AlexNet论文+复现
在2012年时候,由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在ImageNet LSVRC-2010图像分类竞赛中提出的一种经典的卷积神经网络,由于他的出现和在 ImageNet 大规模视觉识别竞赛中取得了优异的成绩,把深度学习模型在比赛中的正确率提升到一个前所未有的高度,他的结果在测试集上取得 top-1错误率37.5%、top-5错误率17.0%,显著优于此前最优结果。ILSVRC-2012版本模型进一步提升至 top-5错误率15.3%(对比第二名26.2%)。比第二名整整高了近11个百分点。论文我将从结构剖析、创新点分析以及根据pytorch进行代码复现。
一、架构剖析
首先,输入的图片是RGB三通道,我们可以先不管输入图像的大小规格是怎样的,因为输入之后会对图像进行裁剪,给定一个矩形图像,我们首先将图像缩放,使得较短的边长为256,然后从结果图像中裁剪出中心的256×256区域将图像下采样(PS:高斯金字塔,下采样方向向下,关注的数据量减少,特征提取压缩,降噪)到固定的256 × 256 × 3。下图就是截取的AlexNet的一个架构图。
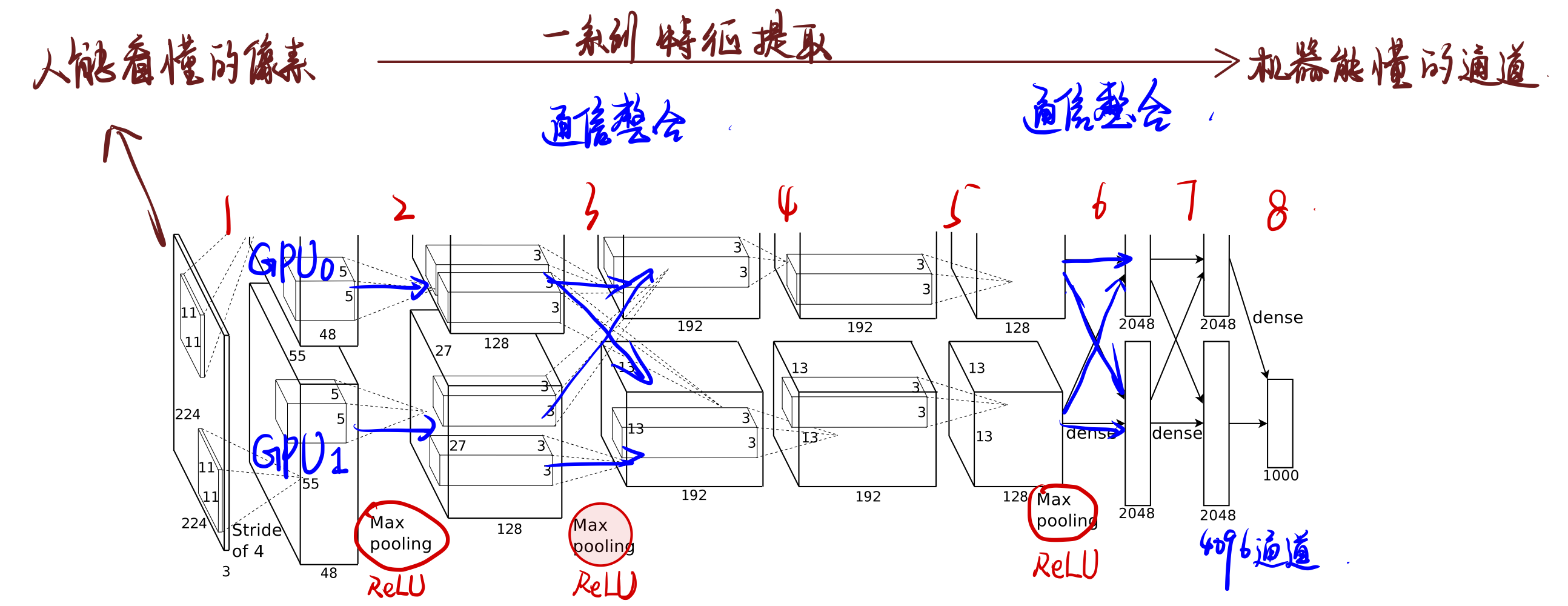
1、前五层
AlexNet共有五个卷积层,每个卷积层都包含卷积核、偏置项、ReLU激活函数和局部响应归一化(LRN)模块。
- 卷积层C1:使用96个尺寸为11 × 11 × 3的卷积核对224 × 224 × 3的输入图像进行滤波,步长为4个像素(这是卷积核图中相邻神经元感受野中心之间的距离)
- 卷积层C2:以第一个卷积层的(响应归一化和池化)输出作为输入,并使用256个尺寸为5 × 5 × 48的卷积核对其进行滤波
- 卷积层C3:有384个核,核大小为3 × 3 × 256,与卷积层C2的输出(归一化的,池化的)相连。
- 卷积层C4:有384个核,核大小为3 × 3 × 192。
- 卷积层C5:有256个核,核大小为3 × 3 × 192。卷积层C5与C3、C4层相比多了个池化,池化核size同样为3×3,stride为2。
第三、第四和第五个卷积层彼此连接,没有任何中间的池化或归一化层。
我们可看到C2到C3层、C5d到F6和F6到F7之间他们是交叉的。具体原因创新点的时候细说~
2、全连接层
全连接层F6、F7将所有的特征向量拉成一排生成4096个卷积核,加上最后一个1000-way softmax 进行分类,产生1000个类别预测的值。
二、创新点
1、双GPU训练
作者分成了两块 GTX 580 3GB GPU进行训练,值得注意的是,卷积层中只有C2到C3进行了交叉通讯信息共享,其他的卷积层都是独立的GPU在各自训练。但是到后期的时候,作者发现两个GPU所表现出的专业化分工。GPU 1上的卷积核在很大程度上与颜色无关,而GPU 2上的卷积核在很大程度上是颜色特定的。这种专业化分工在每次运行中都会发生,并且独立于任何特定的随机权重初始化(模GPU的重新编号)。
2、Dropout和数据增强
为了防止过拟合,AlexNet 引入了数据增强和 Dropout 技术。
数据增强分成了一下两种:
- 从图像大小256上,以中心区域扣224大小的图,然后进行对图像进行旋转、翻转、裁剪等变换,增加训练数据的多样性,提高模型的泛化能力。对于AlexNet进行实现来说,数据增强是免费的,因为变换后的图片不需要存储与磁盘中,他们生成于CPU上,而此刻的GPU正在训练,这样同步进行。
- 第二种是PCB降维处理,改变训练图像中RGB通道的强度
Dropout 则是在训练过程中随机删除一定比例的神经元,强制网络学习多个互不相同的子网络,从而提高网络的泛化能力。Dropout简单来说就是在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
3、ReLU激活函数的使用
AlexNet 首次使用了修正线性单元(ReLU:Rectified Linear Units)这一非线性激活函数。相比于传统的 sigmoid 和 tanh 函数,ReLU 能够在保持计算速度的同时,有效地解决了梯度消失问题,从而使得训练更加高效。
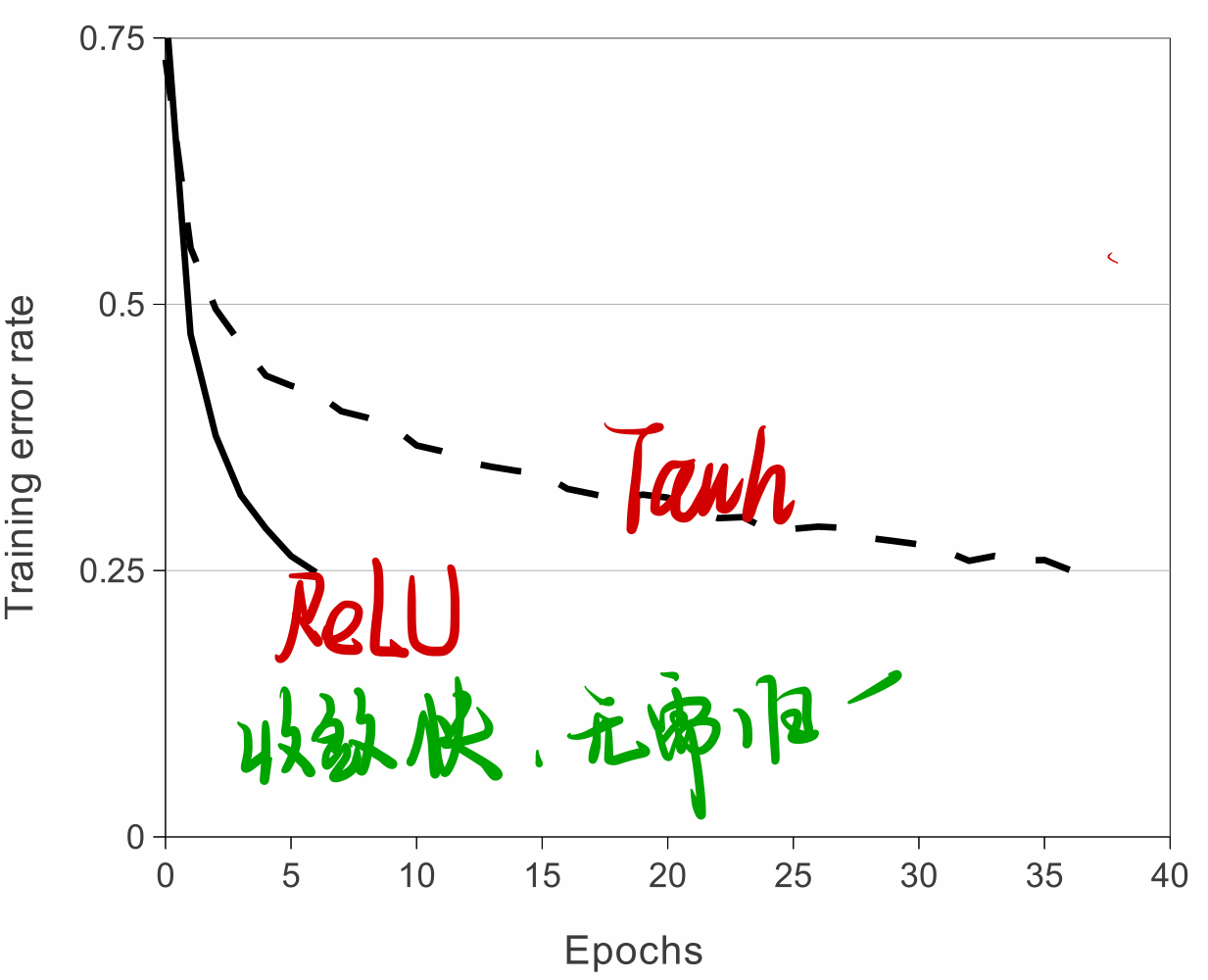
4、重叠最大池化
在CNN中使用重叠的最大池化。此前CNN中普遍使用平均池化,AlexNet全部使用最大池化,避免平均池化的模糊化效果。并且AlexNet中提出让步长比池化核的尺寸小,这样池化层的输出之间会有重叠和覆盖,提升了特征的丰富性。
5、局部响应归一化
局部响应归一化(Local Respone Normalization),对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。LRN通过在相邻卷积核生成的feature map之间引入竞争,从而有些本来在feature map中显著的特征在A中更显著,而在相邻的其他feature map中被抑制,这样让不同卷积核产生的feature map之间的相关性变小。
三、代码复现
1、定义网络模型
1 | |
2、数据集预处理
我们选择的CIFAR-10数据集
1 | |
3、定义训练函数
1 | |
4、模型训练
1 | |
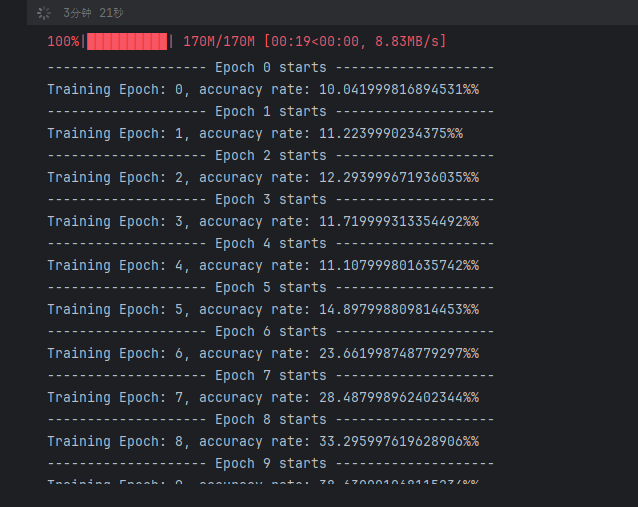
运行结果:
鸣谢
很多参考这位博主:卷积神经网络经典回顾之AlexNet - 知乎