RT-DETR and RT-DETRv2
📌 最近一直在忙于我的第一篇关于晶体检测的计算机论文,刚刚投递出去(不知道能不能中,其实心里也很忐忑)。目前再准备开始第二篇论文,准备用DETR相关的模型进行优化,这是对于RT-DETR的一些见解。论文的下载地址为:arxiv.org/pdf/2304.08069
一、模型剖析
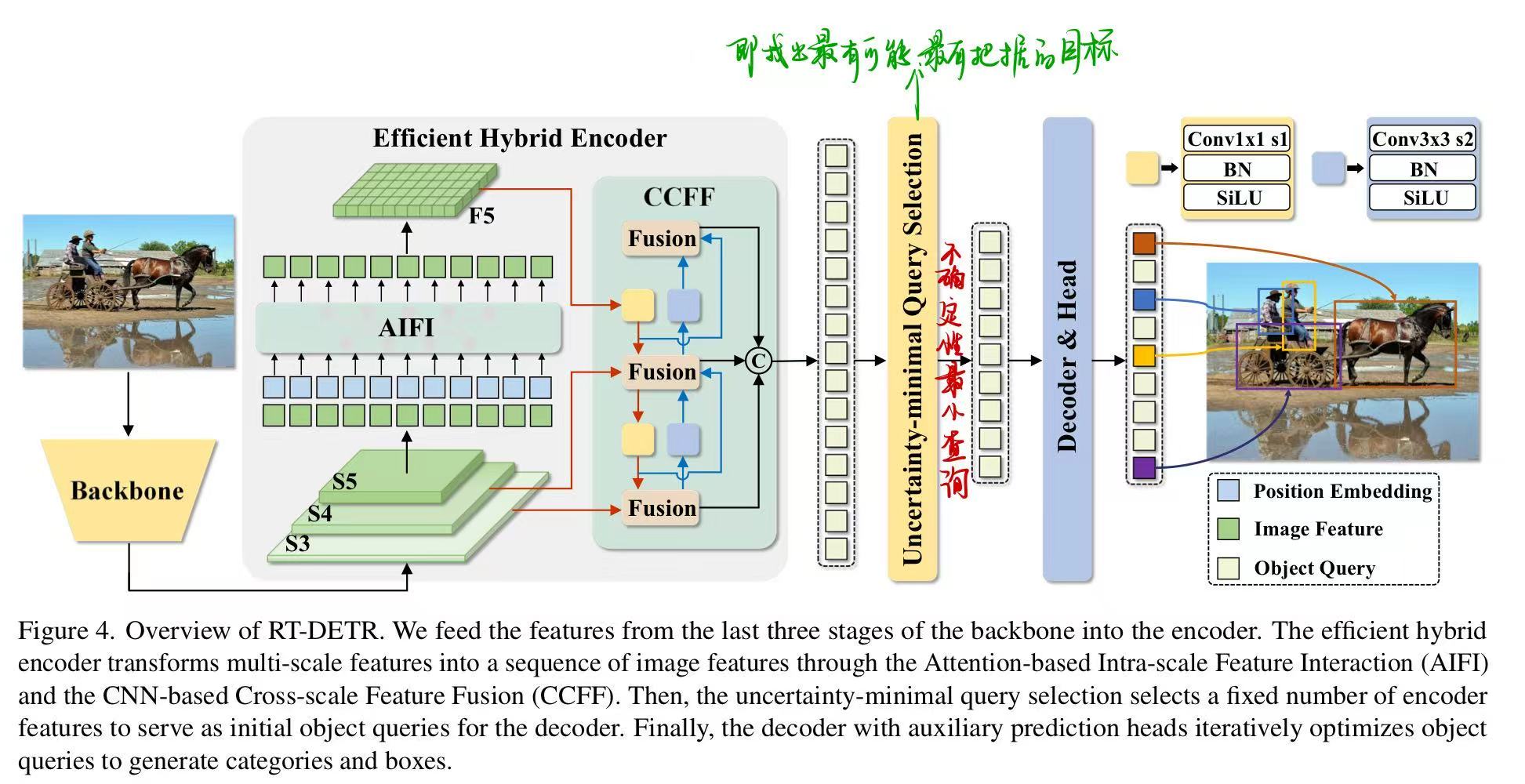
RT-DETR由一个骨干网络、一个高效的混合编码器以及一个带有辅助预测头的Transformer解码器组成
步骤:
- 将来自骨干网络最后三个阶段 ${S3, S4, S5}$ 的特征输入到编码器中。高效的混合编码器通过尺度内特征交互和跨尺度特征融合将多尺度特征转换为图像特征序列。
- 随后,采用不确定性最小查询选择来选择固定数量的编码器特征,作为解码器的初始对象查询。
- 最后,带有辅助预测头的解码器迭代地优化对象查询,以生成类别和边界框。
📌 关键词解释:
解耦尺度内交互:每个尺度(即像素)内部,先高效地把该尺度的空间信息吃透。
跨尺度融合:让不同的尺度之间交换信息,补齐大目标、小目标的互补感知。
二、创新点
1 混合编码器
📌 概念:它由两个模块组成,即基于注意力的尺度内特征交互(AIFI)和基于CNN的跨尺度特征融合(CCFF)。AIFI通过仅在$S_5$上使用单尺度Transformer编码器执行尺度内交互,从而在变体D的基础上进一步降低了计算成本。
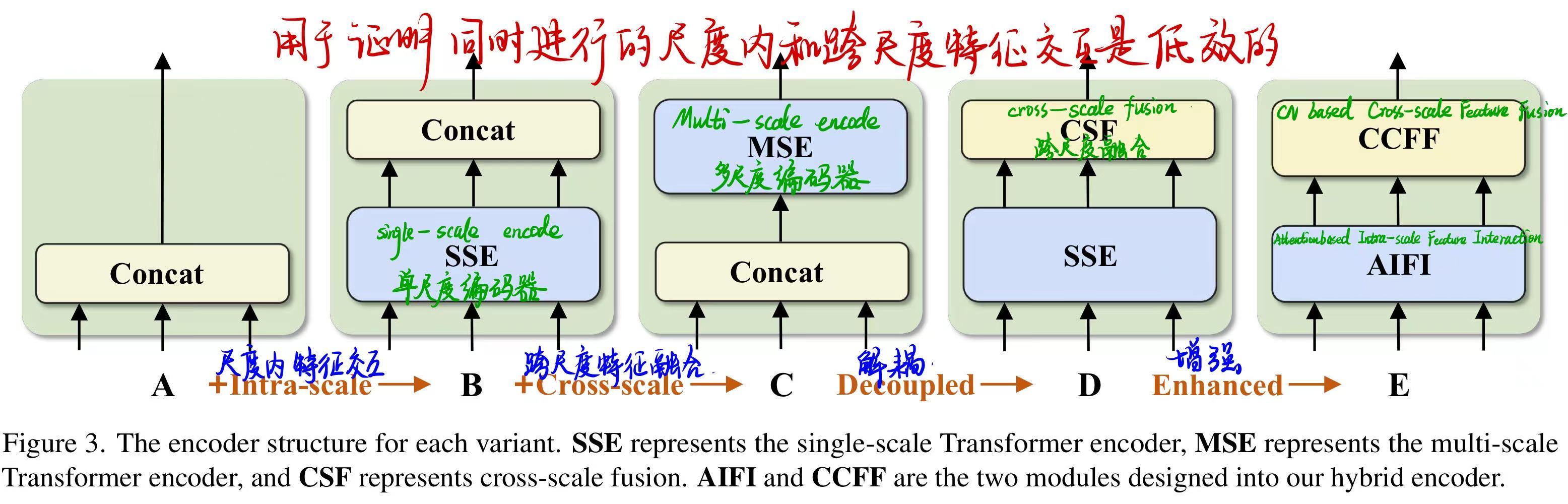
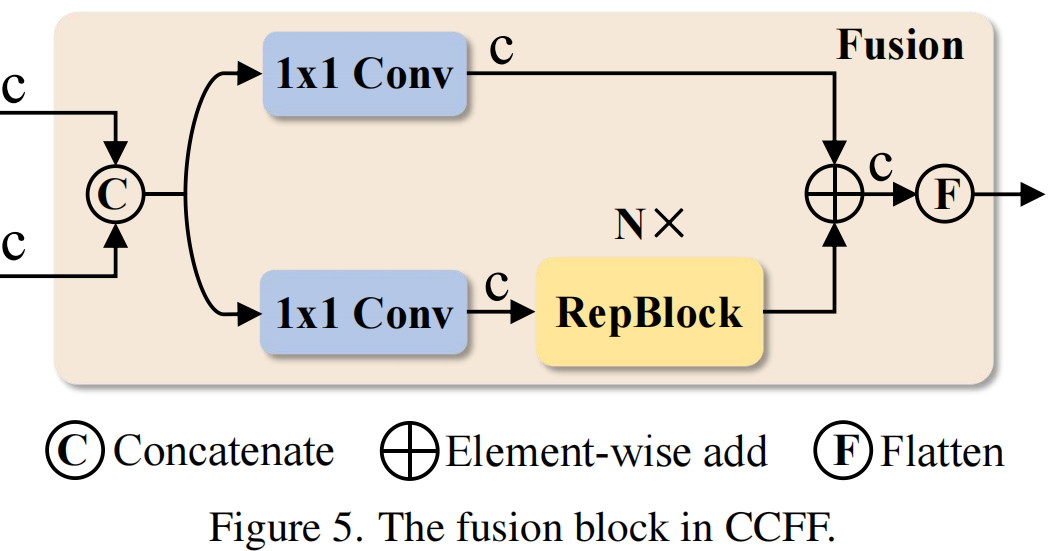
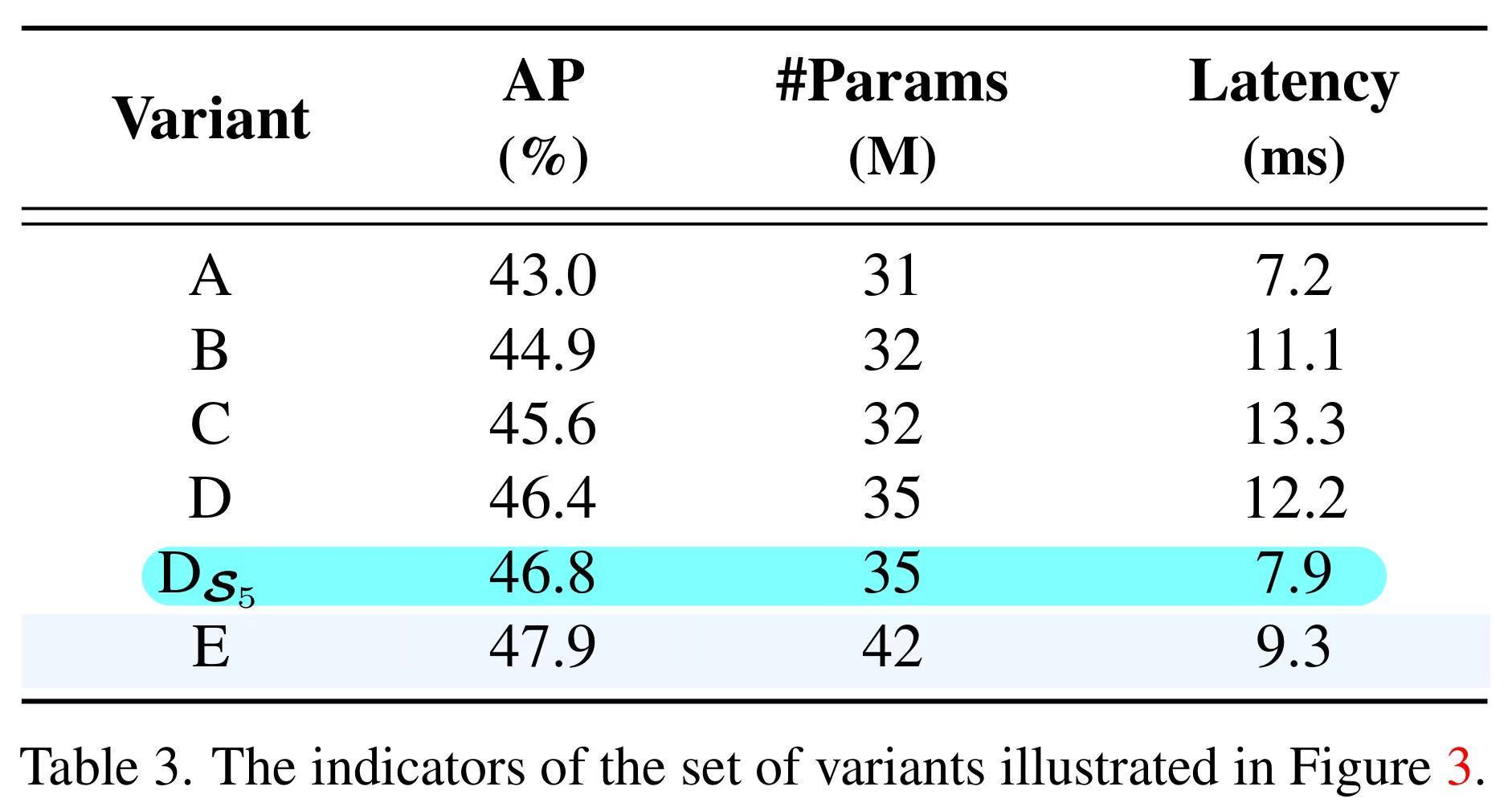
值得注意的是,由于缺乏语义概念以及存在与高层特征交互重复和混淆的风险,较低层特征的尺度内交互是不必要的。设计了仅在D$_{S5}$上执行了尺度内特征交互,如下图所示相较于D,AP提高了0.4%,速度响应大幅度提升。随后添加CCFF模块用于将两个相邻尺度的特征融合为一个新的特征。
2 不确定性最小化查询选择
2.1 概念
置信度分数从编码器中选择前K个特征来初始化对象查询(或仅位置查询)
👉 怎么理解:采用不确定性最小查询选择来选择固定数量的编码器特征?
1️⃣ 什么是「不确定性最小查询选择」?
📌 不确定性本质是:模型“有多拿不准这个位置是不是目标”
不确定性最小=从全图里,挑出最像目标、最不犹豫的那些点
2️⃣ 那「查询选择」具体在选什么?
📌 选的是编码器输出的 token(特征向量),这些被选中的token自带空间位置信息、自带语义信息、非随机。
3️⃣ 固定数量:这是为了 稳定 Decoder 的计算量,比如固定选中300个或100个
✅ 白话终极翻译
在编码器输出的所有位置特征中,先评估哪些位置最有可能对应真实目标,然后挑选出模型最有把握的、数量固定的那一小部分特征,把它们当作解码器用来检测目标的初始查询。
该模块要解决什么样子的问题?
当前的查询选择导致所选特征中存在相当程度的不确定性,从而导致解码器的次优初始化,并阻碍检测器的性能。即初始化的query不是最优的
2.2 公式
特征不确定性 $U$ 被定义为公式(2)中定位 $P$ 和分类 $C$ 的预测分布之间的差异。
为了最小化查询的不确定性,我们将不确定性整合到损失函数中,以便在公式(3)中进行基于梯度的优化。

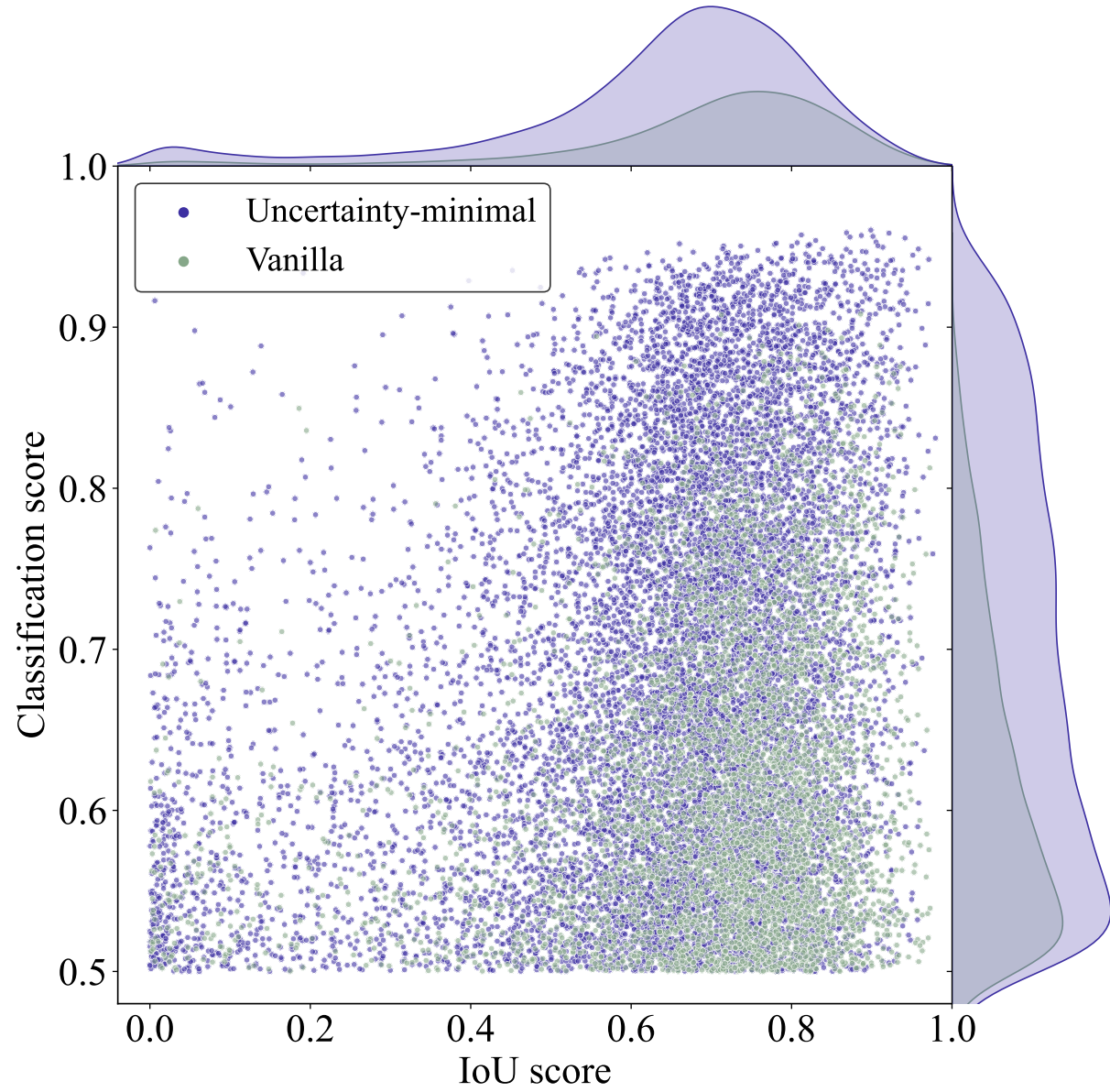
📌 如图6所示,论文绘制了分类得分大于0.5的散点图。紫色和绿色点分别代表从使用不确定性最小化查询选择和普通查询选择训练的模型中选择的特征。点越靠近图的右上角,对应特征的质量越高,即预测的类别和框越有可能描述真实对象。顶部和右侧的密度曲线反映了两种类型的点的数量。
3 结果比较
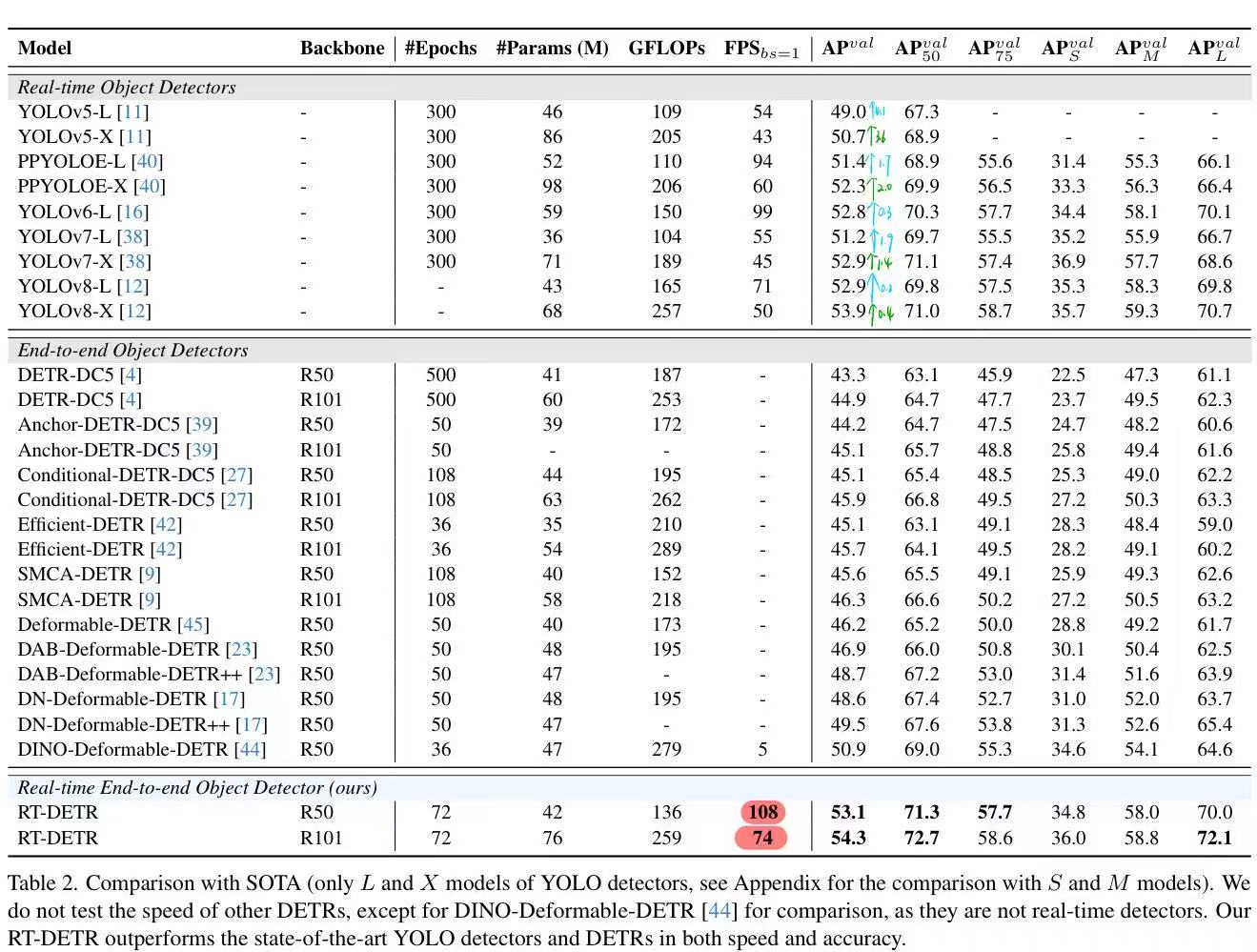
如下表所示,与SOTA的比较(仅YOLO检测器的L和X模型,与S和M模型的比较见附录)。我们没有测试其他DETR的速度,除了DINO-Deformable-DETR [44]用于比较,因为它们不是实时检测器。我们的RT-DETR在速度和准确性方面都优于最先进的YOLO检测器和DETR
三、论文收获
除了论文本身的收获之外,还有如下收获:
1 Object365
Object365可以作为一个更好的特征学习数据集,它包含超过60万张训练图像中的365个目标类别。用于诸如目标检测和语义分割等对定位敏感的任务,并且Object365更好的泛化能力已经在CityPersons、VOC分割和ADE任务上得到了验证。
2 单阶段和两阶段检测器
2.1 两阶段检测器(代表:Faster R-CNN)
典型流程:
1 | |
特点:
- 先找“可能是目标的区域”
- 再精细分类和回归
- 准确,但慢
eg:🎯 找人 → 确认身份
| 阶段 | 类比 |
|---|---|
| 第一阶段(RPN) | 在人群中圈出“像是人”的轮廓 |
| 第二阶段(精细分类) | 走近看:这是张三还是李四 |
| 第二阶段(精细回归) | 调整镜头:脸对齐、居中 |
2.2 单阶段检测器(代表:YOLO、SSD、RetinaNet)
典型流程:
1 | |
特点:
- 不生成候选框
- 一次前向传播完成检测
- 快,结构简洁
3 TensorRT FP16
用 TensorRT 将模型编译/优化成 FP16 推理引擎(可能用到 Tensor Core),然后在指定硬件上跑推理吞吐(FPS)或延迟(ms)基准测试。
4 写作
文献架构:Introduction、Related Work、前置条件统一、模型介绍、实验、局限性与讨论、结论
在做模型比较的时候尽量多维比较:统一模型大小的前提看精度、统一精度的前提看大小。还有比较不同层次的消融实验、不同的编码层、解码层等等一系列的。
另外比较的时候可以看看不同后处理阈值下的预测可视化。这样子能够看到模型预测结果的性能。
📌 eg.

