自然语言处理
一、Transformer
1 概念
Transformer是一种深度学习架构,它的核心思想是:
通过注意力机制(Attention)捕捉序列中不同部分之间的关系,而不是像以前的模型(如 RNN)那样一步步按顺序处理。
Transformer 的特点
- 并行计算:不像 RNN 需要一步步计算,Transformer 可以同时处理所有输入。
- 捕捉长距离依赖:通过注意力机制,Transformer 可以轻松捕捉序列中相隔很远的部分之间的关系。
- 扩展性强:Transformer 可以堆看很多层,形成超大的模型。
2 架构
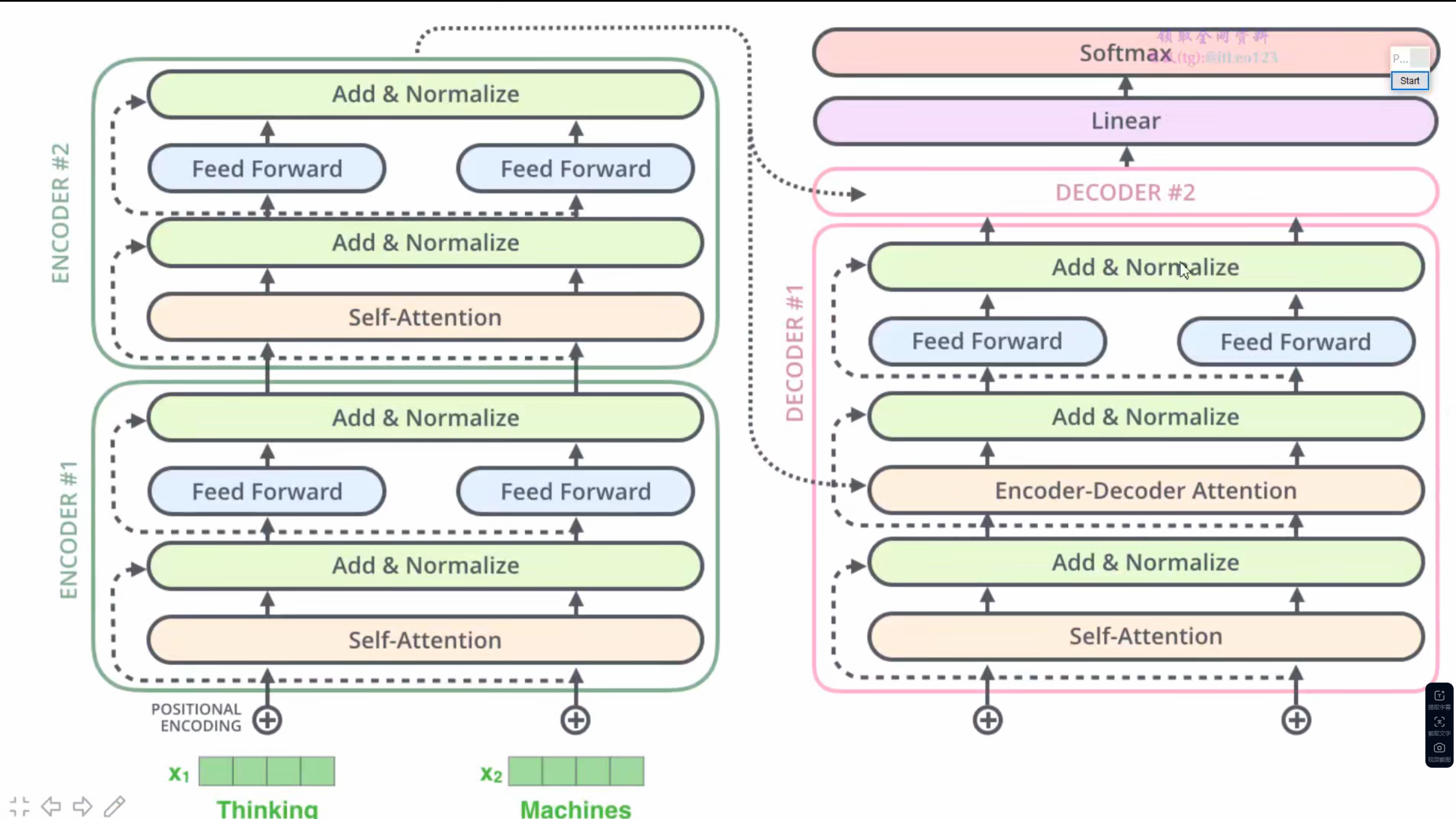
正则化
在 Transformer 中使用的是 Layer Normalization,而非 Batch Normalization。
相同点:
两者都属于归一化方法,目的是提升模型训练的稳定性与效率。
区别:
BatchNorm 通常用于计算机视觉领域,对每个通道在 batch 维度上进行归一化,适合定长输入;而 LayerNorm 是对每个样本的特征维度进行归一化,适应性强,不依赖 batch 大小,特别适合 NLP 中的变长输入和 Transformer 架构。
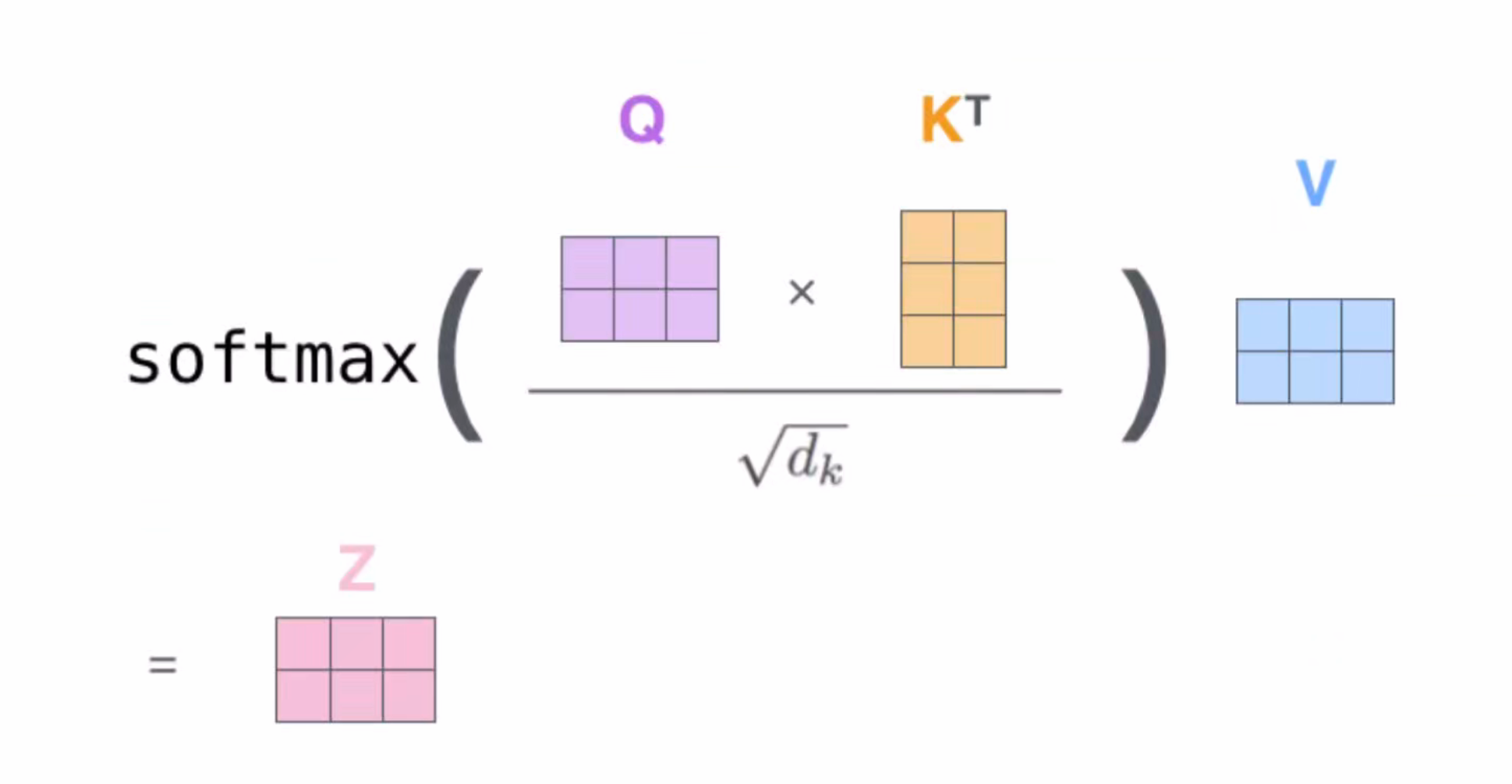
缩放点积注意力机制
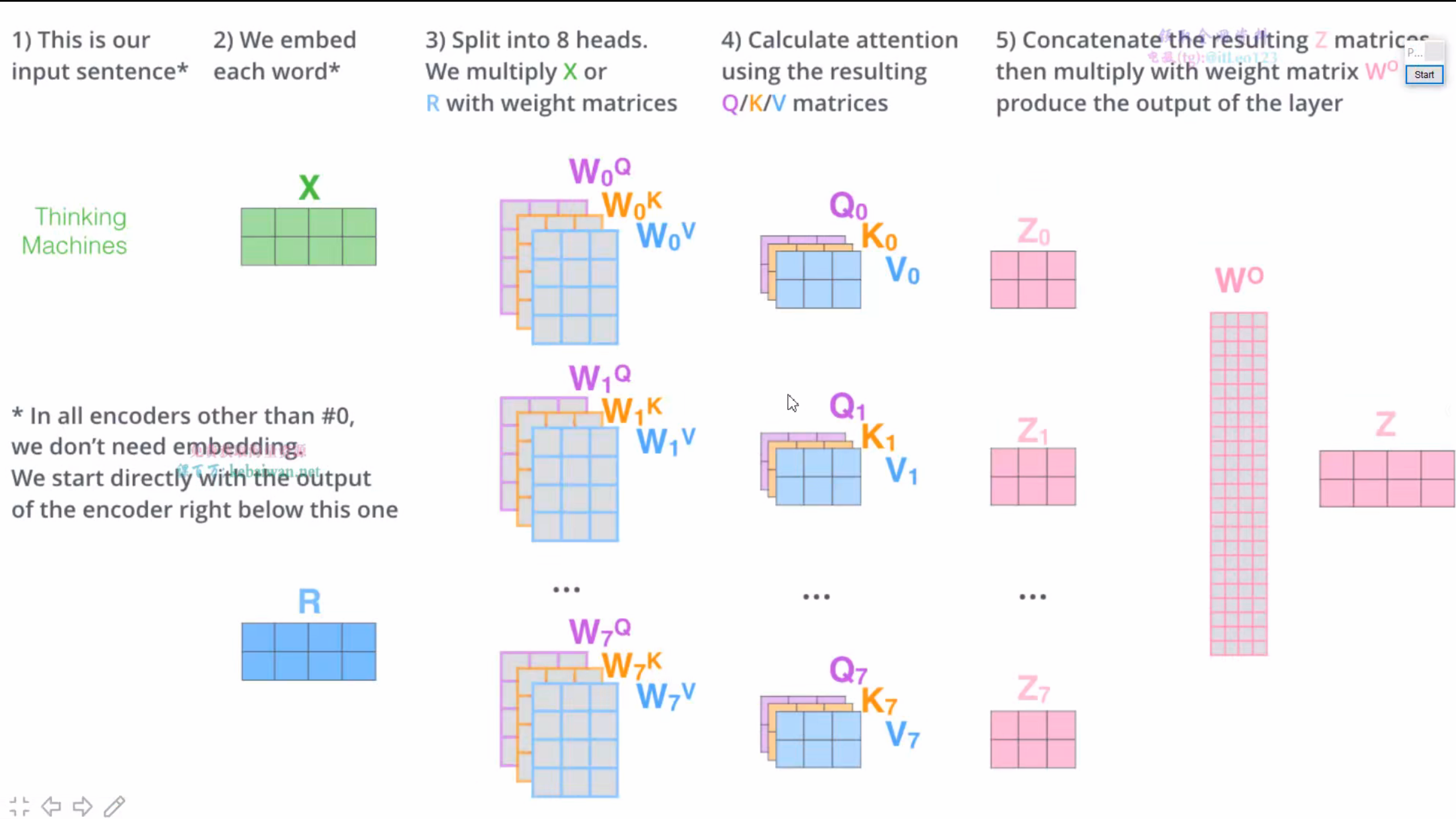
多头注意力机制
Decoder
train的时候并行化
Inference的时候仍要序列式完成
Self-attention时前词不能见后词
- Mask来实现
2 技术
word2vec
优点:快,计算量小,cpu上就能跑
缺点:全局信息不足,多义词问题未解决
自然语言处理
http://example.com/2025/07/09/自然语言处理/