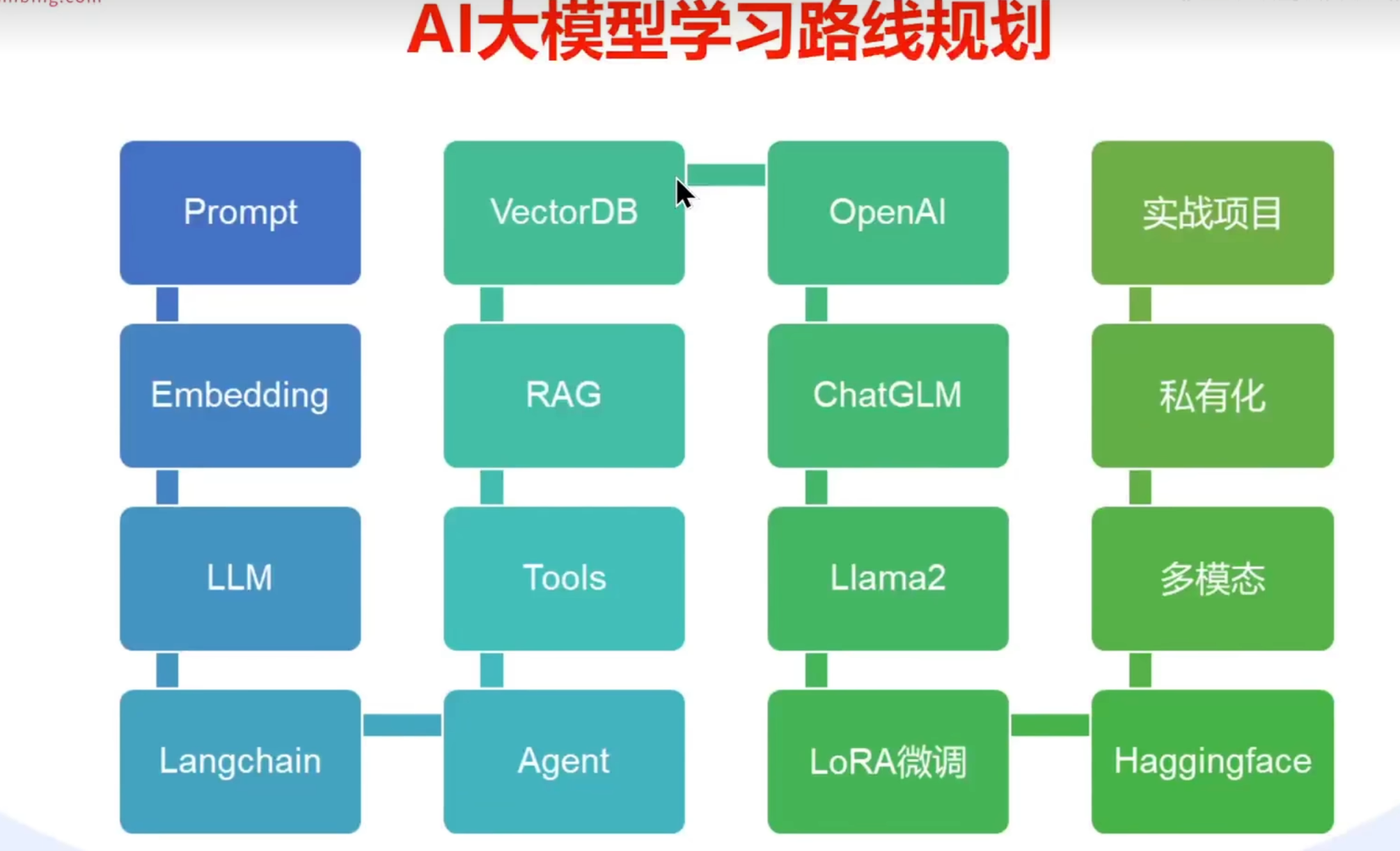
五、模型开发 1 学习路线 首先安装Openai库:pip install openai
2 模型参数 model: 必选参数,大模型的名称;
messages: 必选参数,提示词;
max_tokens: 可选参数,代表返回结果的token数量;
temperature :可选参数,取值范围为0-2,默认值为1。参数代表采样温度,数值越小,则模型会倾向于选择概率较高的词汇,生成的文本会更加保守;而当temperature值较高时,模型会更多地选择概率较低的词汇,生成的文本会更加多样;
top_p :可选参数,取值范围为0-1,默认值为1,和temperature作用类似,用于控制输出文本的随机性,数值越趋近与1,输出文本随机性越强,越趋近于0文本随机性越弱;
top_p和temperature两个参数选择一个进行调整即可;这里更推荐使用temperature参数进行文本随机性调整;
n :可选参数,默认值为1,表示一个提示返回几个Completion;
stream :可选参数,默认值为False,表示回复响应的方式,当为False时,模型会等待返回结果全部生成后一次性返回全部结果,而为True时,则会逐个字进行返回;
stop :可选参数,默认为null,该参数接受一个或多个字符串,用于指定生成文本的停止信号。当模型生成的文本遇到这些字符串中的任何一个时,会立即停止生成。这可以用来控制模型的输出长度或格式;
分别用于控制生成文本中新单词的出现频率和单词的重复频率,可以避免生成的文本过于重复或单调
presence penalty :可选参数,默认为0,取值范围为[-2, 2],该参数用于调整模型生成新内容(例如新的概念或主题)的倾向性。较高的值会使模型更倾向于生成新内容,而较低的值则会使模型更倾向于坚持已有的内容,当返回结果篇幅较大并且存在前后主题重复时,可以提高该参数的取值;
frequency penalty :可选参数,默认为0,取值范围为[-2, 2],该参数用于调整模型重复自身的倾向性。较高的值会使模型更倾向于避免重复,而较低的值则会使模型更可能重复自身;当返回结果篇幅较大并且存在前后语言重复时,可以提高该参数的取值;
tools :可以调用的函数;
tool choice :调用函数的策略;
3 Embeddings模型 概念:Embeddings(嵌入)在自然语言处理(NLP)中起着至关重要的作用,它们的主要目的是将高维、离散的文本数据(如单词或短语)转换为低维、连续的向量表示。这些向量不仅编码了词本身的含义,还捕捉到了词语之间的语义和句法关系。通过embeddings,原本难以直接处理的文本数据可以被机器学习模型理解和操作。
计算模型相似度:
余弦相似度是一个衡量两个非零向量之间夹角的度量,它给出的是这两个向量在多大程度上指向相同的方向。余弦相似度的值域是[-1,1],其中1表示两个向量完全相同方向,-1表示完全相反方向,而0则表示两个向量正交(即不相关)。
$cosine=\frac{a·b}{||a|| · ||b||}$
4 训练私有模型
确认应用场景 :确定模型能力、并进行模型选择数据处理 :数据采集、数据清洗、数据配比(垂直和通用、每个数据源的配比) 预训练 :模型设计(size、结构、专有领域的tokenizer)Fine-Tuning
benchmark:对训练模型进行评测