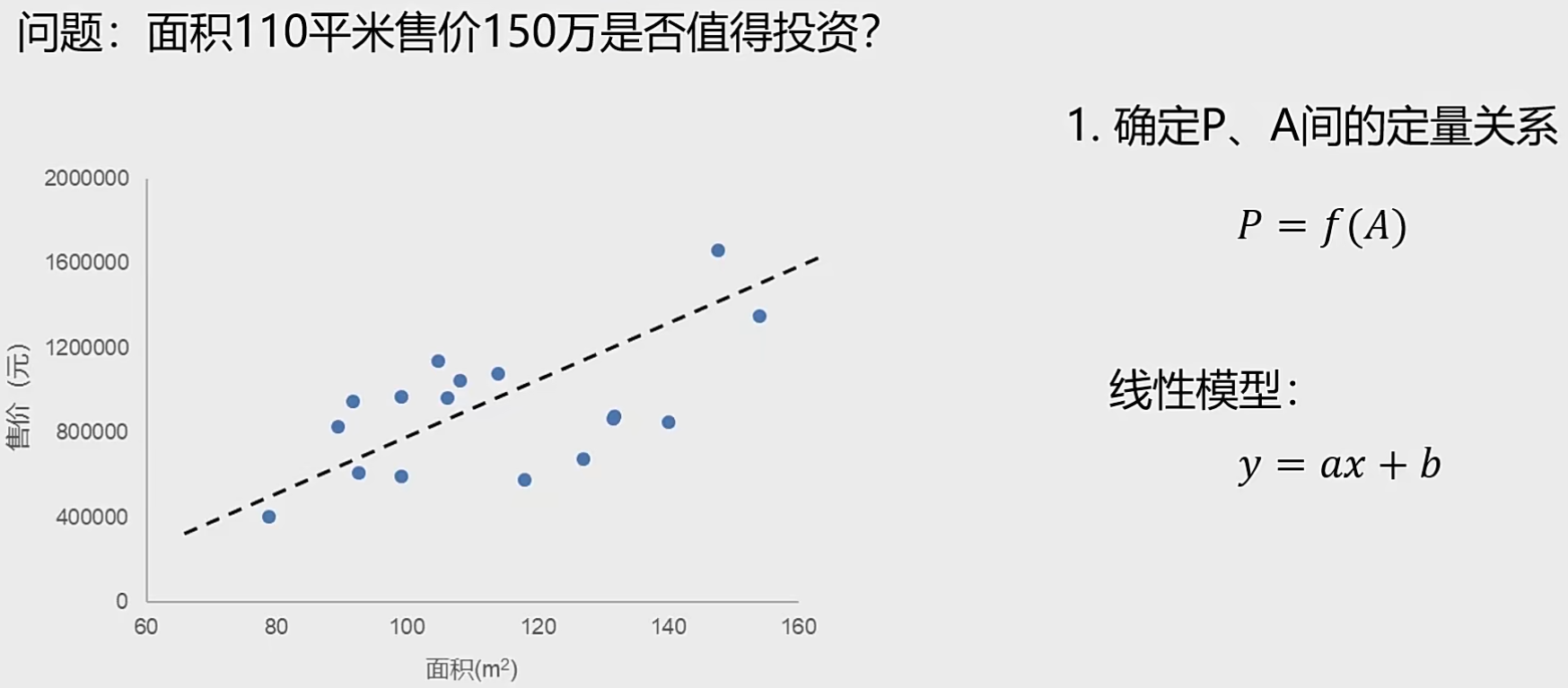
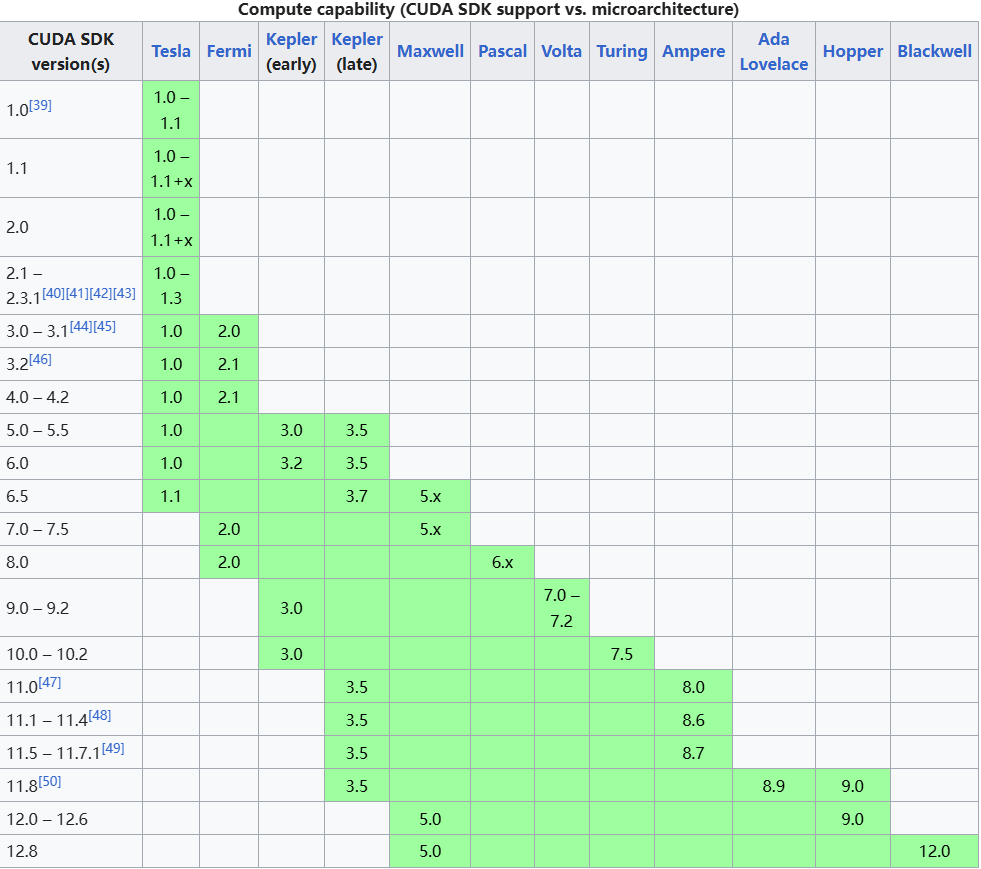
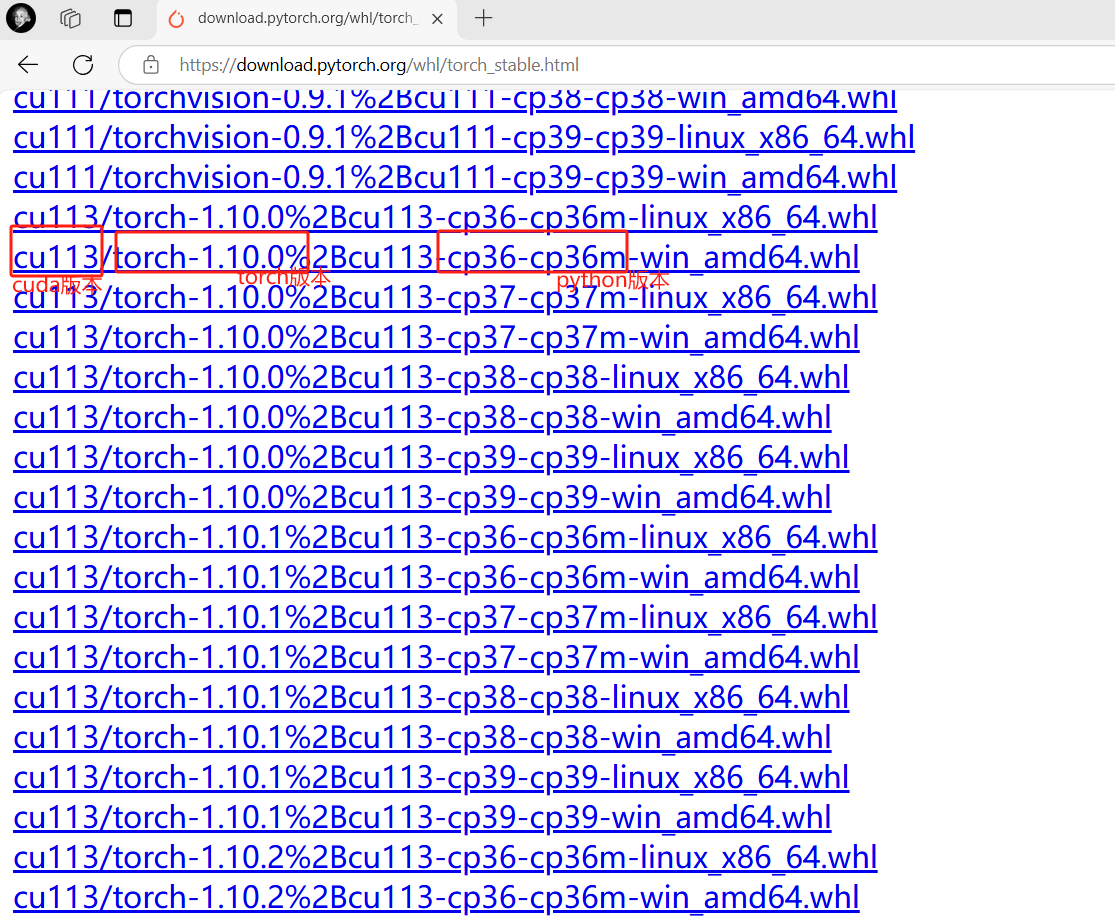
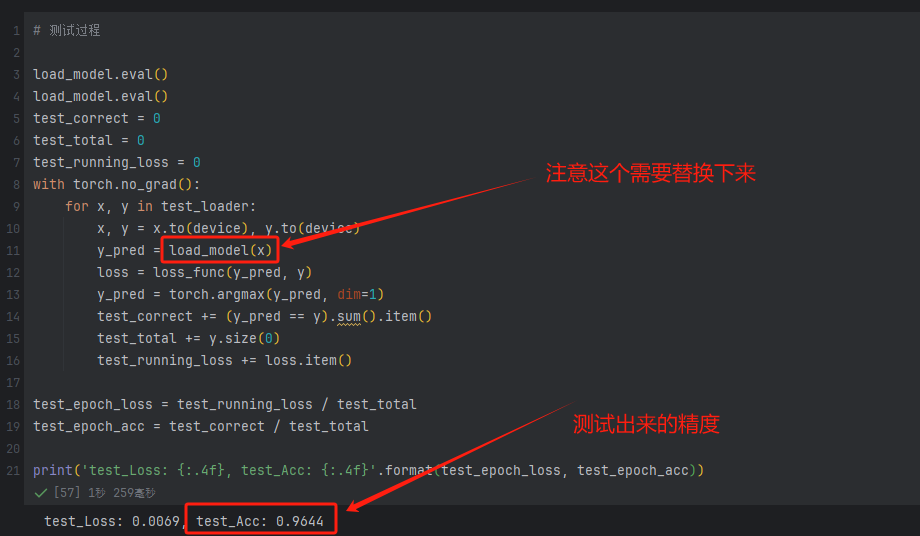
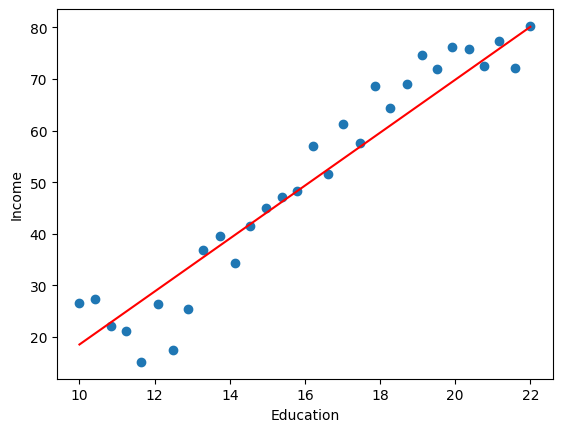
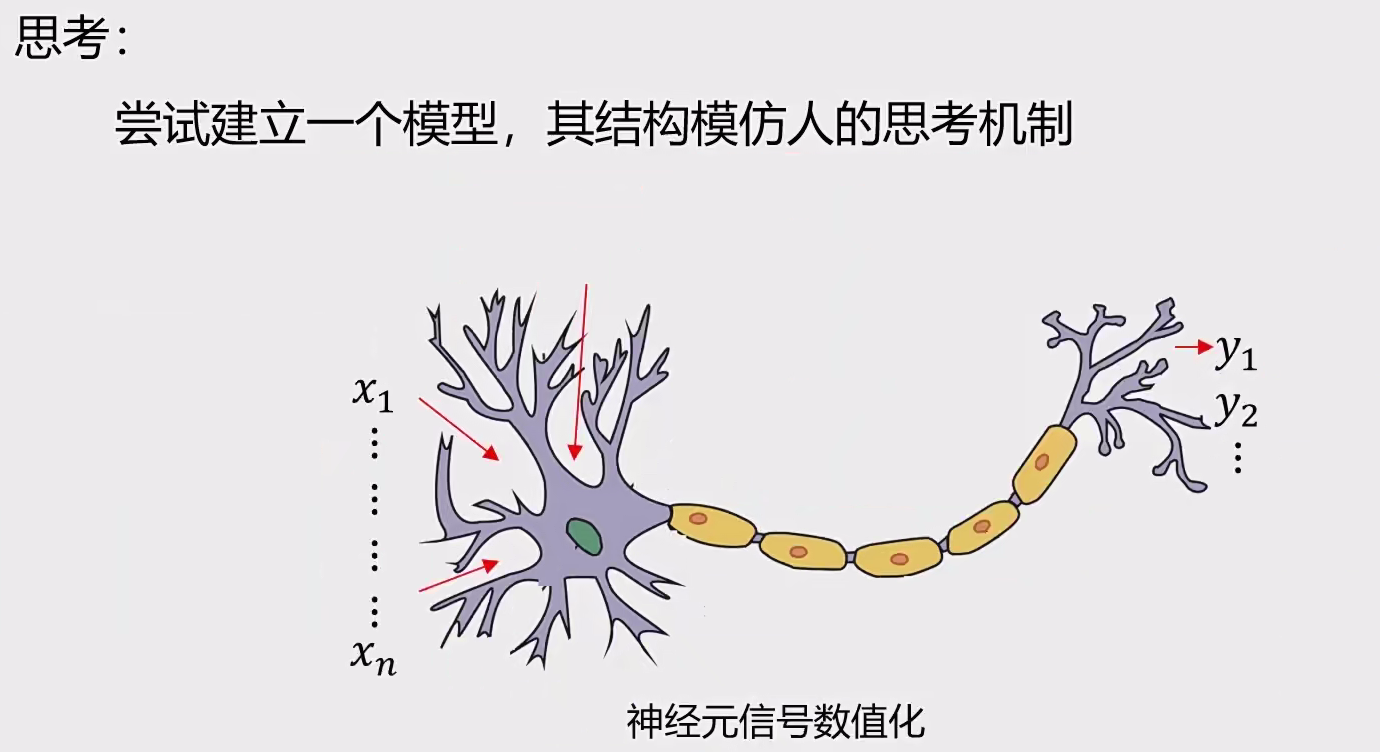
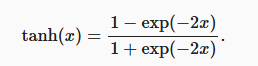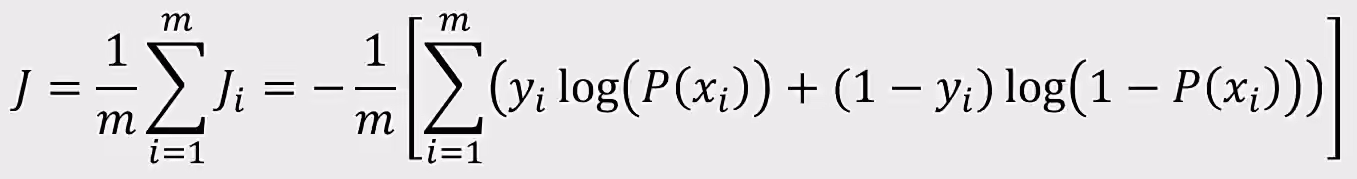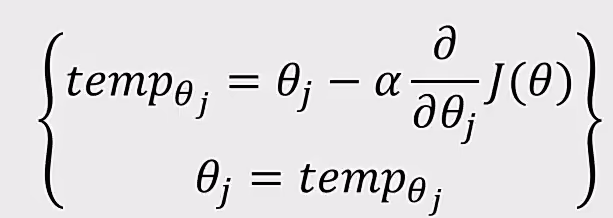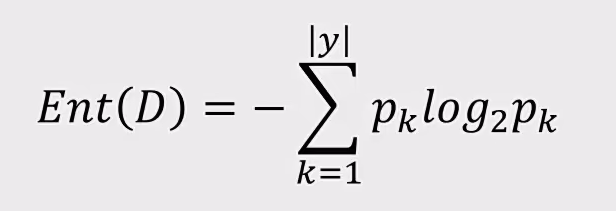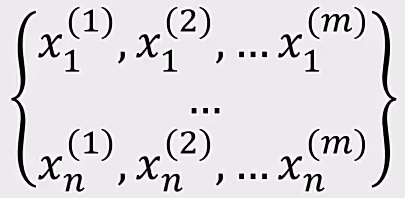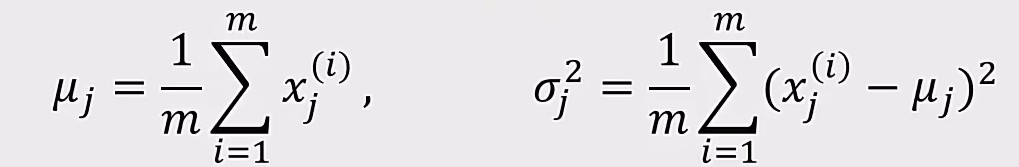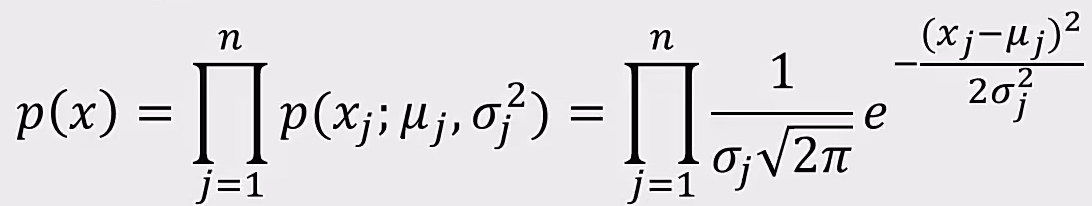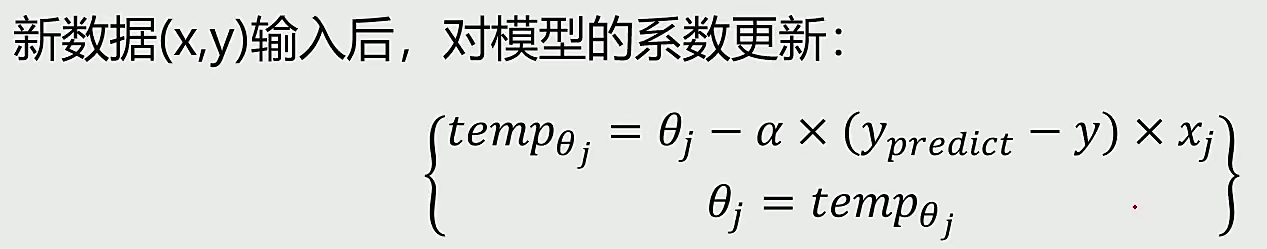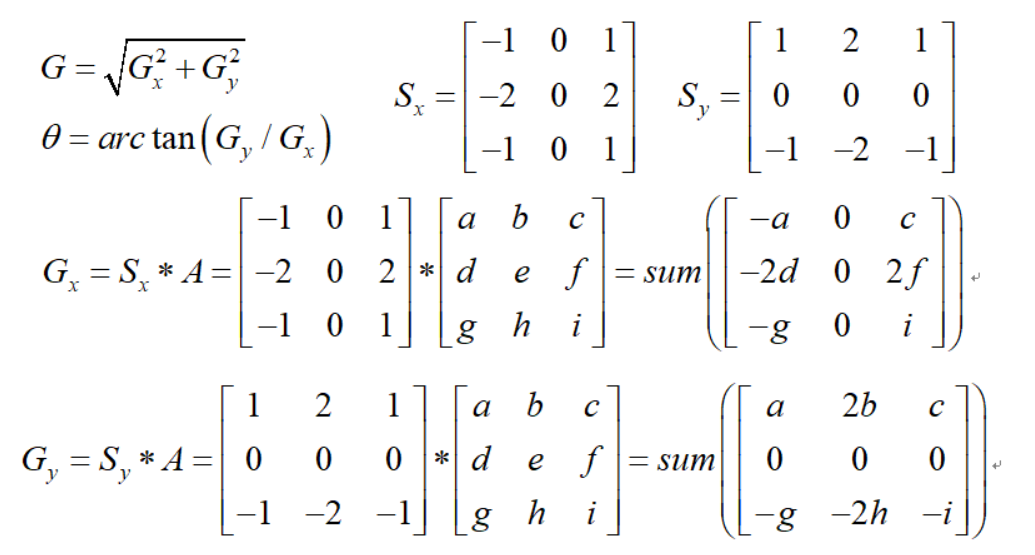一 相关概念 1 什么是机器学习 机器学习定义:让计算机在没有明确编程的情况下学习的研究领域。(从数据中寻找规律、建立关系,根据建立的关系去解决问题的方法,即从数据中学习并实现自我优化与升级)。
机器学习又分为分类任务、和回归任务。主要的区别在于分类可以理解为离散的点 ,而回归任务是连续的线 。
机器学习、深度学习、人工智能的关系
机器学习是实现人工智能的方法,深度学习是一种实现机器学习的技术
2 科学计算库 2.1 numpy 概念:NumPy(Numerical Python)是Python的一种开源的数值计算扩展。提供多维数组对象,各种派生对象(如掩码数组和矩阵),这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库,包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数基本统计运算和随机模拟等等。
会把其中元素转换成相同的类型。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1 ,2 ,3 ,4 ,"5" ]print (ala_list)1 ,10 ,10 )1 ,10 ,num=10 , base=2 )"./arr1" , arr1)"./arr1.npy" )"./arr1.txt" , X=arr1, delimiter="," , fmt="%0.5f" )
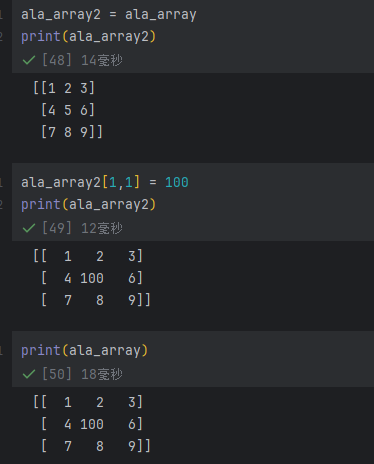
array当中数值不是赋值,而是将其地址指向前一个,如果不想影响应当使用copy
2.2 Pandas
其他正常操作即可,注意merge操作可以合并两个表,同时可以选择按照左边或右边为基准
1 pd.set_option('display.precision' , 5 )
2.3 Keras Keras是一个用Python编写的用于神经网络开发的应用接调用开接口可以实现神经网络、卷积神经网络、循环神经网络等常用深度学习算法的开发。Keras为用户提供了一个易于交互的外壳,方便进行深度学习的快速开发。
特点:
集成了深度学习中各类成熟的算法,容易安装和使用,样例丰富教程和文档也非常详细
能够以 TensorFlow,或者 Theano 作为后端运行
Keras or Tensorflow:
Tensorflow 是一个采用数据流图,用于数值计算的开源软件库可自动计算模型相关的微分导数:非常适合用于神经网络模型的求解。
Keras可看作为tensorflow封装后的一个接口(Keras作为前端TensorFlow作为后端)。
2.4 Scikit-learn 概念:Python语言中专门针对机器学习应用而发展起来的一款开源框架(算法库),可以实现数据预处理、分类、回归、降维、模型选择等常用的机器学习算法。
特点:
优点:集成了机器学习中各类成熟的算法,容易安装和使用,样例丰富,教程和文档也非常详细
缺点:不支持Python之外的语言,不支持深度学习和强化学习
3 专业名词 3.1 准确率(精度)ACC/precision 精度Accuracy是指模型预测正确(包括真正例TP、真反例TN)的样本数与总体样本数的占比。
3.2 召回率 TPR/查全率Recall 正样本中,预测正确的比例。召回率高则说明漏检率低
精确率计算的是预测对的正样本在整个预测为正样本中的比重 预测对的正样本在整个真实正样本中的比重
3.3 特异度TNR 负样本中,预测正确的比例。特异度高则说明误诊率高
3.4 精确率PPV 被预测为正样本中有多少是正确的,精确率高则说明误检率低
3.5 F1分数 精确率和召回率的调和平均值,通常值越大越好
比如:
在涉及到严重事故如癌病检测的系统中,我们要注重召回率,越高越好,因为我们不希望有病的人被漏诊;
而对于垃圾邮箱检测系统来说,我们要注重精确度,越高越好,因为我们宁愿多看一封垃圾邮件,也不能错失一封重要的邮件;
再举个不太恰当的例子,比如对于刑事诉讼审判系统来说,我国司法机关偏向于高召回率,即天网恢恢疏而不漏绝不放过一个坏人;
而美国司法偏向于高精确率,即人权大于一切绝不冤枉一个好人;有时候很难说孰是孰非,更合理的做法便是提高F1分数。
3.6 P-R曲线 即精确率-召回率曲线,其中横轴是召回率(TPR),纵轴是精确率(PPV)。PR曲线实质上是通过设置不同的阈值,最终将一系列的点汇聚起来连成一条线。我们知道,通过设置不同的阈值我们所划分的正样本或负样本均有所不同,一般来说将大于阈值的样本划分为正样本,而小于当前阈值的样本划分为负样本。需要注意的是,PR曲线对正负样本的比例异常敏感,即当正负样本的分布发生变化时,PR曲线的形状会发生巨大的变化
3.7 Epoch、Batch以及Batch size Epoch(时期):
当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )
再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。
然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。
将整个训练样本分成若干个Batch。
每批样本的大小。
训练一个Batch就是一次Iteration(这个概念跟程序语言中的迭代器相似)
防止模型训练过拟合
3.7 AP AP是PR曲线下面积的近似值,计算方式因任务和数据集标准不同而有所差异。
计算方法:
全点插值法(COCO标准)
11点插值法(PASCAL VOC标准)
3.8 mAP mAP,即平均精度均值,是目标检测任务中常用的性能评估指标。在目标检测中,我们不仅要判断图像中是否存在某个目标,还需要定位目标的位置。因此,评估指标需要综合考虑分类和定位的准确性。mAP结合了精确率和召回率,能够全面评估模型的性能
3.9 交并比IoU IoU 度量两个边界之间的重叠,越大越好
3.10 均方误差(MSE) y’和y的均方误差(MSE):$MSE=\frac{1}{m}\sum\limits_{i=1}^{n}(y’{i}-y_{i})^2$
R方值($R^2$):$R^2=1-\frac{limits_{i=1}^{n}(y’{i}-y_{i})^2}{limits_{i=1}^{n}(y’{i}-\overline y_{i})^2} = 1 - \frac{MSE}{方差}$
MSE越小越好, ${R^2}$分数越接近1越好
y’ vs y集中度越高越好(越接近直线分布)
3.11 梯度 这样几乎就没有梯度信号通过神经元传递到前面层的梯度更新中,因此这时前面层的权值几乎没有更新,这就叫梯度消失。
3.12 正则化 正则化(Regularization) 是一种防止模型过拟合(overfitting)的方法。它通过对模型的损失函数增加额外的约束项,使模型在训练时不会对训练数据“记得太牢”,从而提升在新数据上的泛化能力。
4 过拟合与欠拟合
模型不合适,导致其无法对数据实现有效预测。
过拟合 是指模型在训练集上表现很好,但在测试集上表现很差,原因是模型太复杂,学到了训练数据中的“噪声”。
原因:
模型结构过于复杂(维度过高)
解决办法:
简化模型结构(比如线性模型,使用低阶模型)
数据预处理,保留主成分信息(数据PCA处理)
在模型训练时,增加正则化项(regularization)
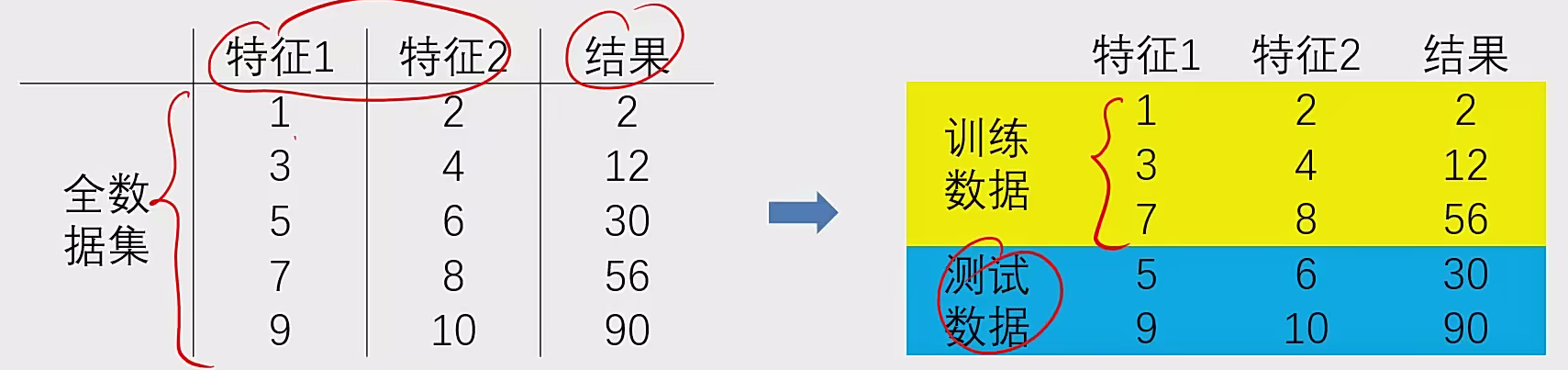
5 数据分离与混淆矩阵 数据分离:
1、把数据分成两部分:训练集、测试集
混淆矩阵:
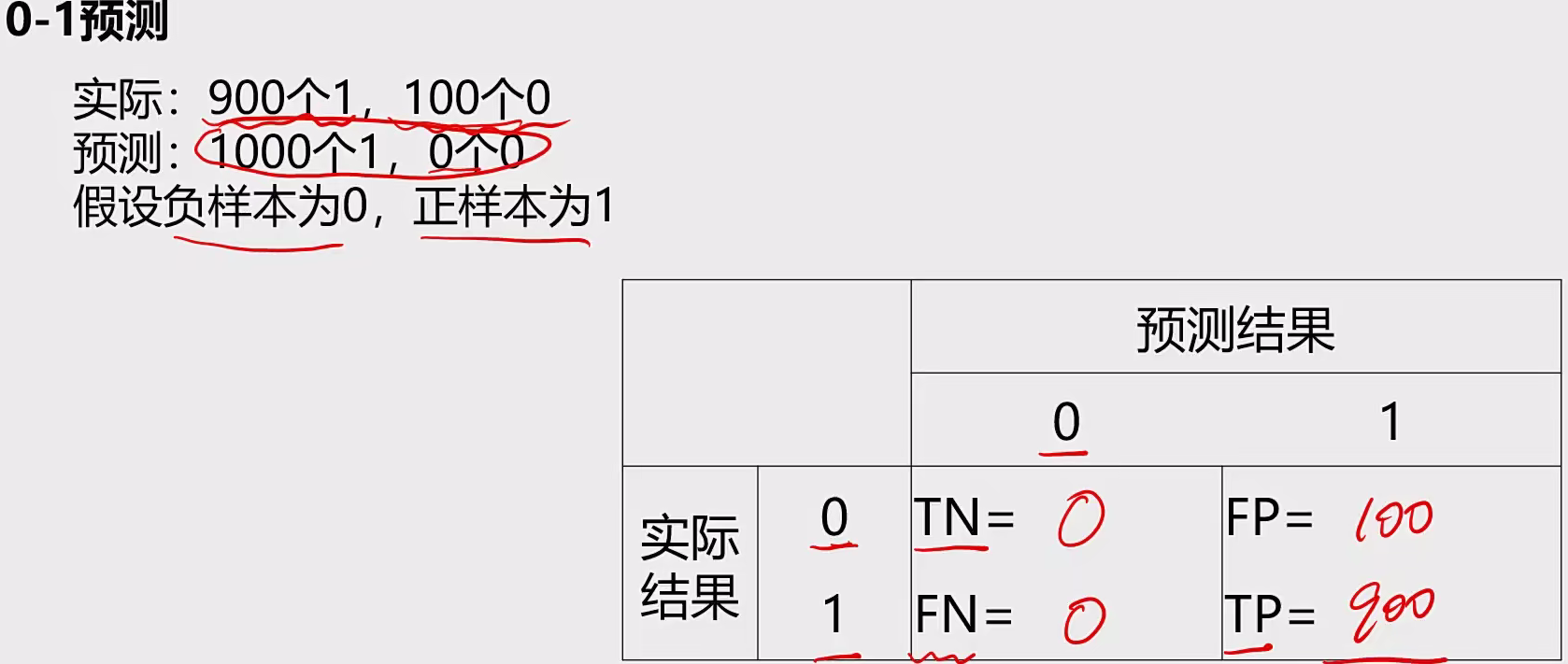
概念:又称为误差矩阵、用于衡量分类算法的准确程度。
●True Positives(TP):预测准确、实际为正样本的数量(实际为1,预测为1),真阳性
●True Negatives(TN):预测准确、实际为负样本的数量(实际为0,预测为0),真阴性
●False Positives(FP):预测错误、实际为负样本的数量(实际为0,预测为1),假阳性
●False Negatives(FN):预测错误、实际为正样本的数量(实际为1,预测为0),假阴性
(预测结果正确或错误,预测结果为正样本或负样本)
指标特点:
分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息(TP\TN\FP\FN)
通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型
例子:
6 模型优化 数据的重要性:
检查:
1、数据属性的意义 ,是否为无关数据(查看是否能做PCA的主成分分析,如果可以就可降维处理)
2、不同属性数据的数量级差异性 如何
3、是否有异常数据
4、采集数据的方法 是否合理,采集到的数据是否有代表性
5、对于标签结果,要确保标签判定规则的一致性 (统一标准)
鲁棒性:系统或算法在面临输入错误、环境变化、噪声干扰、参数变化等不确定性和异常情况时,仍能保持其性能和稳定性的能力
模型优化:在确定模型类别后,如何让模型表现更好(三方面:数据、模型核心参数、正则化)
遍历核心参数组合,评估对应模型表现(比如:逻辑回归边界函数考虑多项式、KNN尝试不同的n_neighbors值)
7 常用激活函数 激活函数 (activation function)通过计算加权和并加上偏置来确定神经元是否应该被激活, 它们将输入信号转换为输出的可微运算。 大多数激活函数都是非线性的。 由于激活函数是深度学习的基础,下面简要介绍一些常见的激活函数。
激活函数,并不是去激活什么,而是指如何把”激活的神经元的特征”通过函数把特征保留并映射出来,即*负责将神经元的输入映射到输出端 。*
为何引入非线性的激活函数? ——如果不用激活函数,在这种情况下每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。因此引入非线性函数作为激活函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)
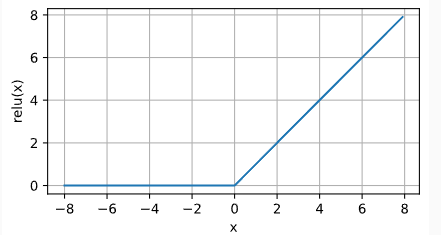
7.1 Relu 修正线性单元 (Rectified linear unit,ReLU ), 因为它实现简单,同时在各种预测任务中表现良好。 ReLU提供了一种非常简单的非线性变换。
公式:$ReLU(x)=max(x, 0)$ ,当输入为负时,ReLU函数的导数为0,而当输入为正时,ReLU函数的导数为1。 注意,当输入值精确等于0时,ReLU函数不可导。 在此时,我们默认使用左侧的导数,即当输入为0时导数为0。 我们可以忽略这种情况,因为输入可能永远都不会是0。
**引入ReLu的原因?**它求导表现得特别好:要么让参数消失,要么让参数通过。
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大 ,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失 的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
第三,ReLu会使一部分神经元的输出为0,这样就造成了网络的稀疏性 ,并且减少了参数的相互依存关系,缓解了过拟合 问题的发生。
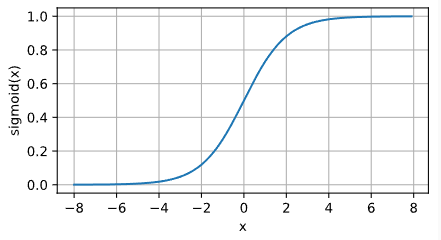
7.2 sigmoid 对于一个定义域在R中的输入, sigmoid函数 将输入变换为区间(0, 1)上的输出。 因此,sigmoid通常称为挤压函数 (squashing function)$sigmoid(x)=\frac{1}{1+e^{-x}}$
阈值单元在其输入低于某个阈值时取值0,当输入超过阈值时取值1。
适用范围:
Sigmoid 函数的输出范围是 0 到 1。非常适合作为模型的输出函数用于输出一个0~1范围内的概率值,比如用于表示二分类的类别或者用于表示置信度。梯度平滑,便于求导,也防止模型训练过程中出现突变的梯度
缺点:
容易造成梯度消失。我们从导函数图像中了解到sigmoid的导数都是小于0.25的,那么在进行反向传播的时候,梯度相乘结果会慢慢的趋向于0。除此之外,为了防止饱和,必须对于权重矩阵的初始化特别留意。如果初始化权重过大,可能很多神经元得到一个比较小的梯度,致使神经元不能很好的更新权重提前饱和,神经网络就几乎不学习。
函数输出不是以 0 为中心的,梯度可能就会向特定方向移动,从而降低权重更新的效率
Sigmoid 函数执行指数运算,计算机运行得较慢,比较消耗计算资源。
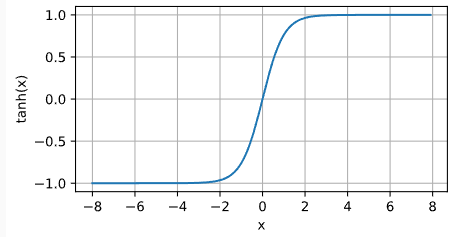
7.3 Tanh 与sigmoid函数类似, tanh(双曲正切)函数也能将其输入压缩转换到区间(-1, 1)上。 tanh函数的公式如下:
适用范围
tanh 的输出间隔为 1,并且整个函数以 0 为中心,比 sigmoid 函数更好;
在 tanh 图中,负输入将被强映射为负,而零输入被映射为接近零。
缺点:
二 相关模型 1 相关技术 1 组成成分分析PCA 1 基本概念 数据降维:
数据降维,是指在某些限定条件下,降低随机变量个数,得到一组”不相关“主变量的过程。
减少模型分析数据量,提升处理效率,降低计算难度;
PCA(principal components analysis):数据降维技术中,应用最最多的方法
目标:寻找k(k<6)维新数据,使它们反映事物的主要特征,
核心:在信息损失尽可能少的情况下,降低数据维度
如何保留主要信息:投影后的不同特征数据尽可能分得开(即不相关)
如何实现?使投影后数据的方差最大,因为方差越大数据也越分散
计算过程:
原始数据预处理(标准化:u= 0,σ=1)
计算协方差矩阵特征向量、及数据在各特征向量投影后的方差
根据需求(任务指定或方差比例)确定降维维度k
选取k维特征向量,计算数据在其形成空间的投影
应用范围:
根据设备上传感器1与2的数据,自动监测设备异常工作状态
自动寻找图片中异常的目标
异常消费检测(商业)
劣质产品检测(工业)
缺陷基因检测(医疗)
2 代码实现
PCA实战task:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 import pandas as pd'iris_data.csv' )'target' , 'label' ], axis=1 )'label' ]from sklearn.neighbors import KNeighborsClassifierfrom sklearn.metrics import accuracy_score3 )from sklearn.preprocessing import StandardScalerprint (X_norm)'sepal length' ].mean()'sepal length' ].std()0 ].mean()0 ].std()print (x1_mean, x1_sigma)print (x1_norm_mean, x1_norm_sigma)from matplotlib import pyplot as plt20 , 5 ))121 )'sepal length' ], bins=100 )122 )0 ], bins=100 )print (X.shape)from sklearn.decomposition import PCA4 )print (var_ratio)15 , 5 ))1 , 2 , 3 , 4 ], var_ratio)1 , 2 , 3 , 4 ], ['PC1' , 'PC2' , 'PC3' , 'PC4' ])'Principle Components' )'Variance Ratio Of each PC' )2 )10 , 10 ))0 ][y == 0 ], X_norm[:, 1 ][y == 0 ])0 ][y == 1 ], X_norm[:, 1 ][y == 1 ])0 ][y == 2 ], X_norm[:, 1 ][y == 2 ])'setosa' , 'versicolor' , 'virginica' ])3 )
2 Xgboost 1 概念 本质上Xgboost还是一种决策树的集成算法
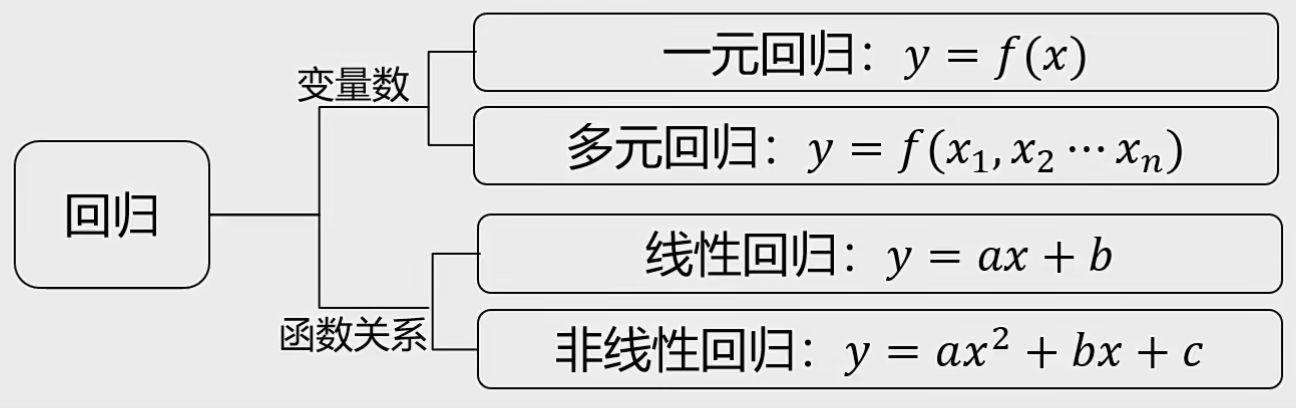
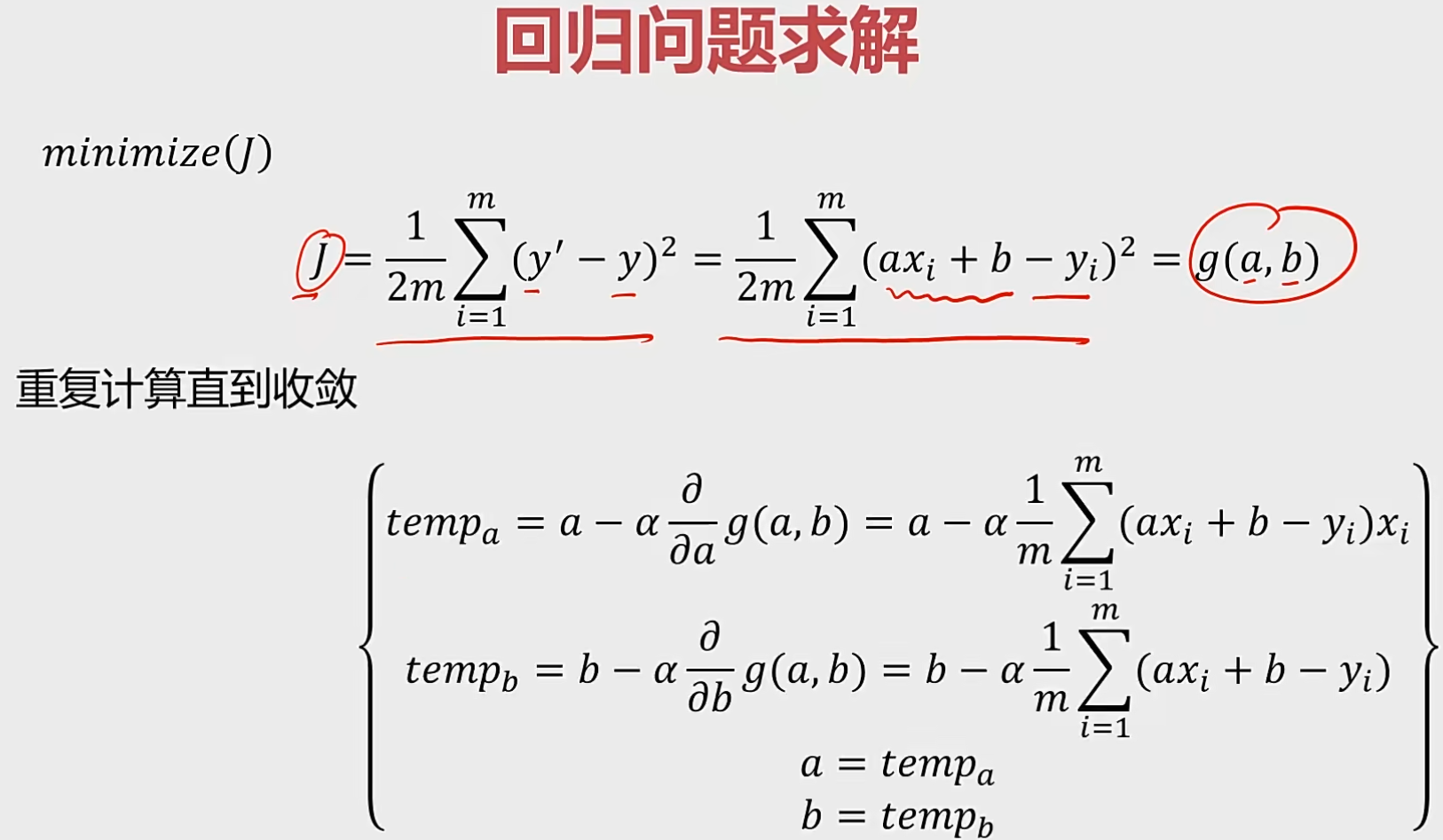
2 监督式学习 1 线性回归 1.1 概念 回归分析:根据数据,确定两种或两种以上变量间相互依赖的定量关系。
函数表达式:$f(x_{1},x_{2}…x_{n})$
相关分类:
求解步骤:
1.2 实现 1、使用:
1 2 3 4 5 6 7 8 9 10 11 12 from sklearn.linear modelimport LinearRegression
1 2 3 4 5 6 7 from sklearn.metrics import mean_squared_error,r2_socrefrom matplotlib import pyplot as plt')
2、图形展示
1 2 3 4 5 6 7 8 9 10 import matplotlib.pyplot as plt211 )212 )
步骤总结:
导入工具包:numpy(数据由1D转换为2D)、pandas(加载数据)、 pyplot(画图)
读取数据并设计关系图的分布:设计图的大小、多张图同时展示的分布
训练模型
训练数据的赋值,即加载X和y
X数据由1D转换为2D,np.array(X).reshape(-1,1)
用X,y加载并训练模型
模型训练好后,再用已有的数据预测,得到预测值
模型评估
sklearn的导入(from sklearn metrics import mean_squared_error,r2_score)
使用数据
画图呈现,plt.plot(X, y_predict, ‘r’)
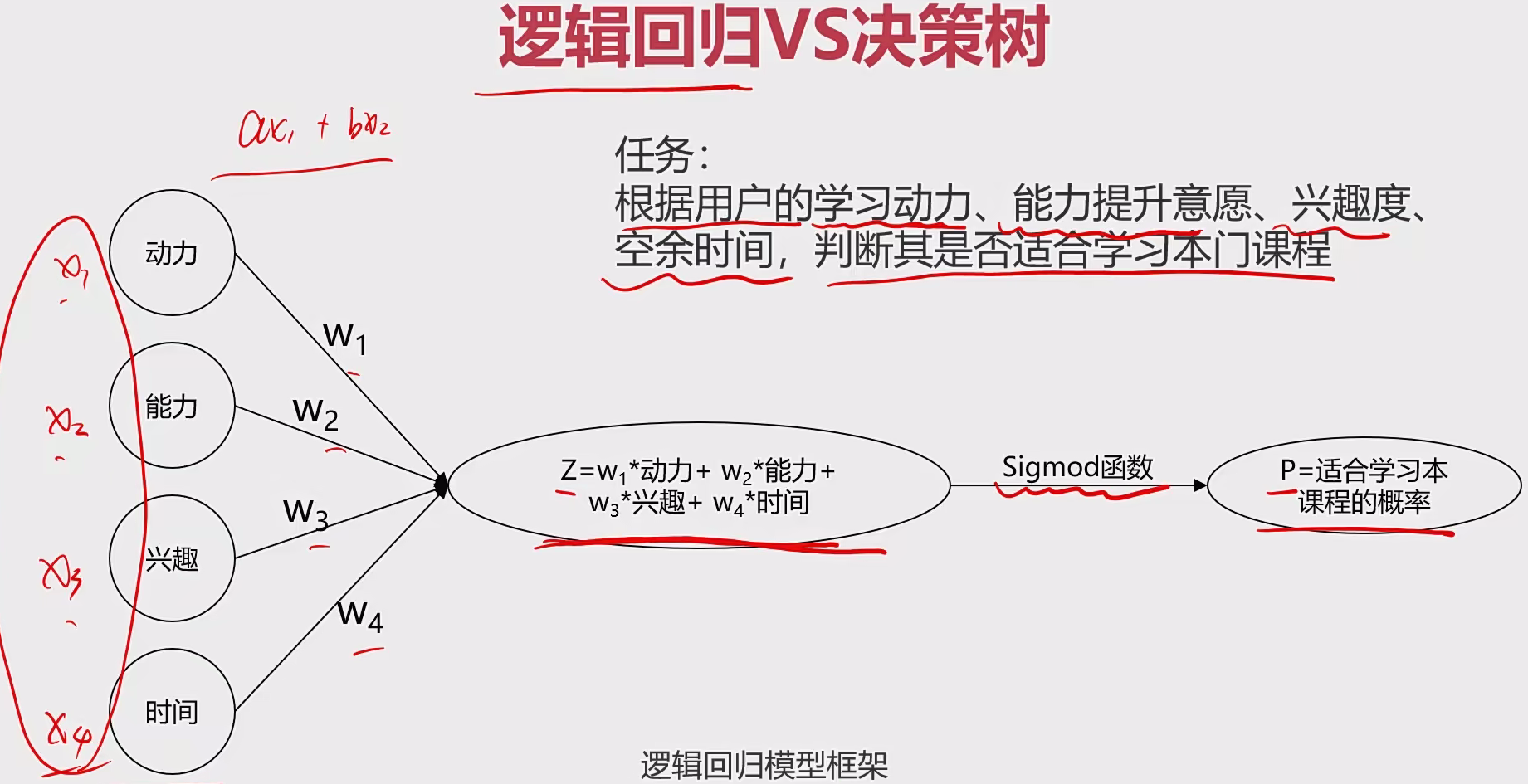
2 逻辑回归 2.1 基本概念 分类:根据已知样本的某些特征,判断新的样本属于哪种已知的样本类。
基本框架:$f(x)=\left{ \begin{aligned}y= f(x_{1},x_{2}…x_{n}) \ 判断为类别N,如果y = n\end{aligned} \right. $
分类方法:逻辑回归、KNN近邻模型、决策树、神经网络。
逻辑回归:用于解决分类问题的一种模型。根据数据特征或属性,计算其归属于某一类别的概率$P(X)$根据概率数值判断其所属类别。
主要应用场景:二分类问题。
逻辑公式(sigmoid):$P(x)=\frac{1}{1+e^{-g(x)}}$, g(x) = $\Theta_{0}+\Theta_{1}X_{1}+….$
$y=\left{ \begin{aligned}1, P(x)≥ 0.5 \ 1, P(x)< 0.5\end{aligned} \right. $,其中y为类别结果,P为概率分布函数,x为特征值
最小损失函数$J$:
$y=\left{ \begin{aligned}-log{P(x_{i})}, ify_{i}=1 \ -log(1-P(x_{i})), ify_{i}=0\end{aligned} \right. $
化简后:
求解:
sigmoid函数是指一种激活函数,该函数将输入值映射到(0,1)区间,常用于分类问题,尤其是二分类问题中作为逻辑回归的分类器。它的输出范围有限,优化稳定,便于求导,但存在梯度消失问题 ,即在输入值远离原点时,其导数接近于0,导致反向传播时权重更新缓慢。sigmoid函数在早期的神经网络中广泛使用,但随着ReLU等激活函数的出现,其在深层网络中的应用逐渐减少
2.2 实现步骤
导入工具包:numpy(数据由1D转换为2D)、pandas(加载数据)、 pyplot(画图)
读取数据
分类散点图及可视化
1 2 3 4 5 6 7 8 9 10 11 'Pass' ] == 1 8 , 8 ))'Exam1' ][mask], data.loc[:,'Exam2' ][mask])'Exam1' ][~mask], data.loc[:,'Exam2' ][~mask], marker='^' )'Exam1' )'Exam2' )'Exam1 - Exam2' )'Passed' , 'Failed' ])
整理数据集
1 2 3 4 5 X = data.drop(['Pass' ], axis=1 )'Pass' ]'Exam1' ].sort_values()'Exam2' ]
训练模型
1 2 3 4 5 6 7 8 9 10 11 12 'Pass' ], axis=1 )'Pass' ]'Exam1' ].sort_values()'Exam2' ]from sklearn.linear_model import LogisticRegression
模型训练好后,再用已有的数据预测,得到新数据集
1 2 3 print (y_predict)
模型评估
1 2 3 4 from sklearn.metrics import accuracy_scoreprint (accuracy)
拿到公式
1 2 3 4 5 6 7 0 ][0 ], LR.coef_[0 ][1 ]print (Theta0, Theta1, Theta2)
使用数据画图呈现,plt.plot(X, y_predict, ‘r’)
1 2 3 4 5 6 7 8 fig3 = plt.figure(figsize=(8 , 8 ))'Exam1' ][mask], data.loc[:,'Exam2' ][mask])'Exam1' ][~mask], data.loc[:,'Exam2' ][~mask], marker='^' )'Exam1' )'Exam2' )'Exam1 - Exam2' )'Passed' , 'Failed' ])
二阶边界模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 >print (accuracy2)import numpy as np0 ][0 ], LR2.coef_[0 ][1 ], LR2.coef_[0 ][2 ], LR2.coef_[0 ][3 ],LR2.coef_[0 ][4 ]print (Theta0, Theta1, Theta2, Theta3, Theta4, Theta5)2 2 - 4 * a * c)) / (2 * a)8 , 8 ))'Exam1' ][mask], data.loc[:,'Exam2' ][mask])'Exam1' ][~mask], data.loc[:,'Exam2' ][~mask], marker='^' )'Exam1' )'Exam2' )'Exam1 - Exam2' )'Passed' , 'Failed' ])
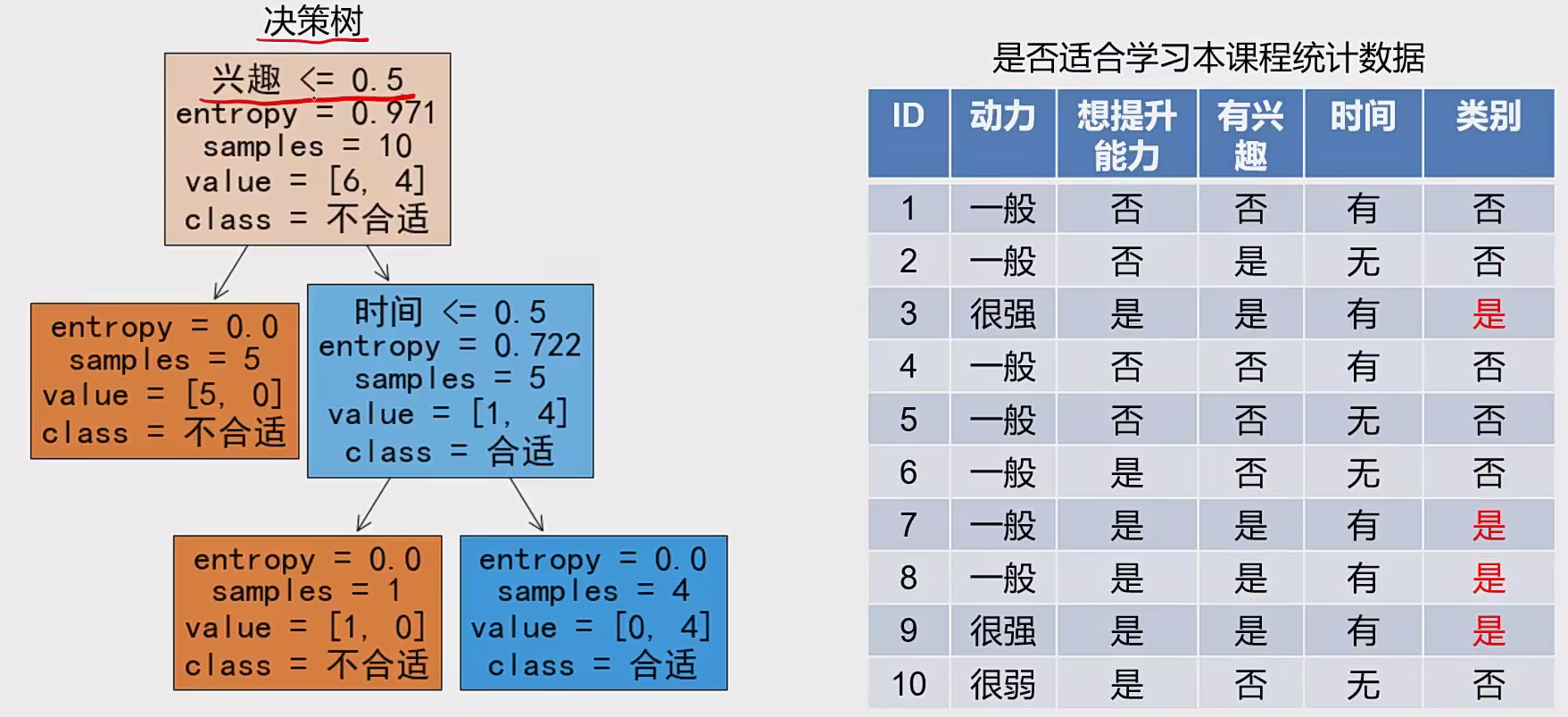
3 决策树 1 基本概念
决策树(Decision Tree):一种有监督对实例进行分类 的树形结构 ,通过多层判断 区分目标所属类别
本质:通过多层判断,从训练数据集中归纳出一组分类规则。
优点:
计算量小,运算速度快
缺点:
忽略属性间的相关性
求解:
三种求解方法:ID3、C4.5、CART
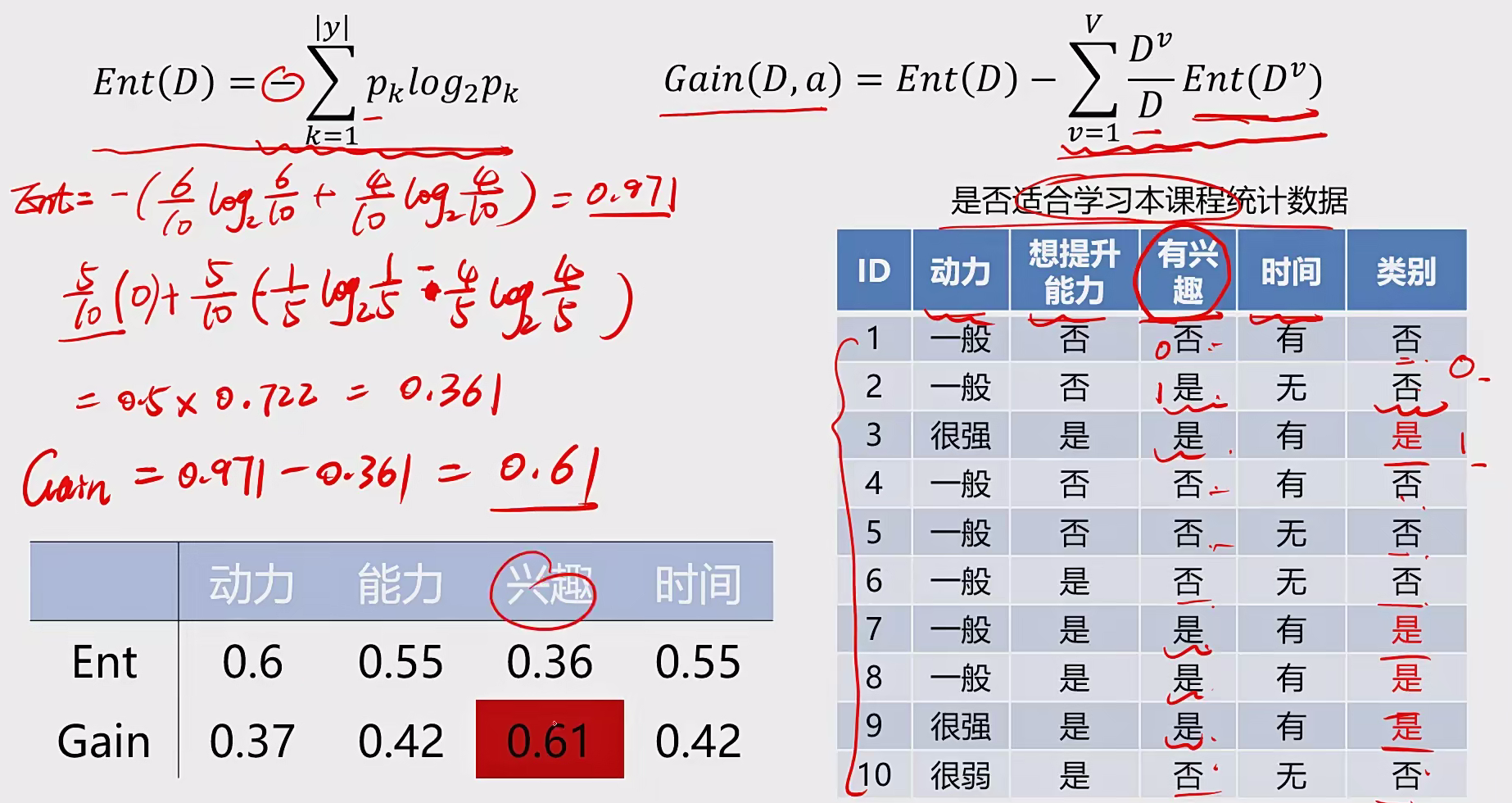
ID3:利用信息嫡 原理选择信息增益最大 的属性作为分类属性 ,递归地拓展决策树的分枝,完成决策树的构造
信息熵:
信息嫡(entropy)是度量随机变量不确定性的指标,商越大,变量的不确定性就越大。假定当前样本集合D中第k类样本所占的比例为$P_{k}$,亦则D的信息嫡为:
举例:
2 代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 import pandas as pdimport numpy as np'iris_data.csv' )'target' ,'label' ],axis=1 )'label' ]print (X.shape,y.shape)from sklearn import tree'entropy' ,min_samples_leaf=5 )from sklearn.metrics import accuracy_scoreprint (accuracy)from matplotlib import pyplot as plt20 ,20 ))'True' ,feature_names=['SepalLength' , 'SepalWidth' , 'PetalLength' , 'PetalWidth' ],class_names=['setosa' ,'versicolor' ,'virginica' ])'entropy' ,min_samples_leaf=10 )8 ,8 ))'True' ,feature_names=['SepalLength' , 'SepalWidth' , 'PetalLength' , 'PetalWidth' ],class_names=['setosa' ,'versicolor' ,'virginica' ])import matplotlib as mpl'family' : 'SimHei' ,'weight' : 'normal' ,'size' : 20 ,'font.family' ] = 'SimHei' 'axes.unicode_minus' ] = False 8 ,8 ))'True' ,feature_names=['花萼长' , '花萼宽' , '花瓣长' , '花瓣宽' ],class_names=['setosa' ,'versicolor' ,'virginica' ])'test.png' )
3 无监督学习 机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。
优点:算法不受监督信息(偏见)的约束,可能考虑到新的信息>A不需要标签数据,极大程度扩大数据样本。
主要应用 :聚类分析(应用最广)、关联规则、维度缩减。
聚类分析 概念:聚类分析又称为群分析,根据对象某些属性的相似度)将其自动化分为不同的类别。
1 K-Means聚类 1.1 基本概念
K-Means :以空间揪个点为中心进行聚类,对最靠近他们的对象归类,是聚类算法中最为基础但也最为重要的算法。
特点 :根据数据与中心点距离划分类别;基于类别数据更新中心点;重复过程直到收敛。
优点 :原理简单、实现容易、收敛快;参数少,方便使用
缺点 :必须设置簇的数量;随机选择初始类聚中心,结果可能缺乏一致性
公式:
算法流程:
1、选择聚类的个数k
2、确定聚类中心
3、根据点到聚类中心聚类确定各个点所属类别
4、根据各个类别数据更新聚类中心
5、重复以上步骤直到收敛(中心点不再变化)
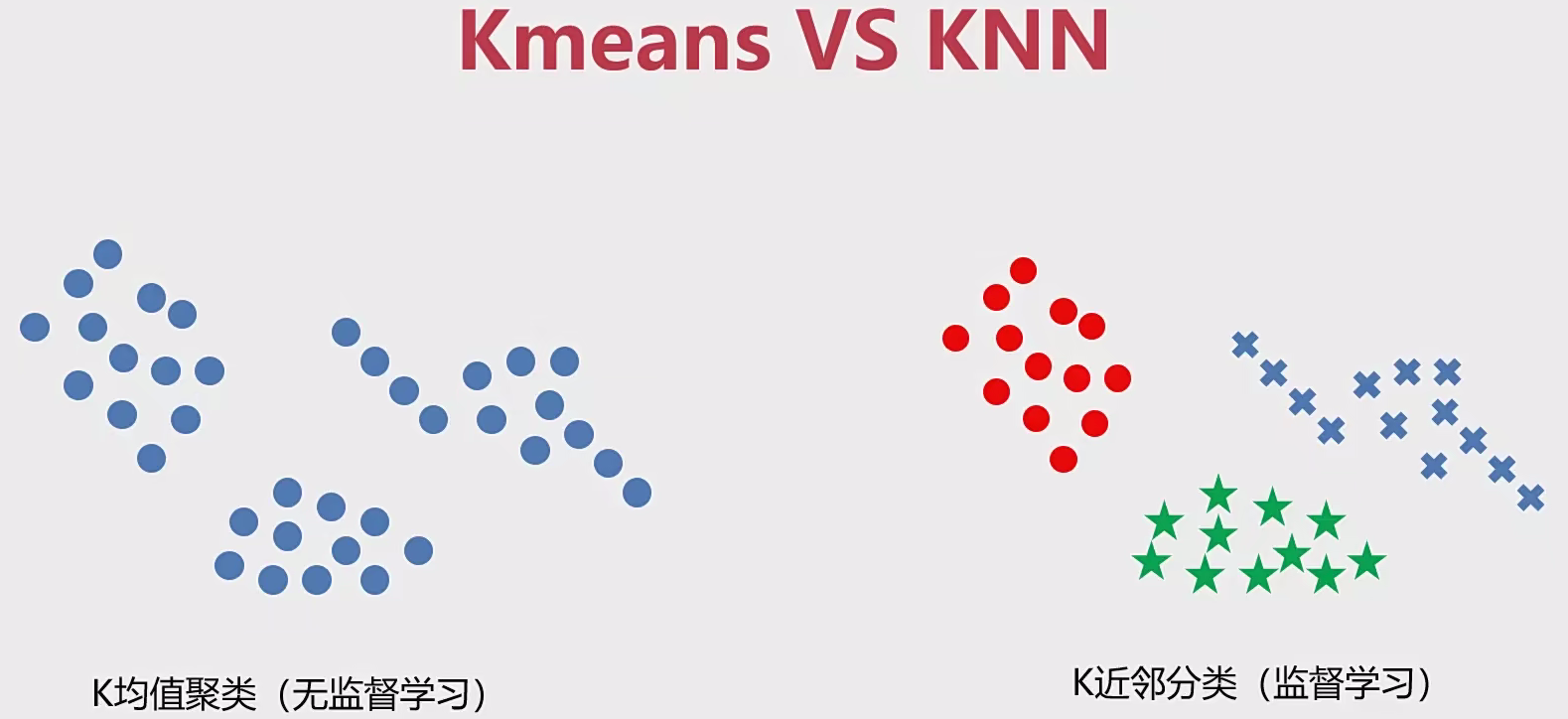
1.2 KNN和K-Means区别
KNN概念:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居),这K个实例的多数属于某个类,就把该输入实例分类到这个类中最简单的机器学习算法之一
KNN代码实现:
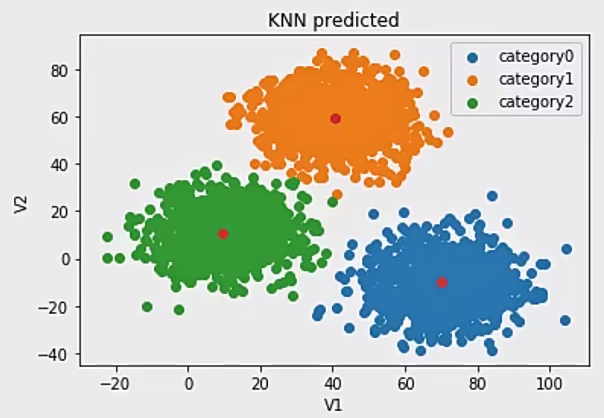
1 2 3 4 from sklearn.neighbors import KNeighborsClassifier3 )
1.3 实现代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 from sklearn.cluster imyport KMeans3 ,random _state = 0 )for i in y predict:if i == 0 :2 )elif i == 1 :1 )else :0 )print (y predict,y_cal)
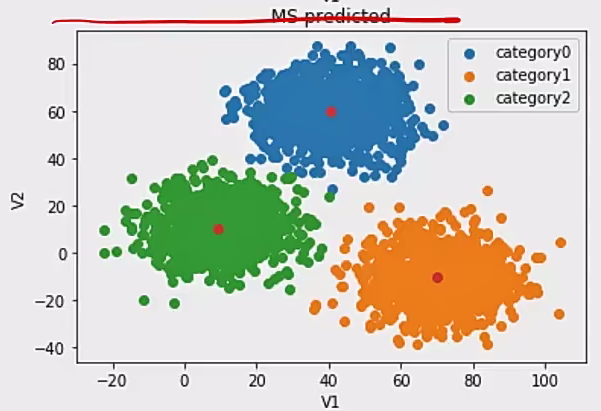
2 Meanshift聚类 2.1 基本概念
均值漂移聚类:一种基于密度梯度上升的聚类算法(沿着密度上升方向寻找聚类中心点)
特点:
1、自动发现类别数量,不需要人工选择
2、需要选择区域平径
2.2 实现代码
1 2 3 4 5 6 7 8 from sklearn.cluster importMeanShift,estimate bandwidth500 )
小结:
kmeans和meanshift -> un-supervised -> training data: X
KNN -> supervised -> training data: X, y
kmeans-> category number
meanshift-> calculate the bandwidth
3 DBSCAN算法
基于密度的空间聚类算法:基于区域点密度筛选有效数据基于有效数据向周边扩张,直到没有新点加入
特点:
1、过滤噪音数据
2、不需要人为选择类别数量
3、数据密度不同时影响结果
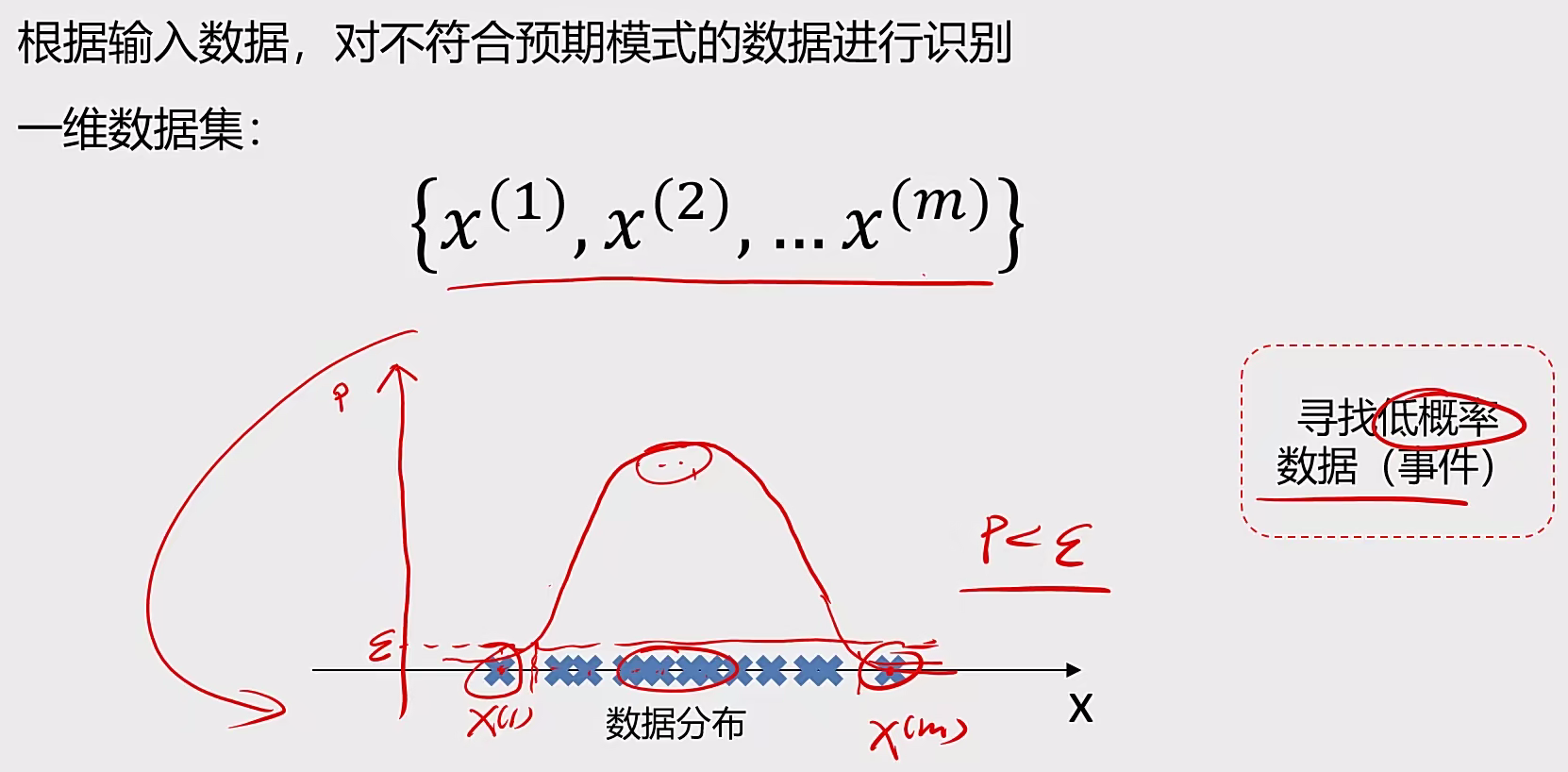
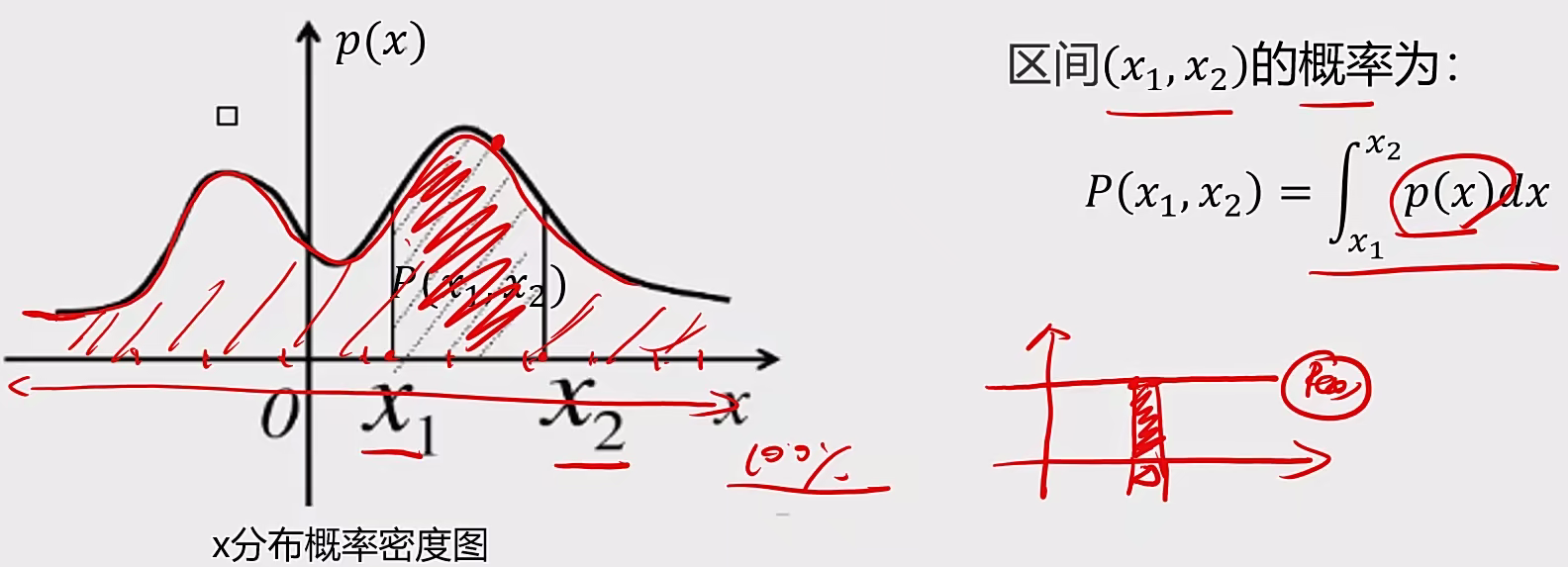
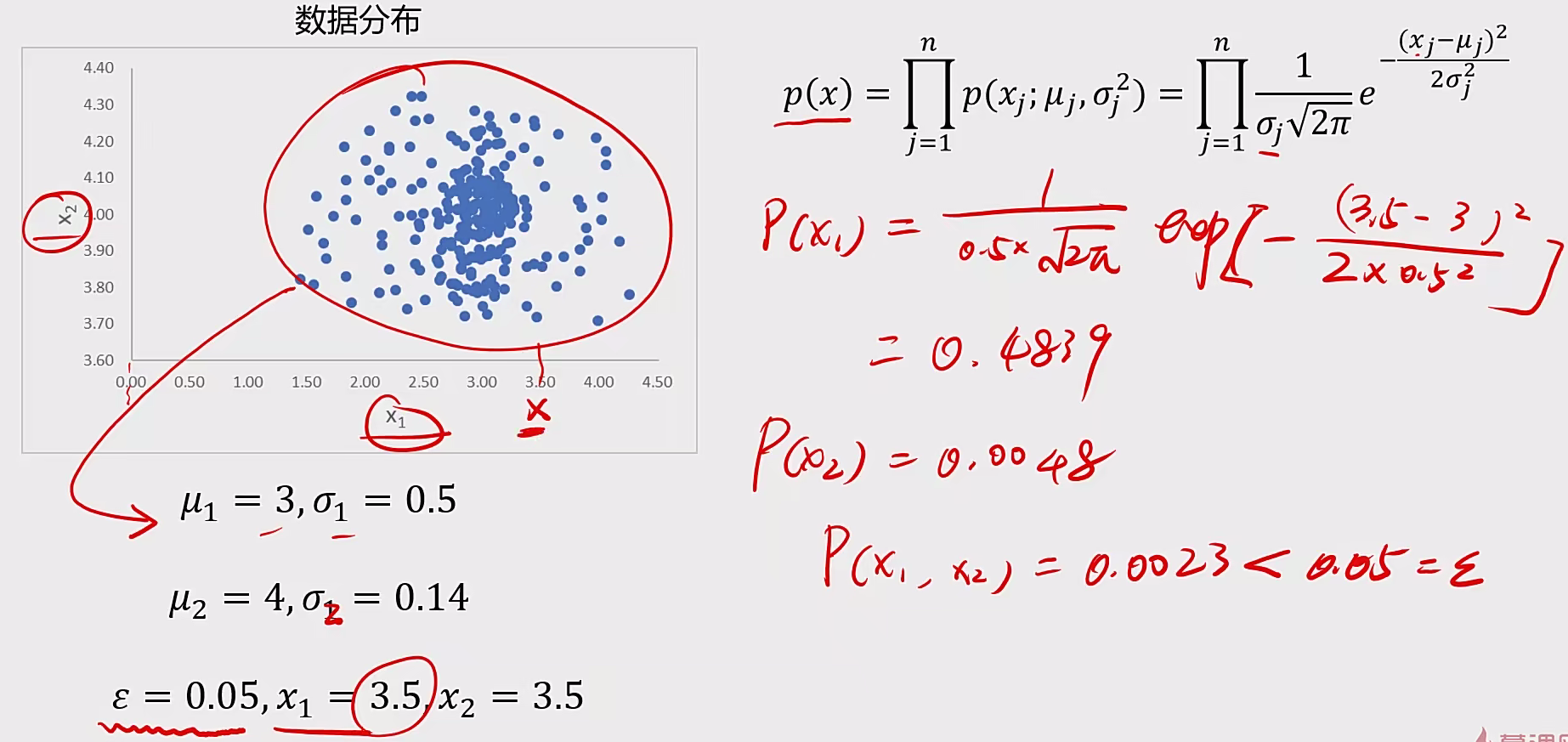
4 异常检测 4.1 基本概念 概率密度:
概率密度函数是一个描述随机变量在某个确定的取值点附近的可能性的函数
高斯分布:
如果高斯分布是高维度的:
1、计算每个维度下数据均值$u_{1},u_{2}…u_{n}$,标准差$σ_{1},σ_{n}…σ_{n}$
2、计算概率密度函数$P(X)$
4.2 代码实现
1 2 3 4 5 异常检测实战task:contamination =0.1)中的contamination,查看阈值改变对结果的影响
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 import numpy as npimport pandas as pd'anomaly_data.csv' )import matplotlib.pyplot as plt7 , 5 ))'x1' ], data.loc[:, 'x2' ])"Anomaly Data" )"x1" )"x2" )'x1' ]'x2' ]20 , 5 ))121 )100 , alpha=0.5 , label='x1' )'x1 distribution' )'x1' )'count' )122 )100 , alpha=0.5 , label='x1' )'x2 distribution' )'x2' )'count' )print (x1_mean, x1_sigma, x2_mean, x2_sigma)from scipy.stats import norm0 , 20 , 300 )0 , 20 , 300 )print (x1_range)20 , 5 ))121 )'normal P(x1)' )'x1' )'p(x1)' )122 )'normal P(x2)' )'x2' )'p(x2)' )from sklearn.covariance import EllipticEnvelopeimport pandas as pdprint (pd.value_counts(y_pred))15 , 8 ))'x1' ], data.loc[:, 'x2' ], marker='x' )'x1' ][y_pred == -1 ], data.loc[:, 'x2' ][y_pred == -1 ], marker='o' , facecolor='none' ,'red' ,s=120 )'Anomaly Data' )'x1' )'x2' )'orange data' , 'anomaly data' ])from sklearn.covariance import EllipticEnvelope0.02 )15 , 8 ))'x1' ], data.loc[:, 'x2' ], marker='x' )'x1' ][y_pred == -1 ], data.loc[:, 'x2' ][y_pred == -1 ], marker='o' ,'none' ,'red' , s=120 )'Anomaly Data' )'x1' )'x2' )'orange data' , 'anomaly data' ])
4 半监督学习 监督学习与无监督学习相结合的一种学习方法,它同时利用有标记样本与无标记样本进行学习。
目的 :在标记样本有限的情况下,尽可能识别出总样本的共同特性。
英文 :Semi-Supervised Learning
伪标签学习 :用有标签数据训练一个分类器,然后用这个分类器对无标签数据进行分类,产生伪标签(pseudo label),按一定规则挑选出认为分类正确的无标签样本,将其与有标签样本作为数据对分类器进行训练。
核心 :想办法利用标签数据提供的正确信息,灵活运用于模型中。
三 PyTorch框架 首先是确定自己的显卡算力版本,我现在是NVIDIA GeForce GTX 1660 Ti(现在刚买了5070)
驱动程序版本: 31.0.15.1601
驱动程序日期: 2022/4/24
DirectX 版本: 12 (FL 12.1)
物理位置: PCI 总线 1、设备 0、功能 0
利用率 0%
专用 GPU 内存 0.0/6.0 GB
共享 GPU 内存 0.0/7.9 GB
GPU 内存 0.0/13.9 GB
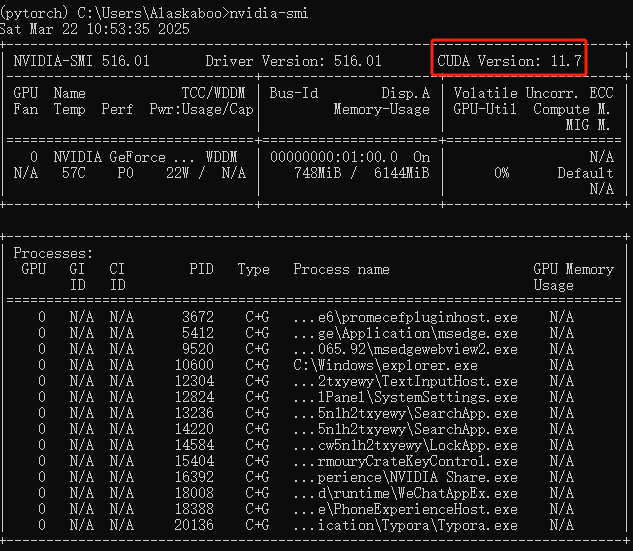
然后通过命令查看自己显卡驱动-cuda driver version 的版本号:nvidia-smi
然后去官网查看自己的cuda-runtime version 版本:CUDA - Wikipedia
由此可见我是算力是7.5,支持的cuda-runtime version版本7.5往上的版本均可,为了不造成cuda-runtime version版本过高导致不必要的错误
切记是cuda版本一定要低于硬件11.7的版本!!!
切记是cuda版本一定要低于硬件11.7的版本!!!
切记是cuda版本一定要低于硬件11.7的版本!!!
1 安装 装这个版本:Anaconda3-2024.02-1-Windows-x86_64.exe!!!
装这个版本:Anaconda3-2024.02-1-Windows-x86_64.exe!!!
装这个版本:Anaconda3-2024.02-1-Windows-x86_64.exe!!!
利用pip install 或者conda安装
再anaconda创建一个虚拟环境(比如叫 pytorch)
我选择CUDA11.3(最稳定),官网安装:
1 2 3 4 5 6 7 8 conda install pytorch torchvision torchaudio cudatoolkit=11 .3 -c pytorchconda install pytorch==1 .13 .0 torchvision==0 .14 .0 torchaudio==0 .13 .0 pytorch-cuda=11 .7 -c pytorch -c nvidiaconda install pytorch==2 .5 .1 torchvision==0 .20 .1 torchaudio==2 .5 .1 pytorch-cuda=12 .4 -c pytorch -c nvidia
或者方法二:download.pytorch.org/whl/torch_stable.html
直接到对应包连接下载
放在Scripts目录下pip install “torch-1.10.0+cu113-cp36-cp36m-win_amd64.whl”即可
激活对应的虚拟环境(你安装Pytorch的虚拟环境)
1 2 3 4 5 6 1. conda activate 虚拟环境名2. 输入conda list,看有没有pytorch或者torchimport torch3. 如果显示True ,就说明我们这个PyTorch安装成功了
测试cudnn
1 2 3 4 5 6 7 8 9 10 pythonimport torchprint (torch.backends.cudnn.version())from torch.backends import cudnn 1. )
2 基本介绍 2.1 概念 PyTorch 是一种用于构建深度学习模型的功能完备框架,是一种通常用于图像识别和语言处理等应用程序的机器学习。使用 Python 编写,因此对于大多数机器学习开发者而言,学习和使用起来相对简单。PyTorch 的独特之处在于,它完全支持 GPU,并且使用反向模式自动微分技术计算梯度 ,因此可以动态修改计算图形。这使其成为快速实验和原型设计的常用选择
2.2 相关库简介
**torchvision:**内置了常用的数据集和常见的模型
**transforms:**用来做数据增强,数据预处理等功能
transforms.ToTensor():
将图片转换为Tensor
将图片的像素值从[0,255]转换为[0,1]
将图片的通道channel放到第一个维度上
pytorch中图片的表现形式**[batch_size, channel, height, width]**
#降维squeeze
img = np.squeeze(img)
3 处理技术 3.1 数据增强 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from torchvision import transforms224 , 224 )),192 ), 0.4 ), 0.5 , contrast=0.5 ), 0.5 , 0.5 , 0.5 ], std=[0.5 , 0.5 , 0.5 ])224 , 224 )),0.5 , 0.5 , 0.5 ], std=[0.5 , 0.5 , 0.5 ])
1 2 3 4 5 6 7 batch_size = 32 True )False )
3.2 学习率衰减 1 lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10 , gamma=0.1 )
3.3 迁移GPU 1 2 3 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" )
3.4 损失和优化器 1 2 3 4 1e-3
3.5 定义train函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 def train (epoches, model, train_loader, test_loader ):0 0 0 for x, y in train_loader:with torch.no_grad():1 )sum ().item()0 )eval ()0 0 0 with torch.no_grad():for x, y in test_loader:1 )sum ().item()0 )print ('Epoch: {}, Loss: {:.4f}, Acc: {:.4f}, test_Loss: {:.4f}, test_Acc: {:.4f}' .format (epoches + 1 , epoch_loss,return epoch_loss, epoch_acc, test_epoch_loss, test_epoch_acc
3.6 模型保存与加载 保存精度最好的模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 epoches = 20 0.0 for epoch in range (epoches):if test_epoch_acc > best_acc:'./vgg16_best_model.pth' )print ('best_acc: {:.4f}' .format (best_acc))
加载最好的模型并测试
1 2 3 "vgg16_best_model.pth" ), map_location=device)
3 语法 tensor创建
1 2 3 4 5 6 7 8 9 torch.tensor([1 , 2 , 3 ], dtype=torch.float32)1 , 2 , 3 ]))3 , 3 ))2 , 3 )
取值
1 2 3 4 5 6 7 8 9 10 2 , 3 , 4 )0 , :, :]0 ]32 , 224 , 224 , 3 )0 , :, :, 0 ]
运算
1 2 3 4 5 6 7 8 9 10 11 t = torch.randn((3 , 3 ))2 , 3 )3 , 5 )
自动微分:微分必须是一个标量,不能是向量~~
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 x = torch.ones(2 , 2 , requires_grad=True )2 2 , 2 )3 print (y.requires_grad_(True ))
4 经典算法实现 4.1 线性回归 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from torch import nnimport torchimport pandas as pdimport matplotlib.pyplot as plt"./data/Income1.csv" )1 , 1 )).type (torch.float32)1 , 1 )).type (torch.float32)1 , 1 )0.001 )for epoch in range (5000 ):for x, y in zip (X, Y):'Education' )'Income' )'red' )
4.2 二分类封装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 import torchimport numpy as npimport pandas as pdimport torch.nn as nnfrom torch.utils.data import TensorDataset, DataLoaderfrom sklearn.model_selection import train_test_split'./data/HR_comma_sep.csv' )'part' ], dtype=int )).join(pd.get_dummies(data['salary' ], dtype=int ))'part' , 'salary' ], axis=1 )'left' ].value_counts()'left' ] == 0 ).sum () / len (data.left)'left' ].values.reshape(-1 , 1 )type (torch.FloatTensor)for columns in data.columns if columns != 'left' ]].valuestype (torch.FloatTensor)class HRModel (nn.Module):def __init__ (self ):super ().__init__()self .linear1 = nn.Linear(20 , 64 )self .linear2 = nn.Linear(64 , 64 )self .linear3 = nn.Linear(64 , 1 )self .activate = nn.ReLU()self .sigmoid = nn.Sigmoid()def forward (self, x ):self .linear1(x)self .activate(x)self .linear2(x)self .activate(x)self .linear3(x)self .sigmoid(x)return x1e-3 100 64 len (X) // batch_sizeTrue )2 , shuffle=True )def get_model ():return model, torch.optim.Adam(model.parameters(), lr=lr)def loss_batch (model, loss_func, x, y, optimizer=None ):if optimizer is not None :return loss.item(), len (x)def train (epoches, model, loss_func, optimizer, train_dl, valid_dl ):for epoch in range (epoches):for x, y in train_dl:eval ()with torch.no_grad():zip (*[loss_batch(model, loss_func, x, y) for x, y in valid_dl])sum (np.multiply(losses, nums)) / np.sum (nums)for x, y in valid_dl])print (f'epoch: {epoch} , val_loss: {val_loss} , acc_mean: {acc_mean} ' )def accuracy (output, y_true ):return ((output.data.numpy() > 0.5 ) == y_true.numpy()).mean()def get_data (train_ds, valid_ds, batch_size ):True )2 , shuffle=True )return train_dl, valid_dl
4.3 CNN网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 import torchimport torch.nn as nnimport matplotlib.pyplot as pltimport torch.nn.functional as Ffrom torch.utils.data import DataLoaderfrom torchvision import transforms, datasets'../dataset' , train=True , transform=transform, download=True )'../dataset' , train=False , transform=transform)64 True )2 , shuffle=False )class Model (nn.Module):def __init__ (self ):super ().__init__()self .conv1 = nn.Conv2d(1 , 16 , 3 ) self .pool = nn.MaxPool2d(2 , 2 ) self .conv2 = nn.Conv2d(16 , 32 , 3 ) self .fc1 = nn.Linear(32 * 5 * 5 , 128 ) self .fc2 = nn.Linear(128 , 10 )def forward (self, x ):self .conv1(x))self .pool(x)self .conv2(x))self .pool(x)1 , 32 * 5 * 5 )self .fc1(x))self .fc2(x)return x'cuda:0' if torch.cuda.is_available() else 'cpu' )1e-3 10 , gamma=0.1 )
接下来定义训练函数和开始训练,代码参考 3 技术板块
绘图
1 2 3 4 5 6 plt.plot(train_loss, label='train_loss' )'test_loss' )'train_acc' )'test_acc' )
5 实战 5.1 天气分类(手写版) 导入包
1 2 3 4 5 6 7 8 import osimport torchimport shutilimport torchvisionimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport matplotlib.pyplot as plt
数据准备
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 base_dir = '../dataset/weather' 'train' )'test' )'cloudy' , 'rain' , 'shine' , 'sunrise' ]if not os.path.exists(train_dir):if not os.path.exists(test_dir):for species_name in species:if not os.path.exists(os.path.join(train_dir, species_name)):if not os.path.exists(os.path.join(test_dir, species_name)):
图片转移到对应数据目录:
1 2 3 4 5 6 7 8 9 10 11 12 for i, img in enumerate (filenames):for species_name in species:if species_name in img:if i % 5 == 0 :else :
查看train和test目录中的图片数量
1 2 3 for train_or_test in ['train' , 'test' ]:for species_name in species:print (train_or_test, species_name, len (os.listdir(os.path.join(base_dir, train_or_test, species_name))))
图片增强
1 2 3 4 5 6 7 8 9 10 96 , 96 )),96 ),0.5 , 0.5 , 0.5 ], std=[0.5 , 0.5 , 0.5 ])
数据加载
1 2 3 4 5 6 7 train_dataset = torchvision.datasets.ImageFolder(root=train_dir, transform=transforms)32 True , drop_last=True )False , drop_last=True )
模型定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class Model (nn.Module):def __init__ (self ):super ().__init__()self .conv1 = nn.Conv2d(3 , 16 , 3 ) self .bn1 = nn.BatchNorm2d(16 )self .pool = nn.MaxPool2d(2 , 2 ) self .conv2 = nn.Conv2d(16 , 32 , 3 ) self .bn2 = nn.BatchNorm2d(32 )self .conv3 = nn.Conv2d(32 , 64 , 3 ) self .bn3 = nn.BatchNorm2d(64 )self .dropout = nn.Dropout()self .fc1 = nn.Linear(64 * 10 * 10 , 1024 )self .bn_fc1 = nn.BatchNorm1d(1024 )self .fc2 = nn.Linear(1024 , 256 )self .bn_fc2 = nn.BatchNorm1d(256 )self .fc3 = nn.Linear(256 , 4 )def forward (self, x ):self .pool(self .bn1(F.relu(self .conv1(x))))self .pool(self .bn2(F.relu(self .conv2(x))))self .pool(self .bn3(F.relu(self .conv3(x))))self .bn_fc1(F.relu(self .fc1(x)))self .dropout(x)self .bn_fc2(F.relu(self .fc2(x)))self .dropout(x)self .fc3(x)return x
转移GPU
定义损失函数和优化器
最后训练函数定义,和开始训练,代码参考第三节
5.1 迁移学习 仅需更换model如下即可:
1 2 3 4 5 6 7 8 'TORCH_HOME' ] = '../dataset' for param in model.features.parameters():False 1 ].out_features = 4
6 tensorboard 6.1 安装
pip install tensorboard
6.2 使用 创建总体文件
1 2 3 4 from torch.utils.tensorboard import SummaryWriter'runs/fashion_mnist_experiment_1' )
写入数据
1 2 3 4 5 6 7 8 9 10 11 dataiter = iter (trainloader)next (dataiter)True )'four_fashion_mnist_images' , img_grid)
运行
1 tensorboard --logdir=runs
添加模型查看
1 2 writer.add_graph(net, images)
等等详情请看官网:使用 TensorBoard 可视化模型、数据和训练 — PyTorch 教程 2.7.0+cu126 文档 - PyTorch 深度学习库
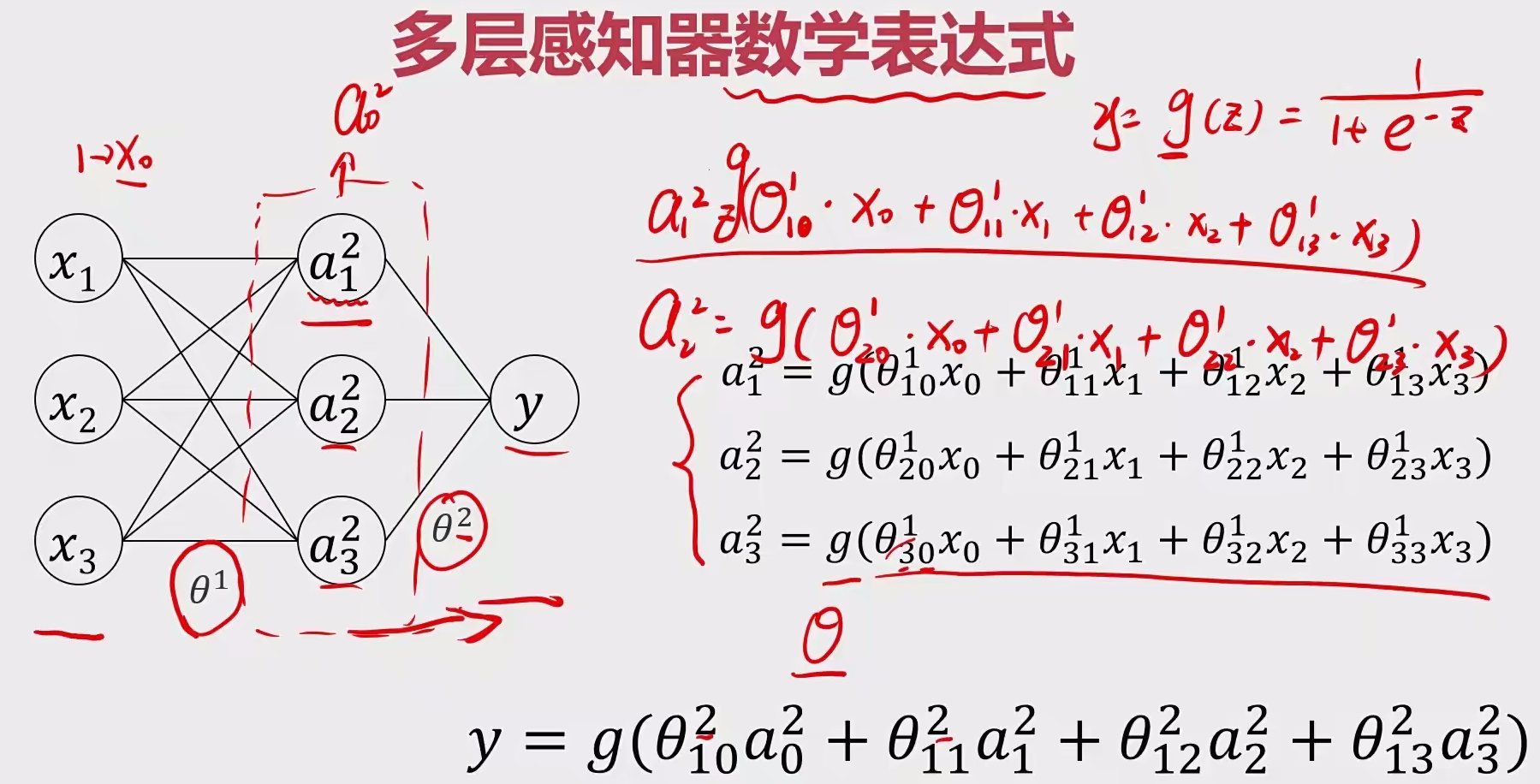
四 深度学习 1 多层感知器(MLP) 感知机(perceptron)是二分类的线性分类模型 ,属于监督学习算法。输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机旨在求出将输入空间中的实例划分为两类的分离超平面 梯度下降法 对损失函数进行最优化求解。
多层感知器 (英语:Multilayer Perceptron,缩写:MLP )是一种前向结构的人工神经网络,映射一组输入向量到一组输出向量,一种被称为反向传播算法的监督学习方法常被用来训练MLP。
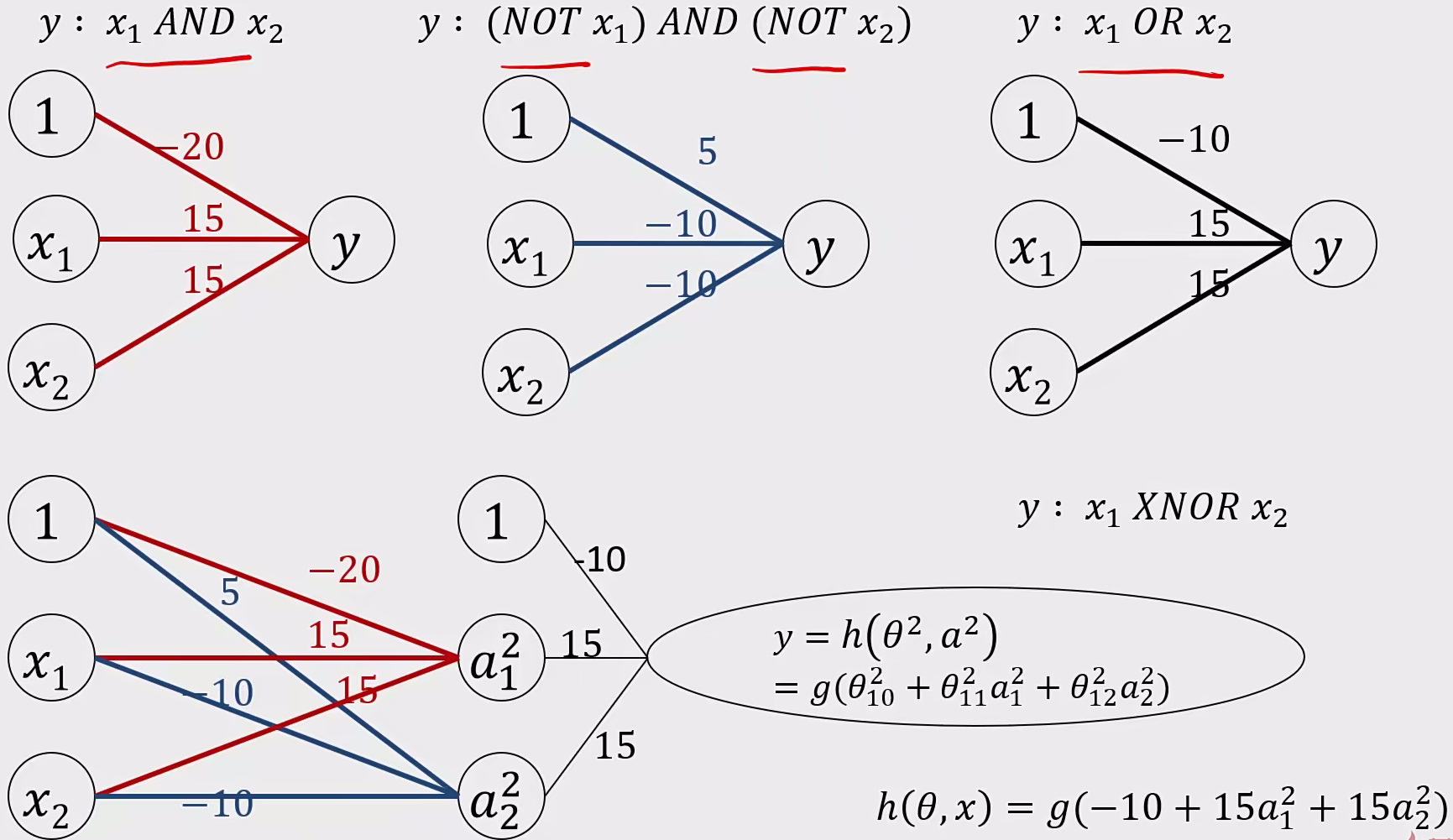
同或门函数:
y : $x_{1} OR x_{2}$ ,其中有一个为1,那就是1。
函数表达式为 :$h(\Theta,x)=g(-10+15x_{1}+15x_{2})$
与门函数:
y : $x_{1} AND x_{2}$ ,只有两个同时为1时候才是1。
函数表达式为 :$h(\Theta,x)=g(-20+15x_{1}+15x_{2})$
y : $(NOT x_{1}) AND (NOT x_{2})$ ,只有两个同时为0时候才是1。
函数表达式为 :$h(\Theta,x)=g(5-10x_{1}-10x_{2})$
问题:在建立MLP模型实现图像多分类任务中,其流程应该是怎么样的?(B A C E F D)
A、对输入数据进行维度转换与归一化处理
B、加载图片并将其转换为数字矩阵
C、建立MLP模型结构
D、对输出结果进行格式转化
E、MLP模型训练参数配置
F、模型训练与预测
1 2 3 4 5 6 7 8 9 10 11 12 13 14 from keras.models import Sequentialfrom keras.layers import Dense3 , activation='sigmoid' , input dim=3 ))1 , activation='sigmoid' ))compile (loss='categorical_crossentropy' , optimizer='sgd' )5 )
2 卷积神经网络 2.1 基本概念 对MLP的处理是否可能进一步减少训练参数数量?
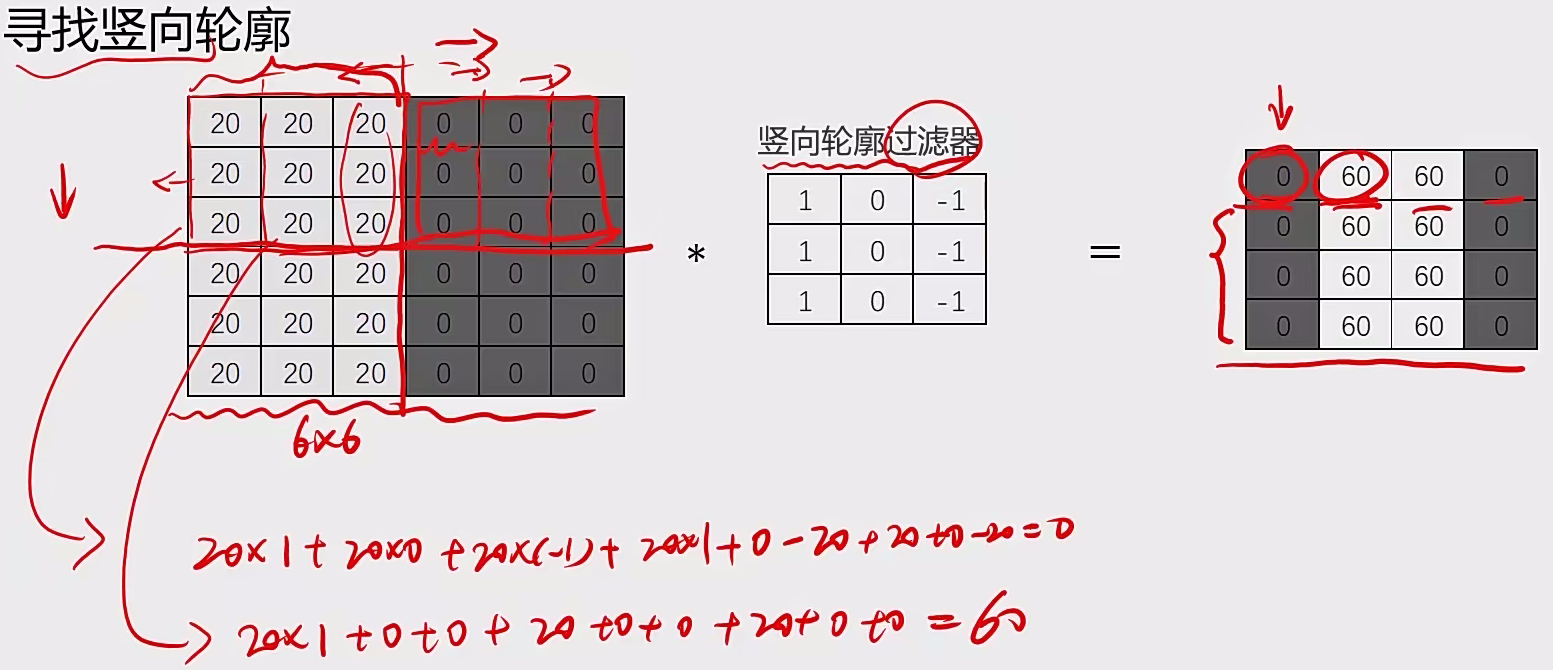
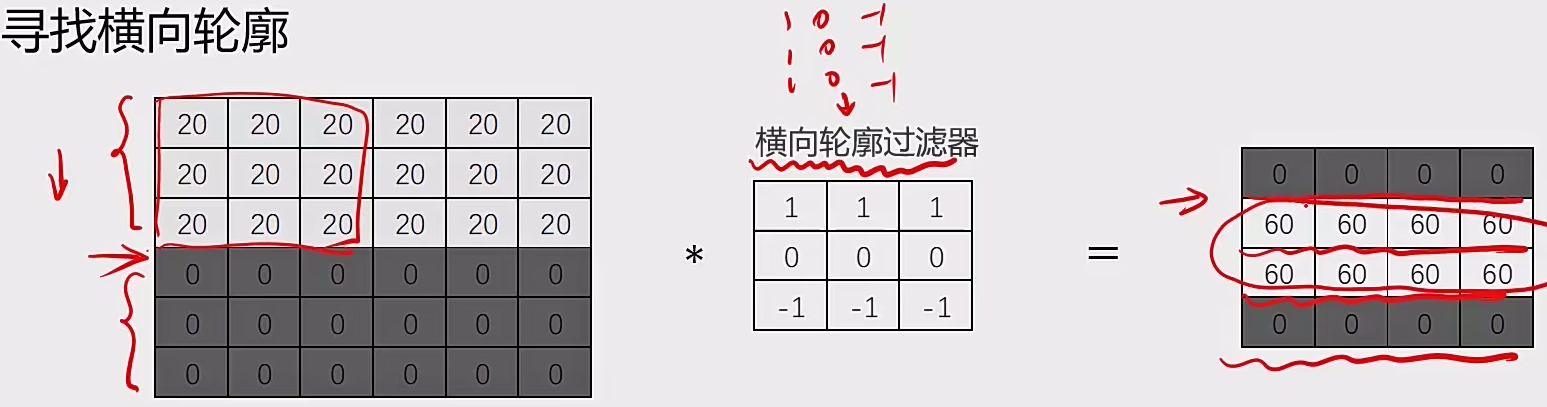
2.1.1 卷积层:图像卷积运算(CNN)
对图像矩阵与滤波器矩阵进行对应相乘再求和运算,转化得到新的矩阵。
作用:快速定位图像中某些边缘特征
A与B的卷积通常表示为:A * B 或 convolution(A, B)
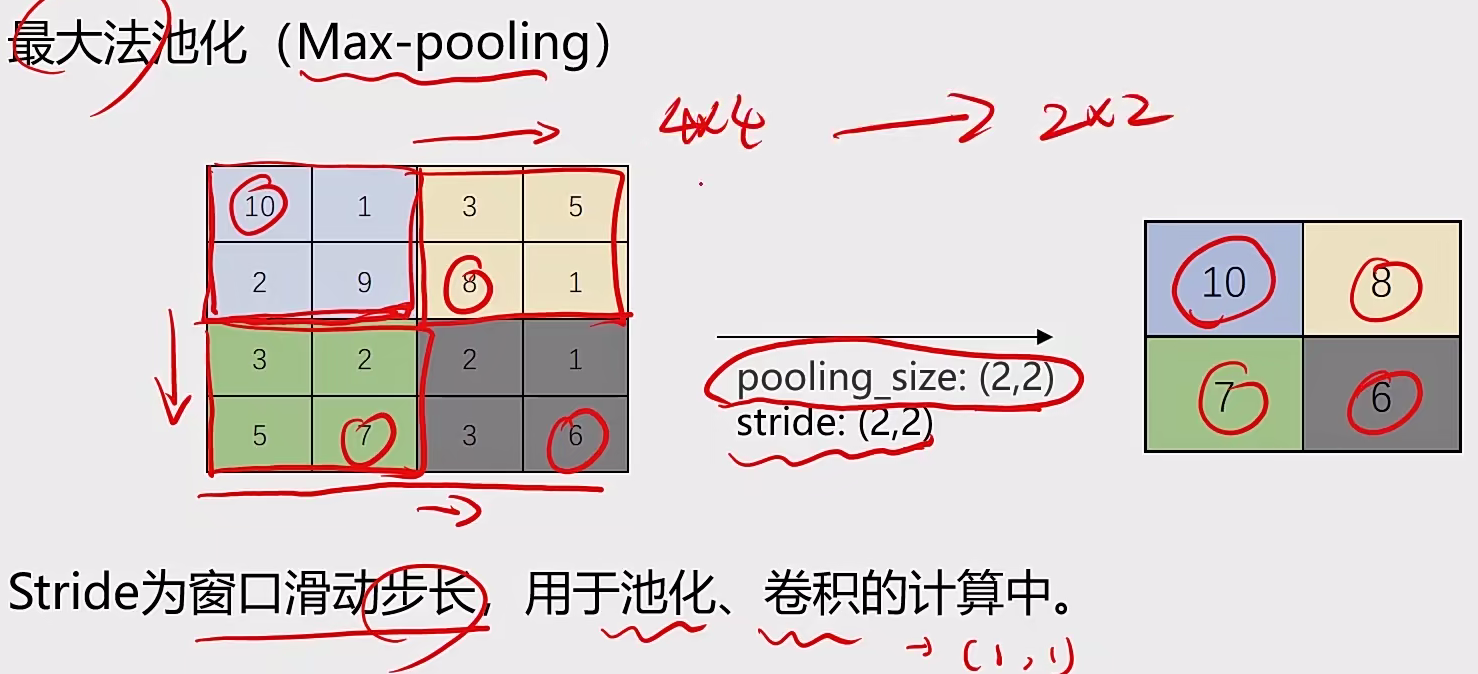
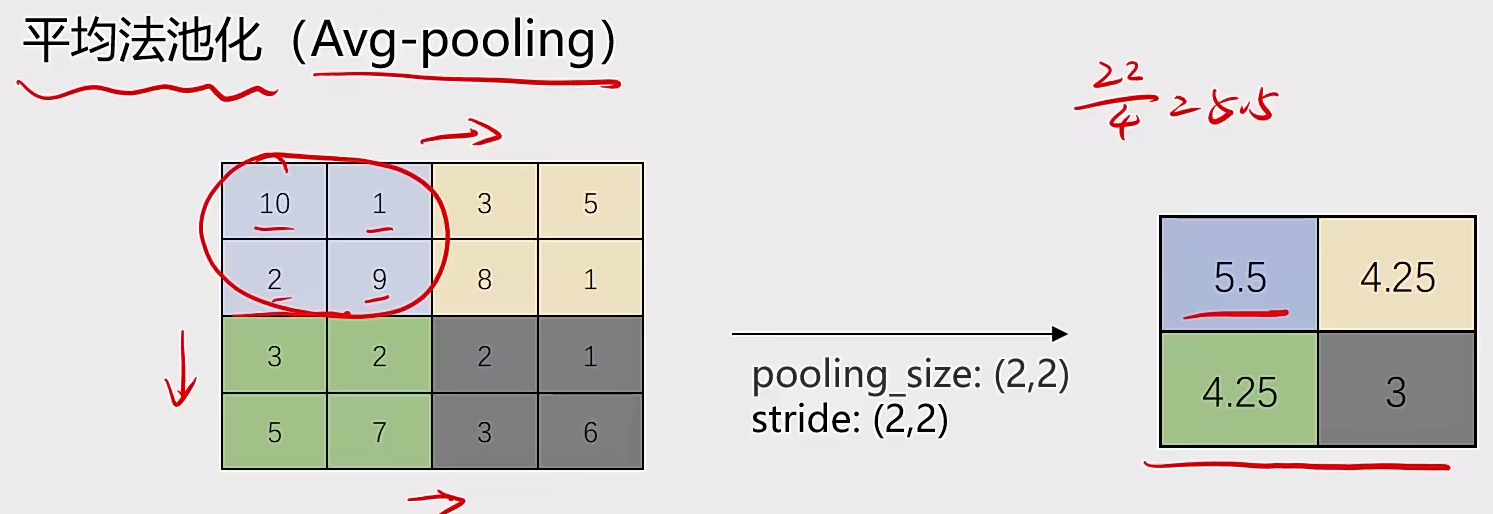
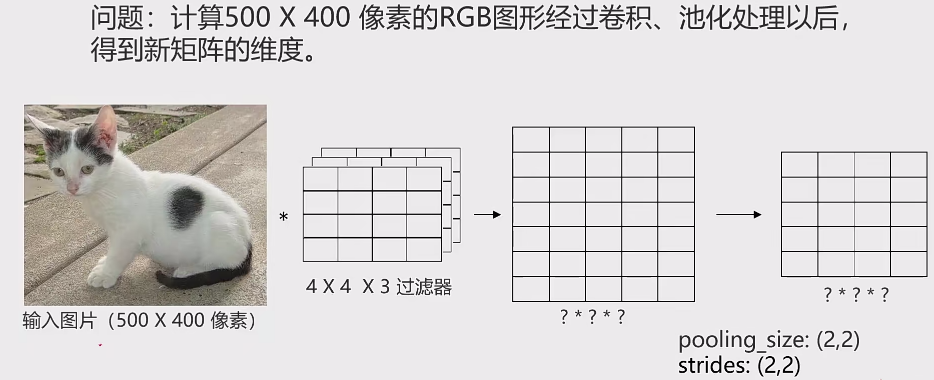
2.1.2 池化层:实现维度缩减
池化:按照一个固定规则对图像矩阵进行处理,将其转换为更低维度的矩阵
卷积神经网络两大特点:
参数共享(parameter sharing):同一个特征过滤器可用于整张图片
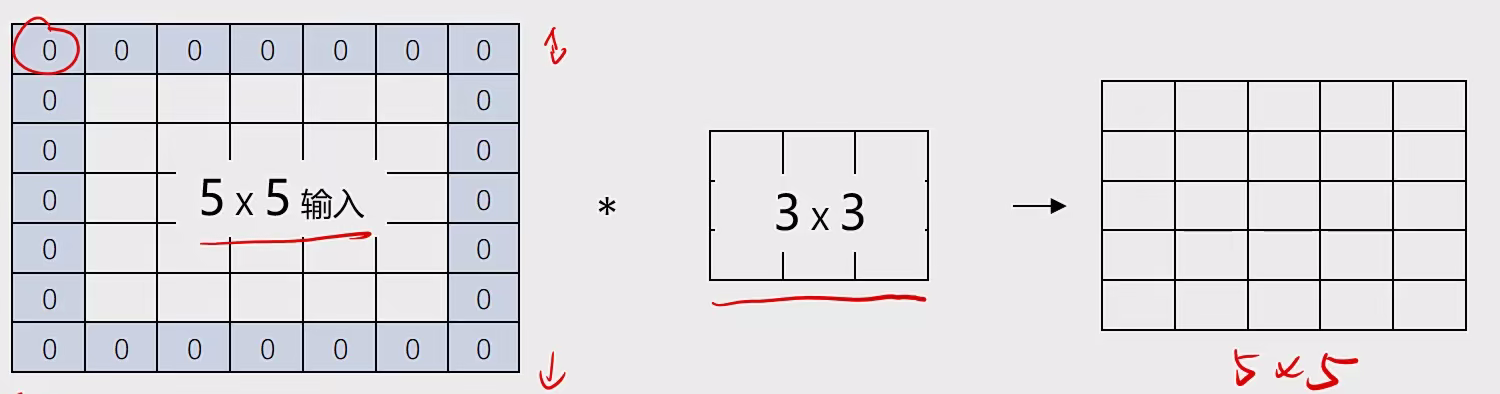
**图像填充:**通过在图像各边增加像素,使其在进行卷积运算后维持原图大小。通过padding增加像素的数量,由过滤器尺气
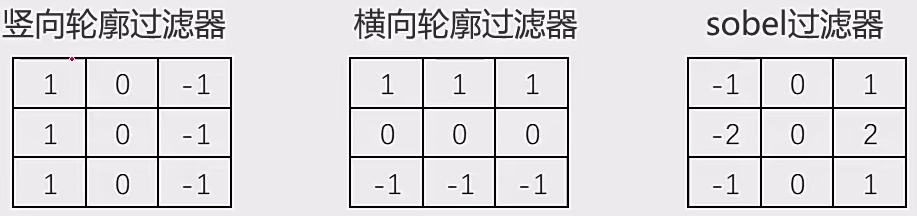
轮廓过滤器
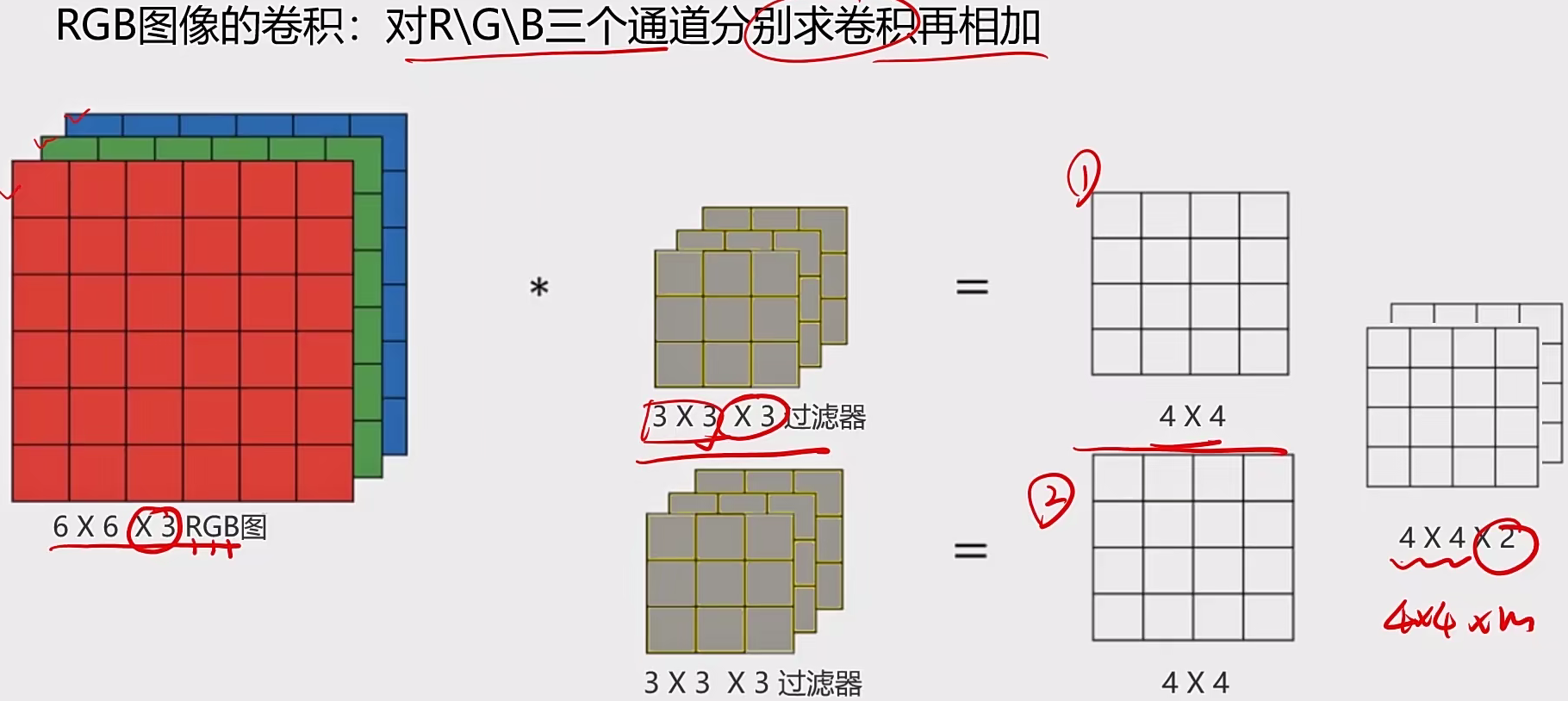
RGB的图像卷积
通道计算
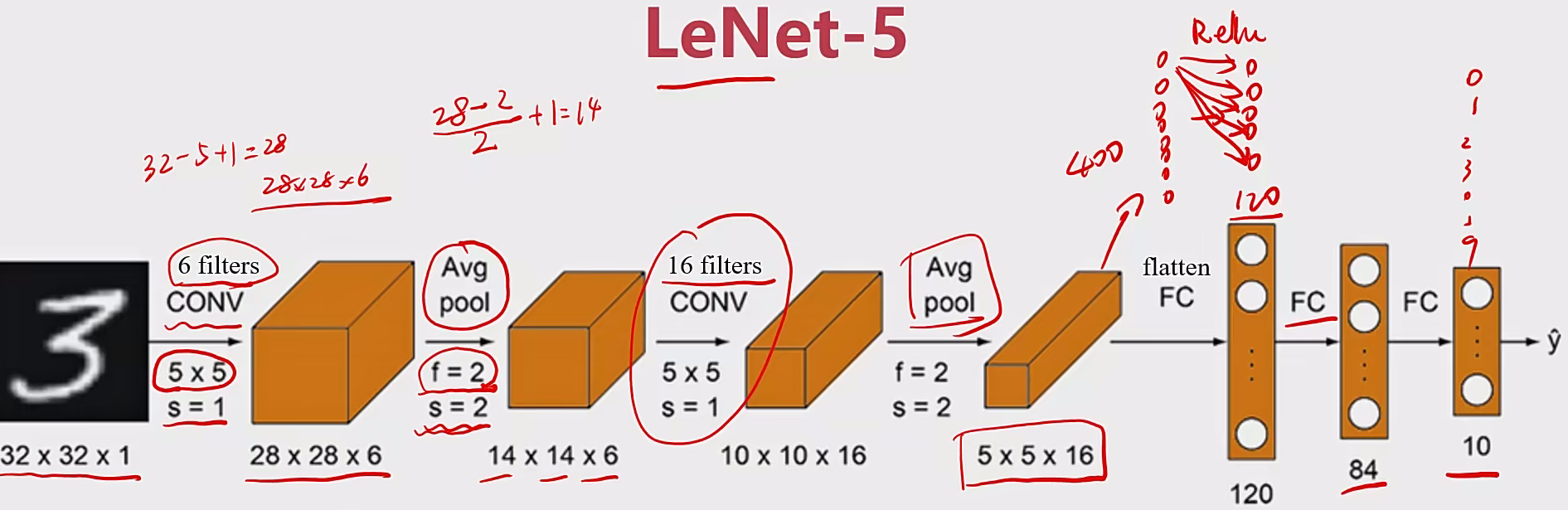
2.2 经典CNN模型 2.2.1 LeNet-5 操作:
输入图像:32 ×32灰度图,1个通道(channel)
特点:
1、随着网络越深,图像的高度和宽度在缩小,通道数在增加
流程图:
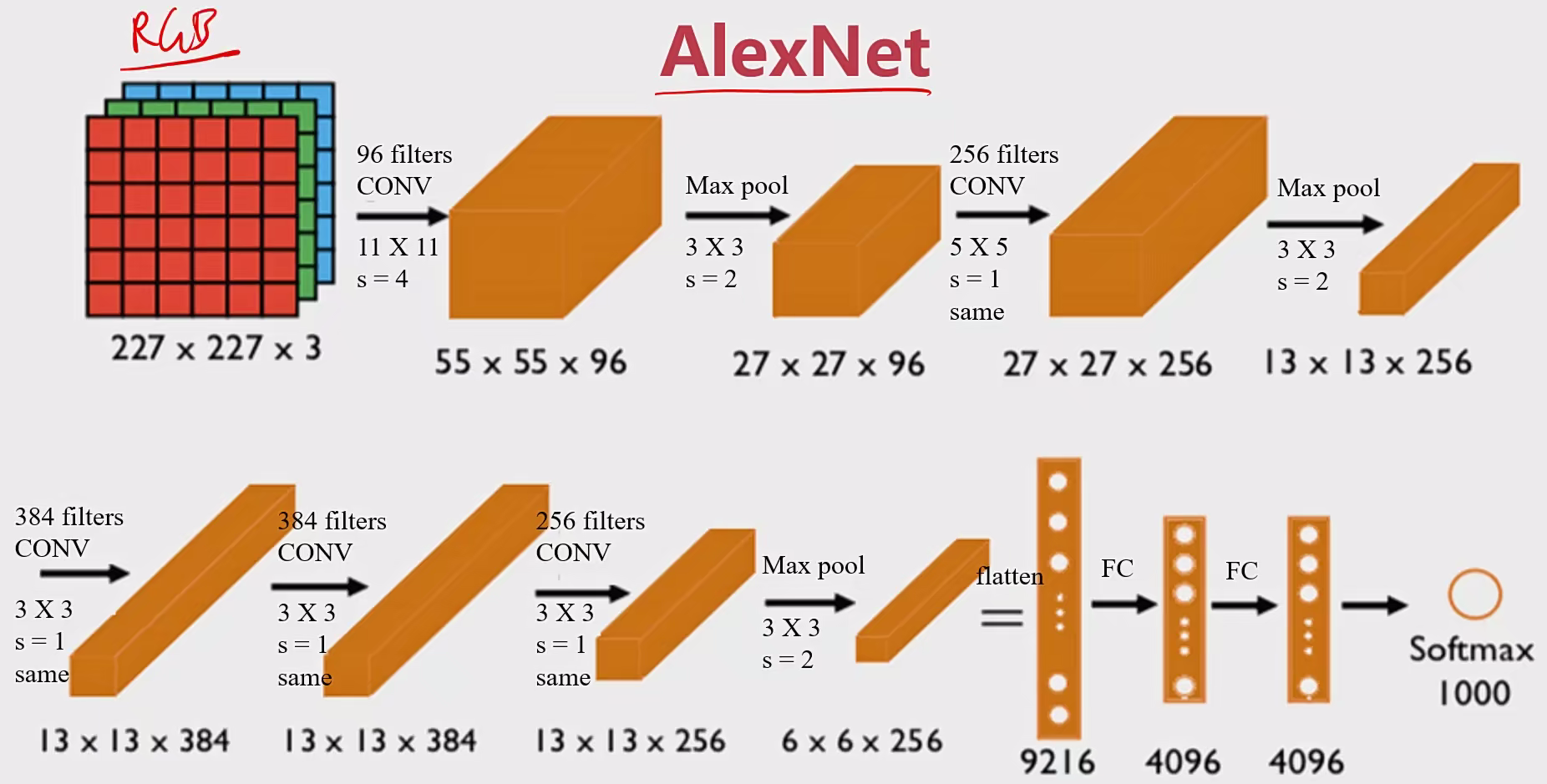
2.2.2 AlexNet 操作:
输入图像:227×227×3 RGB图 ,3个通道
训练参数:约60,000,000个
特点:
1、适用于识别较为复杂的彩色图,可识别1000种类别
流程图:
意义:
学术界开始相信深度学习技术,在计算机视觉应用中可以得到很不错的结果。
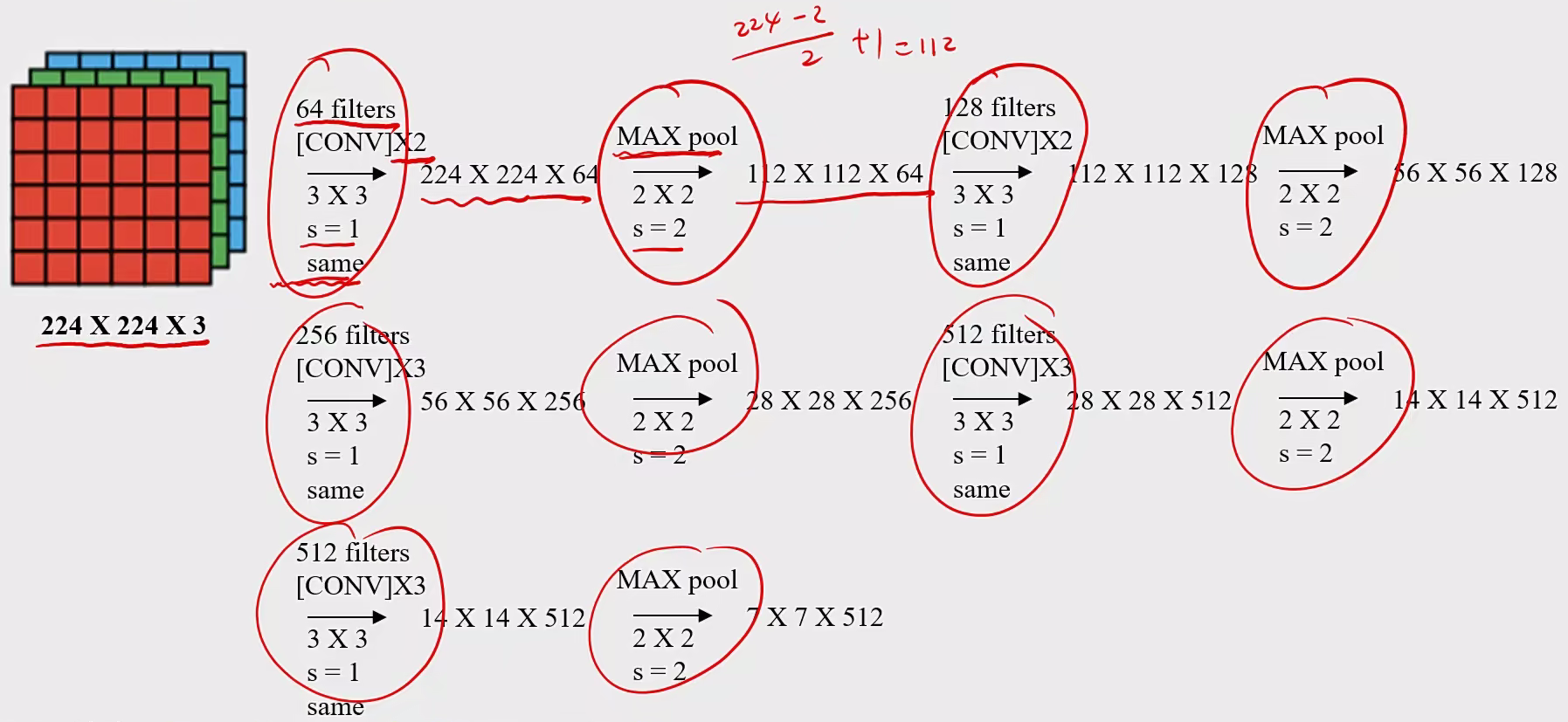
2.2.3 VGG-16 操作:
输入图像:227×227× 3 RGB图,3个通道
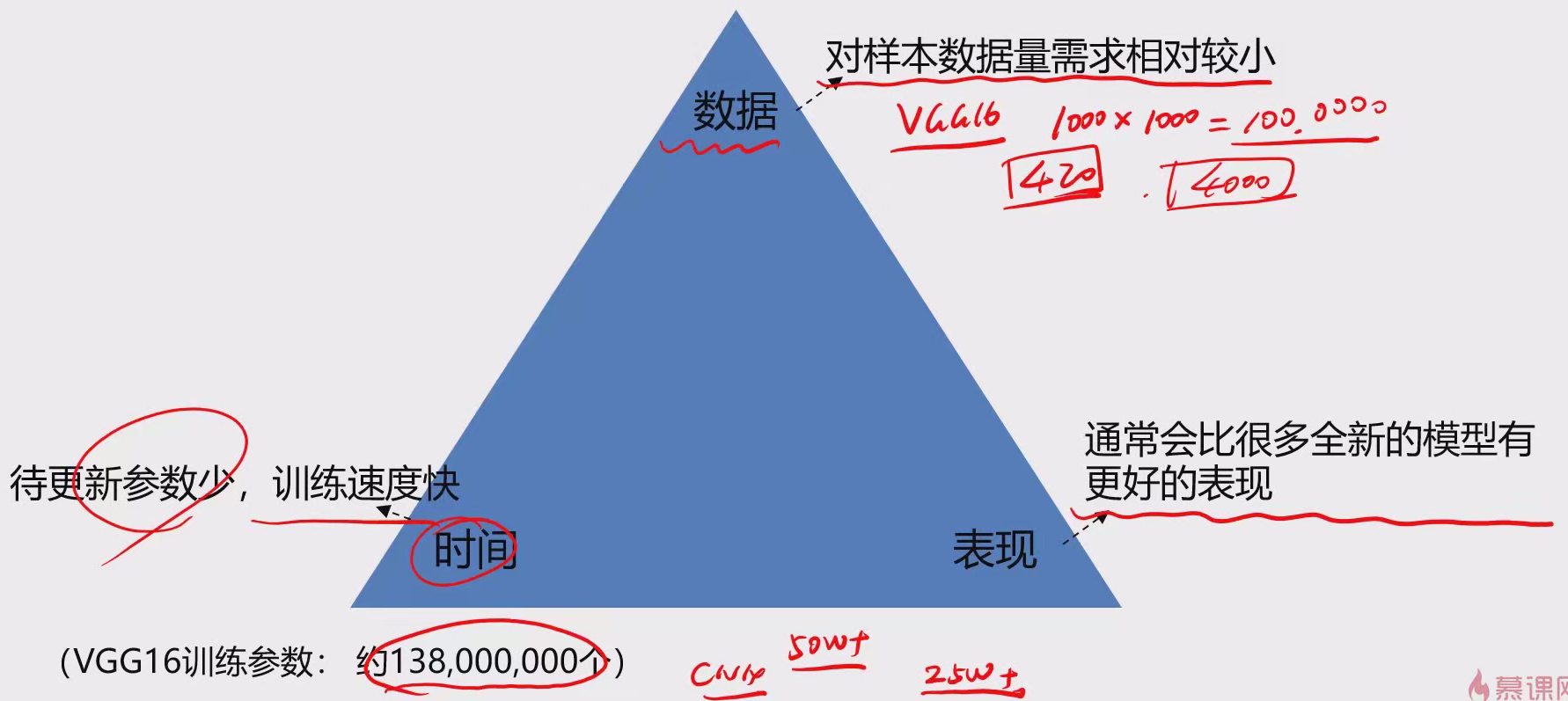
训练参数:约138,000,000个
特点:
1、所有卷积层filter 宽和高都是3,步长为1,padding 都使用same convolution(相同的卷积操作保证数据的稳定性);
流程图:
2.3 实战 2.3.1建立CNN实现猫狗识别
图片加载
1 2 3 4 5 from keras.preprocessing.image import lmageDataGenerator1. /255 )set = train datagen.flow from directory("./Dataset/training set, target_size =(50,50), batch_size = 32, class_mode = 'binary')
建立CNN模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from keras.models import Sequentialfrom keras.layers import Conv2D,MaxPooling2D, Flatten,Dense32 ,(3 ,3 ),input_shape = (50 ,50 ,3 ), activation = 'relu' ))2 ,2 )))32 , (3 , 3 ), activation = 'relu' ))2 ,2 )))128 , activation = 'relu' ))1 , activation = 'sigmoid' ))
训练与预测:
1 2 3 4 5 6 7 8 9 compile (optimizer = 'adam' , loss = 'binary_crossentropy' , metrics = ['accuracy' ])25 )
2.3.2 基于VGG-16、结合MLP实现猫狗识别
图片加载:
1 2 3 4 from keras.preprocessing.image import img_to_array, load_img'1.jpg' 224 , 224 ))
图片预处理:
1 2 3 4 from keras.applications.vgg16 import preprocess_input0 )
载入VGG16结构(去除全连接层)∶
1 2 from keras.applications.vgg16 import VGG16'imagenet' , include_top=False )
特征提取
1 features = model_vgg.predict(x)
建立mlp模型
1 2 3 4 5 6 7 8 9 from keras.layers import Dense10 , activation= 'relu' , input_dim=25088 ))1 , activation='sigmoid' ))compile (optimizer='adam' ,loss='binatiry_crossentropy' , metrics=['accuracy' ])50 )
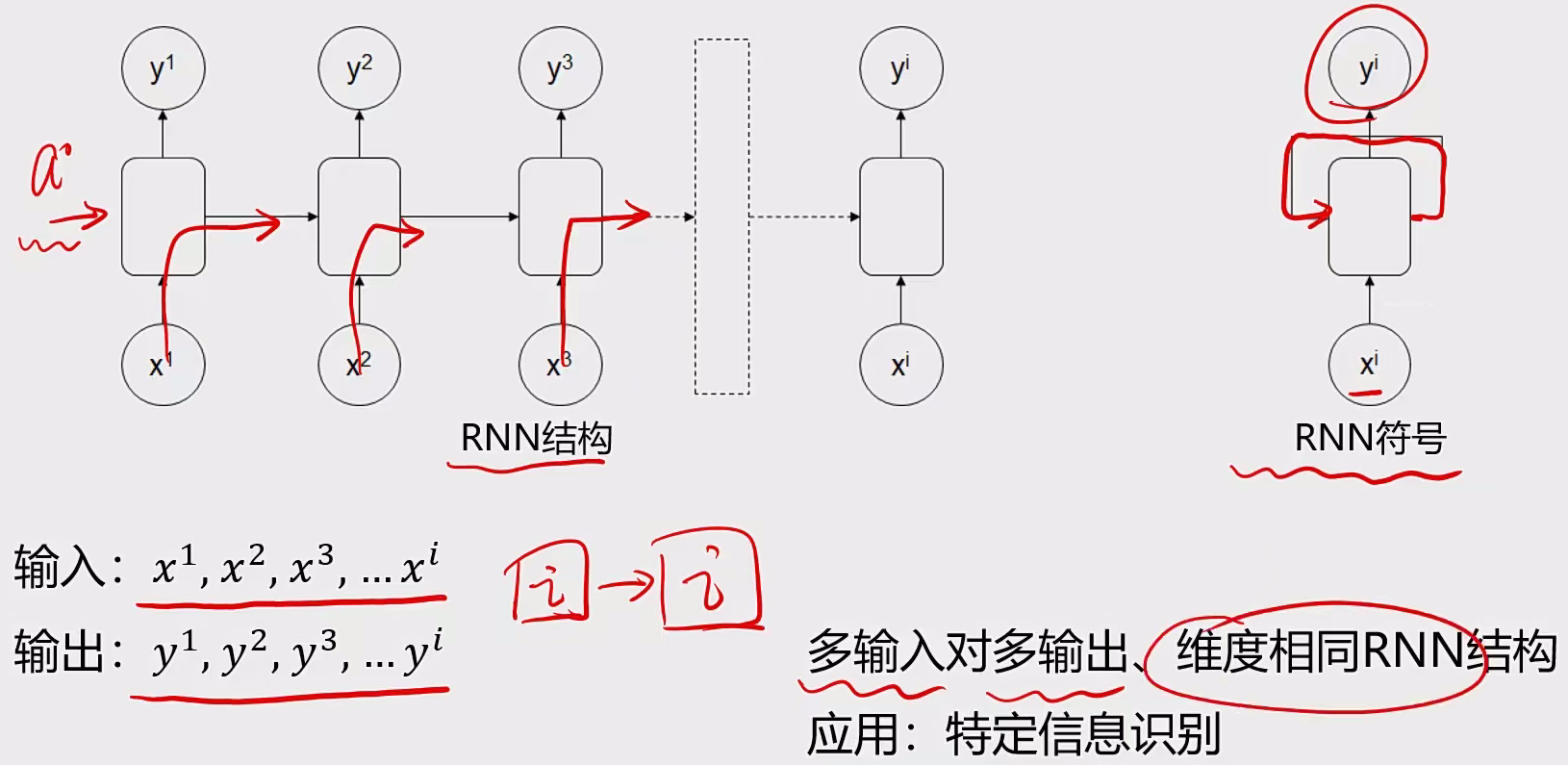
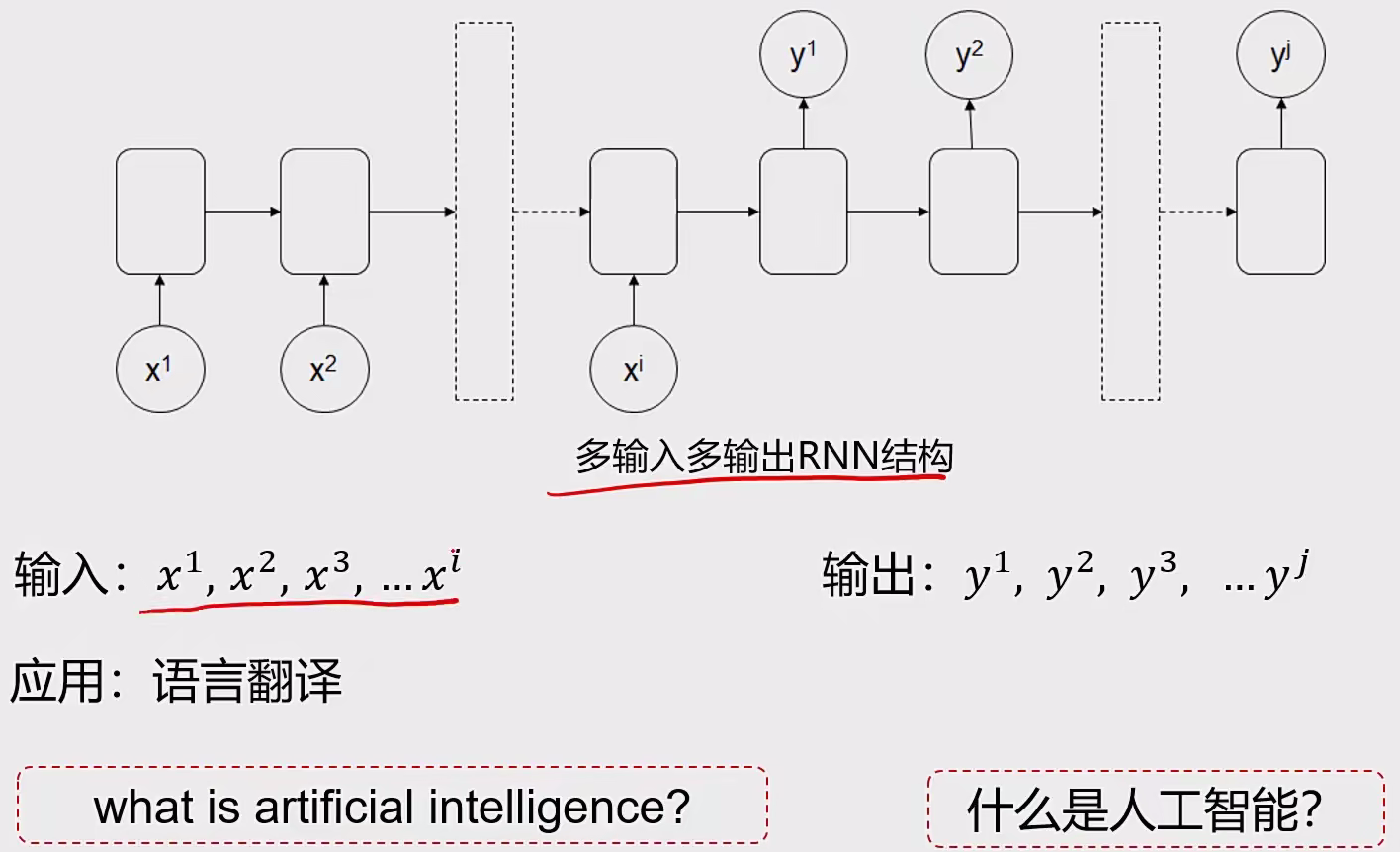
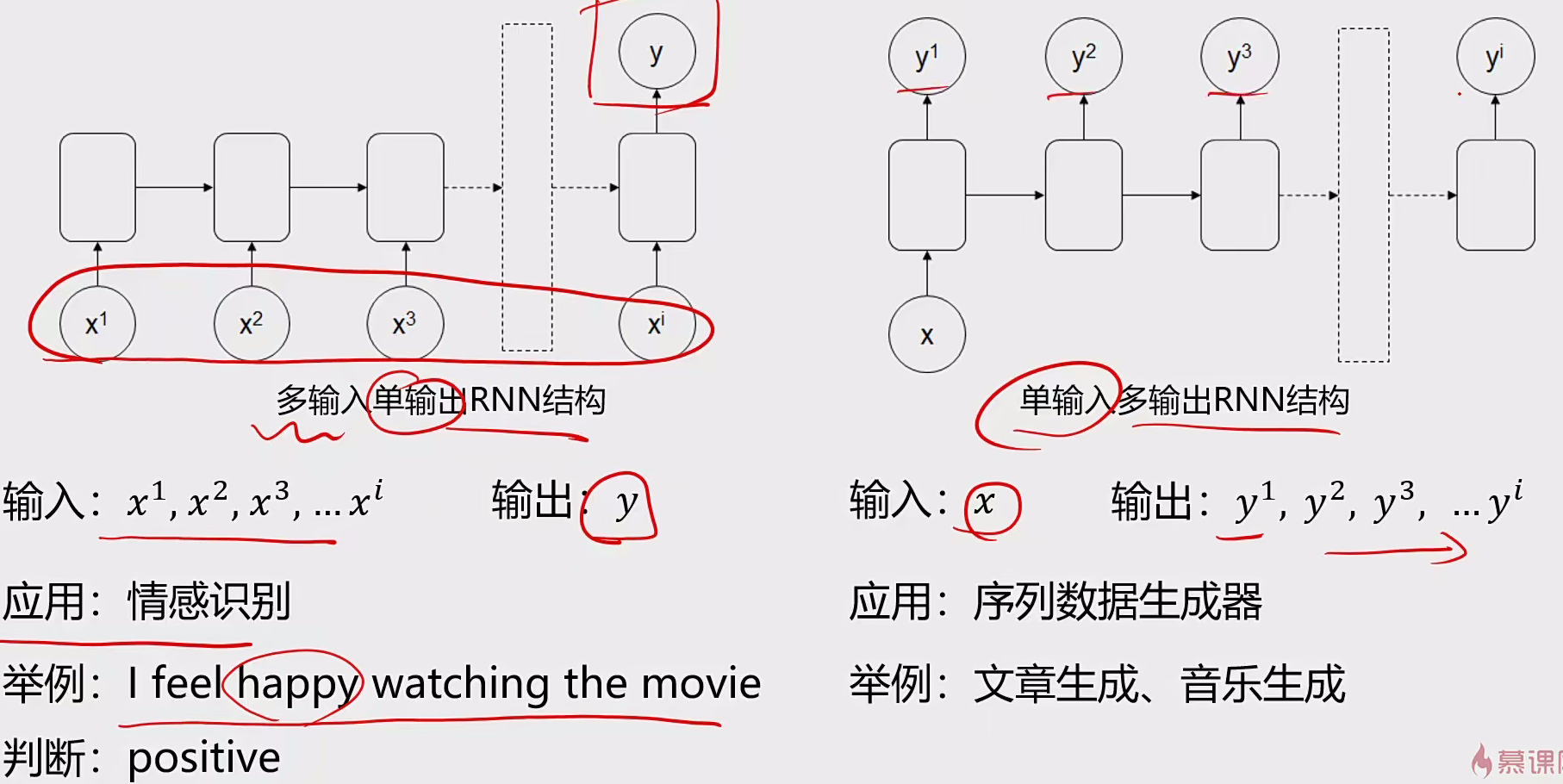
3 循环神经网络RNN 3.1 基本概念 序列模型:
输入或者输出中包含有序列数据的模型
两大特点:
输入(输出)元素之间是具有顺序关系。不同的顺序,得到的结果应该是不同的,比如“不吃饭”和“吃饭不”这两个短语的意思是不同的
输入输出不定长。比如文章生成、聊天机器人
应用场景:语音识别、翻译、股价预测、行为预测
3.2 常见结构 结构一:多输入多输出
结构二:一对多,多对一
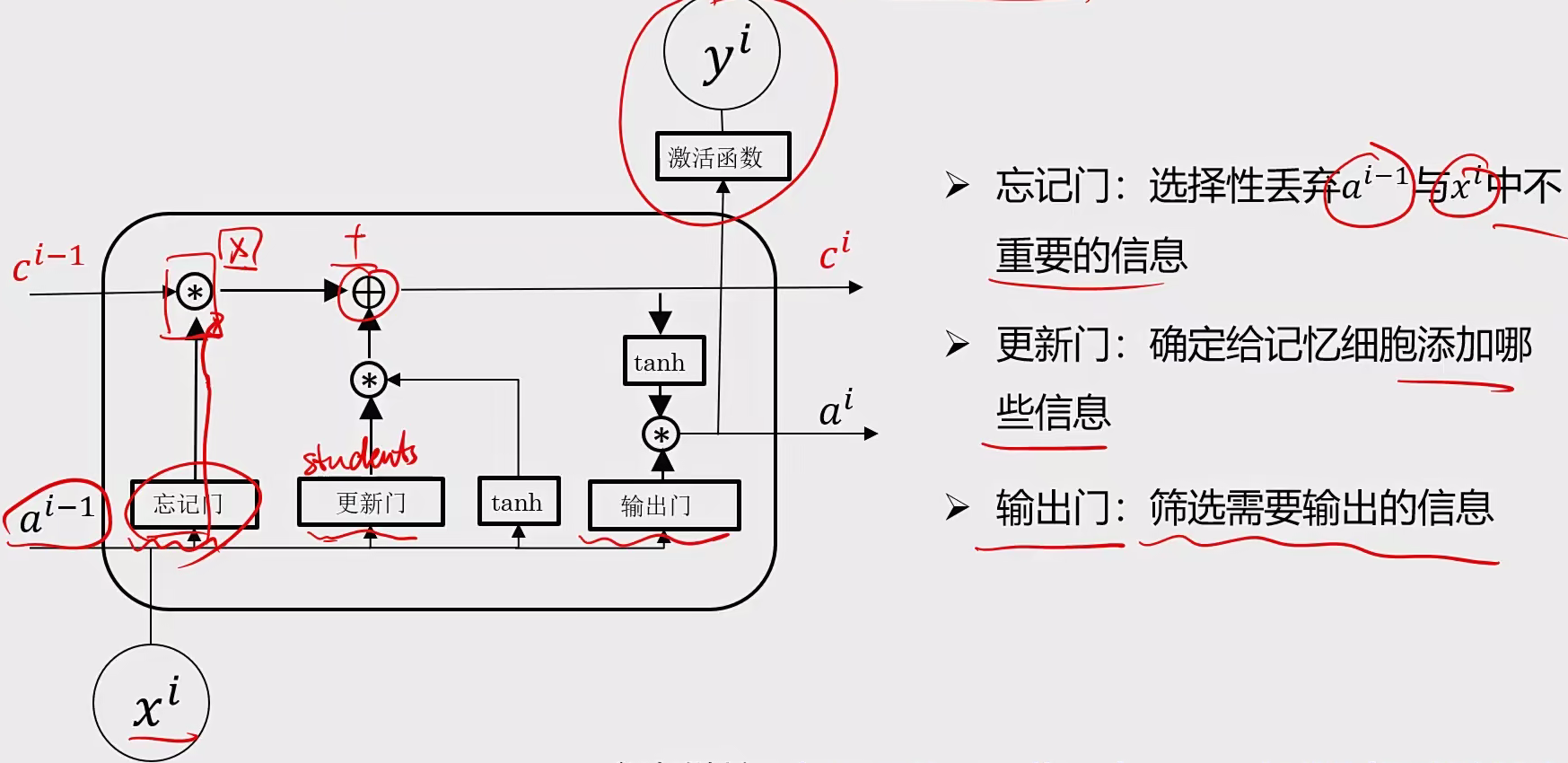
3.2 LSTM 目的:为解决前部序列信息距离远丢失信息多的问题
结构:
特点:
在网络结构很深(很多层)的情况下,也能保留重要信息;
解决了普通RNN求解过程中的梯度消失问题;解决长期依赖问题,通过引入记忆单元和门控制机制来控制信息得流动
应用场景:
语音识别、文本生成、情感分析
3.3 其他常见模型 双向循环神经网络BRNN:前后均可判断信息,提高判断得准确性
深层循环神经网络DRNN:解决更复杂的序列任务,可以把单层RNN叠起来或者在输出前和普通mlp结构结合使用
3.4 实战 3.4.1 RNN股价预测 基于zgpa_train.csv数据,建立RNN模型,预测股价:
完成数据颈处理,将序列数据转化为可用下RNN输入的数据
对新数据zgpa_test.csv进行预测,可视化结果
存储预测结果,并观察局部预测结果
模型要求:
单层RNN输出有5个神经元
每次使用前8个数据预测第9个数据
3.4.2 LSTM自动生成文本 基于flare文本数据,建立LSTM模型预测序列文字:
完成数据预处理将文字序列数据转化为可用于LSTM输入的数据
查看文字数据预处理后的数据结构,并进行数据分离操作
针对字符串输入(”flare is a teacher in AI industry. He obtained his phd in Australia.“),预测其对应的后续字符
模型结构:(单层LSTM输出有20个神经元;每次使用前20个字符预测)
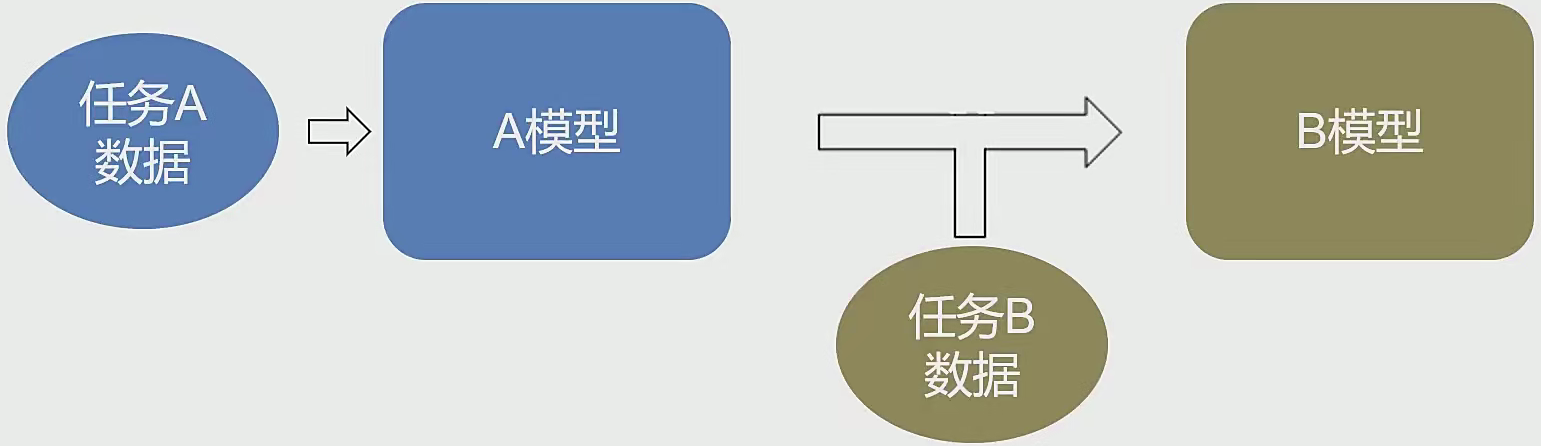
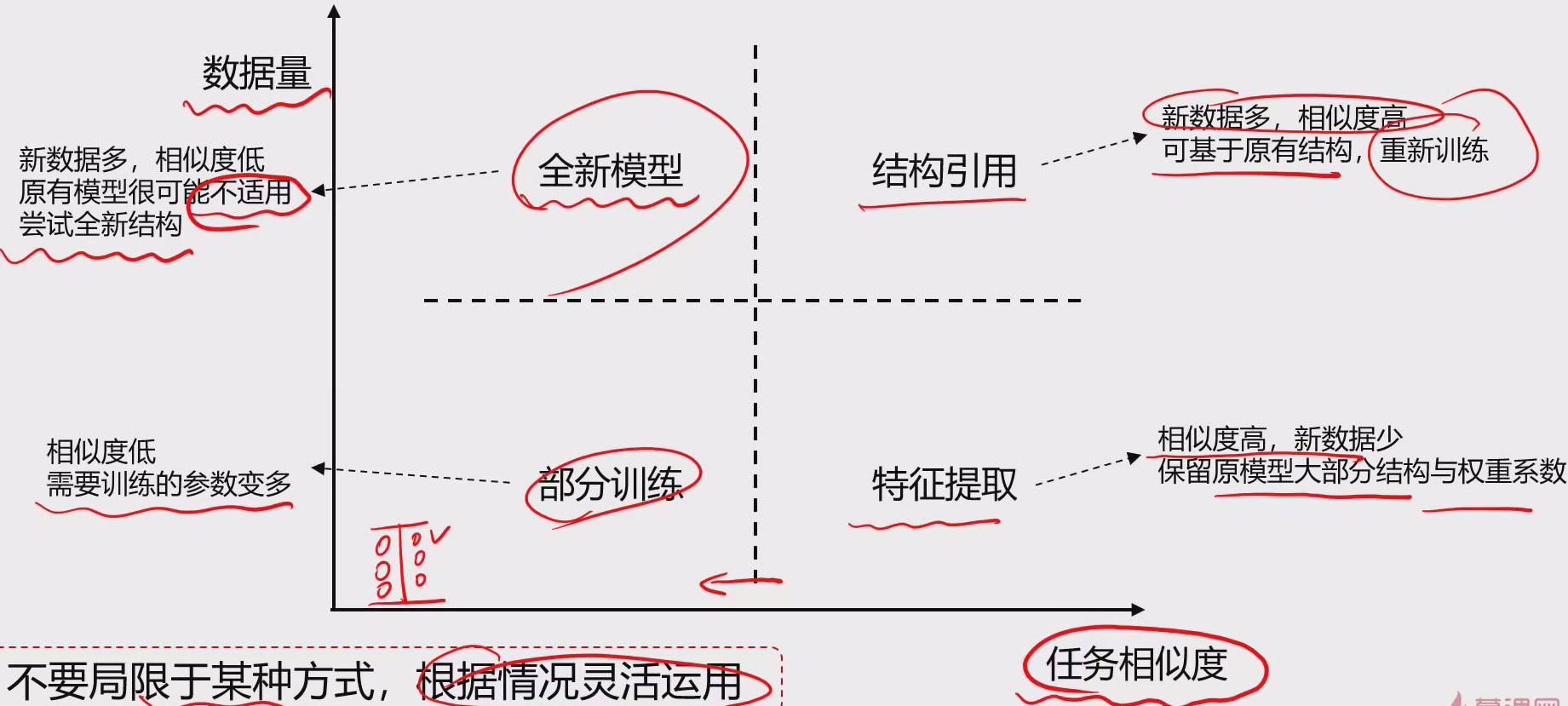
4 迁移学习 4.1 相关概念 概念:以已经训练好的模型A为起点,在新场景中,根据新数据建立模型B。
目的:将某个领域或任务上学习到的知识或模式,应用到不同但相关的领域或问题中。
英文:transfer learning
学习方式:
特征提取:使用模型A,移除输出层,提取目标特征信息
结构引用:使用模型A的结构,重新/二次训练权重系数参数
部分训练:使用模型A的结构,重新训练部分层的权重系数参数
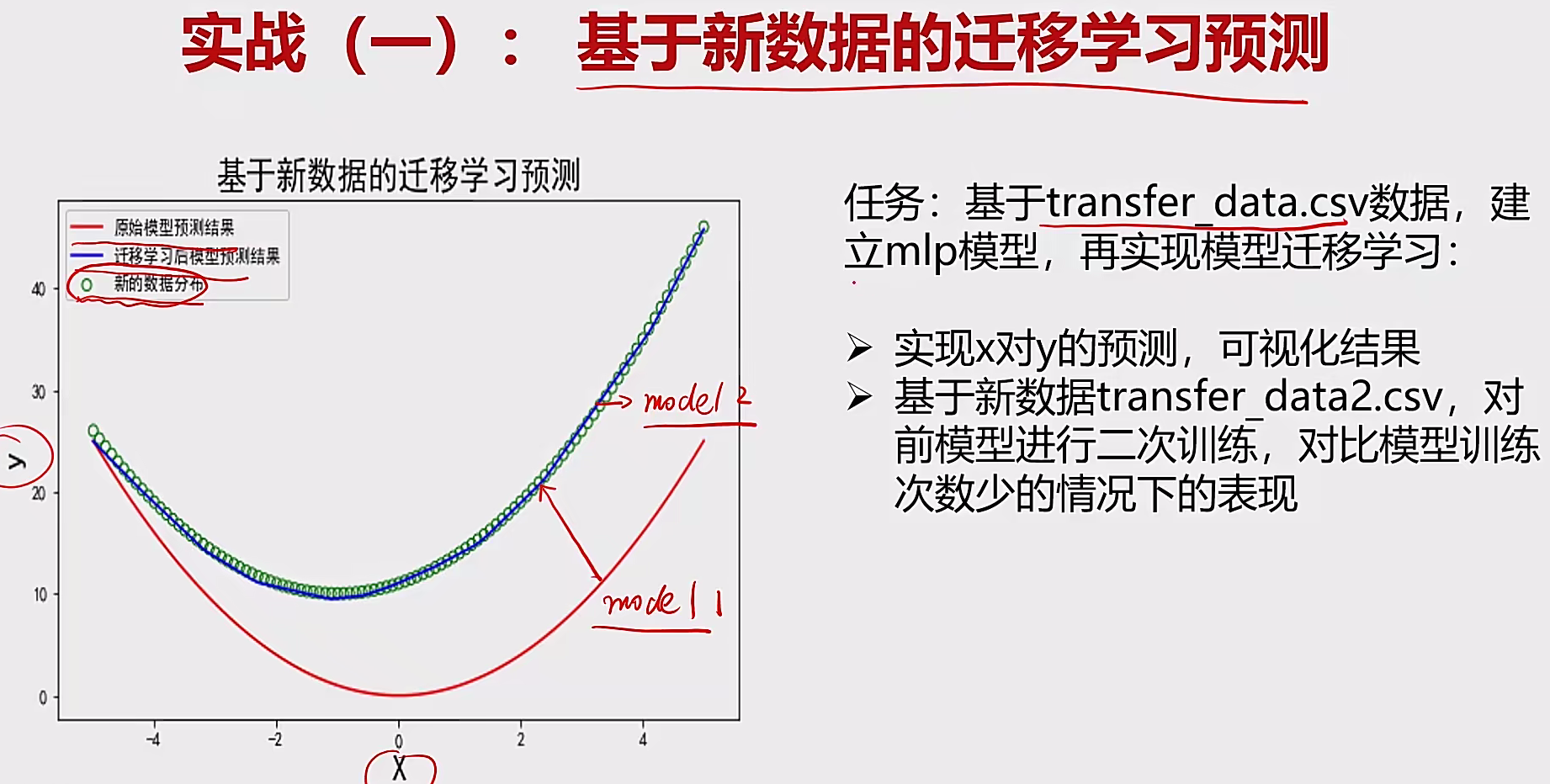
4.2 实战 4.2.1 迁移预测 要求:
模型结构:mlp
两个隐藏层,每层50个神经元,
激活函数relu,
输出层激活函数linear,
迭代次数:100次
操作:
建立MLP模型:
1 2 3 4 5 6 7 8 9 from keras.models importSequentialfrom keras.layers import Dense50 , input_dim= 1 , activation='relu' ))50 , activation='relu' ))1 , activation='linear' ))compile (optimizer='adam' ,loss='mean_squared_error' )
模型训练与二次训练:
1 2 model.fit(x,y)
模型保存到本地:
1 2 from sklearn.externals import joblib"model1.m" )
加载本地模型:
1 model2=joblib.load("model1.m" )
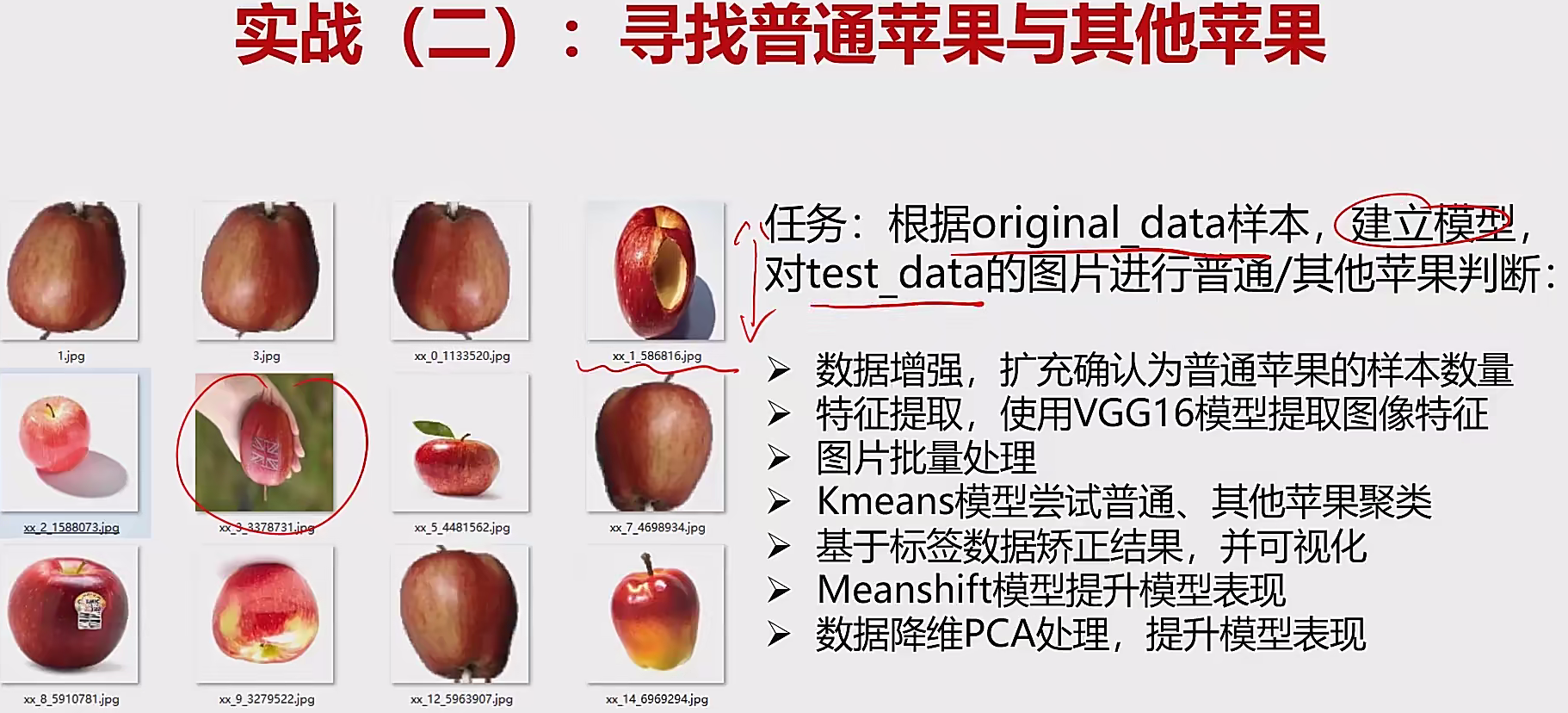
4.2.2 苹果检测 数据增强,扩充确认为普通苹果的样本数量:
1 2 3 4 5 6 7 8 9 10 from keras.preprocessing.image import ImageDataGenerator'origin_data' 'gen_data' 10 , width_shift_range=0.1 , height_shift_range=0.02 , horizontal_flip=True ,vertical_flip=True )224 , 224 ), batch_size=2 , save_to_dir=dst_path,'gen' , save_format='jpg' )for i in range (100 ):next ()
单张图片载入:
1 2 3 4 from keras.preprocessing.image import load_img,img_to_array'1.jpg' 224 ,224 ))
单张图片可视化:
1 2 3 4 5 %matplotlib inlinefrom matplotlib import pyplot as plt5 ,5 ))224 ,224 ))
单张图片特征提取:
1 2 3 4 5 6 7 8 9 10 11 12 13 from keras.applications.vgg16 import VGG16from keras.applications.vgg16 import preprocess_inputimport numpy as np'imagenet' , include_top = False )1 , 7 * 7 * 512 )
批量图片路径加载:
1 2 3 4 5 6 7 8 9 10 11 import os"train_data" for i in dirs:if os.path.splitext(i)[1 ] == ".jpg" :"//" + i for i in img_path]
定义一个提取图片特征的方法:
1 2 3 4 5 6 7 8 def modelProcess (img_path,model ):224 , 224 ))1 , 7 *7 *512 )return x_vgg
批量提取图片特征:
1 2 3 4 5 6 features1 = np.zeros([len (img_path), 7 *7 *512 ])for i in range (len (img_path)):print ('preprocessed:' , img_path[i])
KMeans聚类(2类):
1 2 3 4 from sklearn.cluster Import KMeans2 , max_iter=2000 )
Meanshift聚类:
1 2 3 4 5 6 7 from sklearn.cluster import MeanShift,estimate_bandwidth140 )
数据降维(PCA处理):
1 2 3 4 5 6 7 8 9 10 11 12 from sklearn.preprocessing import StandardScalerfrom sklearn.decomposition import PCA200 )print (np.sum (var_ratio))
统计数据次数:
1 2 from collections import Counterprint (Counter(y_pred_ms))
批量可视化结果:
1 2 3 4 5 6 7 8 plt.figure(figsize=(10 ,30 ))in range (45 ):for j in range (5 ):5 +j]) 45 , i*5 +j+1 )'apple' if y_pred_ms[i*5 + j] == normal_apple_id else 'others' )'off' )
5 在线学习 概念:给已经训练好的模型输入新的数掺,模型将进行更新适应新数据的趋势。
目的:针对新数据,在不需要对全数据集进行再次训练的基础上,实现模型更新
英文:online learning
适合场景:场景中有连续的数据流
特点:不改变模型结构,根据新数据跟新权重系数
任务:针对航空公司机票价格,在不同时期,如何确定不同的价格
五 openCV 安装 因为3.4.2之后有一些视觉申请了专利,所以我们选择安装环境版本
1 2 pip install opencv-python==3.4 .1 .15 3.4 .1 .15
安装完成之后对其检验:
1 2 3 4 5 import cv2
1 2 3 import tensorflow as tfprint (tf.__version__)print (tf.test.is_gpu_available())
1 图像处理 1.1 基本操作 数据读取-图像 :图像分为彩色、灰色图像,实际上彩色图片是分为RGB三个通道组合而成。
灰度图
cv2.IMREAD_COLOR:彩色图像
cv2.IMREAD_GRAYSCALE:灰度图像
1 2 3 4 5 6 7 import cv2 'cat.jpg' ) 'cat.jpg' , cv2.IMREAD_GRAYSCALE) 'mycat.png' , img)
数据读取-视频
cv2.VideoCapture可以捕获摄像头,用数字来控制不同的设备,例如0,1。
如果是视频文件,直接指定好路径即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vc = cv2.VideoCapture('test.mp4' )if vc.isOpened():open , frame = vc.read()else :open = False while open :if frame is None :break if ret == True :'result' , gray)if cv2.waitKey(50 ) & 0xFF == 27 :break
截取部分数据
1 2 3 img = cv2.imread('cat.jpg' )0 :200 , 0 :200 ]'cat' , cat)
边界填充
BORDER_REPLICATE:复制法,也就是复制最边缘像素。
BORDER_REFLECT:反射法,对感兴趣的图像中的像素在两边进行复制例如:fedcba|abcdefgh|hgfedcb
BORDER_REFLECT_101:反射法,也就是以最边缘像素为轴,对称,gfedcb|abcdefgh|gfedcba
BORDER_WRAP:外包装法cdefgh|abcdefgh|abcdefg
BORDER_CONSTANT:常量法,常数值填充。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import matplotlib.pyplot as plt50 , 50 , 50 , 50 )0 )231 ), plt.imshow(img, 'gray' ), plt.title('ORIGINAL' )232 ), plt.imshow(replicate, 'gray' ), plt.title('REPLICATE' )233 ), plt.imshow(reflect, 'gray' ), plt.title('REFLECT' )234 ), plt.imshow(reflect101, 'gray' ), plt.title('REFLECT_101' )235 ), plt.imshow(wrap, 'gray' ), plt.title('WRAP' )236 ), plt.imshow(constant, 'gray' ), plt.title('CONSTANT' )
数值计算 :如果加10,相当于所有均加10,超过256的数值,则需要用当前数值减去256。
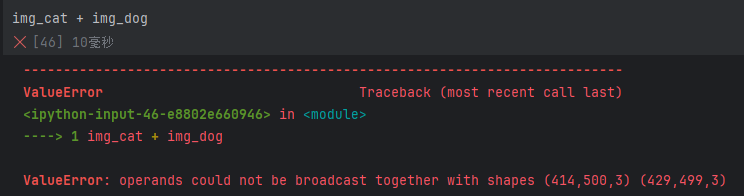
1 2 3 4 5 6 7 8 img_cat = cv2.imread('cat.jpg' )'dog.jpg' )5 , :, 0 ]10 5 , :, 0 ]
图像融合 :两个图像融合必须要shape值相同才能一一对应相加减。
1 2 3 4 5 6 7 8 9 10 11 12 13 500 , 414 ))0.4 , img_dog, 0.6 , 0 )0 , 0 ), fx=4 , fy=4 )
1.2 阈值和平滑处理 1.2.1 HSV
H - 色调(主波长)。
S - 饱和度(纯度/颜色的阴影)。
V值(强度)
1 2 3 4 5 hsv=cv2.cvtColor(img,cv2.COLOR_BGR2HSV)"hsv" , hsv)0 )
1.2.2 图像阈值 ret, dst = cv2.threshold(src, thresh, maxval, type)
dst: 输出图
src: 输入图,只能输入单通道图像,通常来说为灰度图
thresh: 阈值
maxval: 当像素值超过了阈值(或者小于阈值,根据type来决定),所赋予的值
type:二值化操作的类型,包含以下5种类型: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV
cv2.THRESH_BINARY 超过阈值部分取maxval(最大值),否则取0
cv2.THRESH_BINARY_INV THRESH_BINARY的反转
cv2.THRESH_TRUNC 大于阈值部分设为阈值,否则不变
cv2.THRESH_TOZERO 大于阈值部分不改变,否则设为0
cv2.THRESH_TOZERO_INV THRESH_TOZERO的反转
1 2 3 4 5 6 7 8 9 10 11 12 13 14 ret, thresh1 = cv2.threshold(img_gray, 127 , 255 , cv2.THRESH_BINARY)127 , 255 , cv2.THRESH_BINARY_INV)127 , 255 , cv2.THRESH_TRUNC)127 , 255 , cv2.THRESH_TOZERO)127 , 255 , cv2.THRESH_TOZERO_INV)'Original Image' , 'BINARY' , 'BINARY_INV' , 'TRUNC' , 'TOZERO' , 'TOZERO_INV' ]for i in range (6 ):2 , 3 , i + 1 ), plt.imshow(images[i], 'gray' )
1.2.3图像平滑
均值滤波:将滤波器覆盖范围内的所有像素值相加,然后除以滤波器的元素个数,得到均值并更新。
1 2 3 3 , 3 ))
方框滤波:基本和均值滤波一样,可以选择归一化(normalize=True)
1 2 1 ,(3 ,3 ), normalize=True )
1 2 1 ,(3 ,3 ), normalize=False )
高斯滤波:高斯模糊的卷积核里的数值是满足高斯分布,相当于更重视中间的(离中心越远越不重视)
1 2 3 4 5 , 5 ), 1 )
中值滤波:相当于用中值代替,即先排序,然后直接用中间的值
1 median = cv2.medianBlur(img, 5 )
上诉整合:可以看出中值滤波效果相对最好
1.3 图像形态学操作 1.3.1 腐蚀操作
腐蚀操作(Erosion) :是图像处理和计算机视觉中的一种基本的形态学操作。它主要用于减少图像中的噪声、细化图像中的对象、断开相邻的对象等。腐蚀操作通常应用于二值图像,但也可以用于灰度图像
我们可以看出相较于之前未处理的图片来说,腐蚀操作将噪声进行了处理,同时字体变小了
1.3.2 膨胀操作
**膨胀操作(Dilation):**图像处理和计算机视觉中的一种基本的形态学操作。它主要用于扩大图像中的前景对象,通常用于填补对象中的小孔洞,连接相邻的对象,或者增加对象的边界。膨胀操作通常与腐蚀操作(Erosion)结合使用,以实现更复杂的图像处理任务。
1.3.3 开运算和闭运算
**开运算:**先腐蚀,再膨胀。
**闭运算:**先膨胀,再腐蚀。
1.3.4 梯度计算 **梯度运算:**梯度=膨胀-腐蚀,可以理解为就是轮廓边缘检测。
1 2 3 4 5 6 7 8 9 'pie.png' )7 ,7 ),np.uint8)5 )5 )'res' , res)
1.3.5 礼帽与黑帽
留下的就是去除掉的噪声
去除效果不佳
1.4 图像梯度 1.4.1 sobel算子 **sobel算子:**使用两个3x3的卷积核分别在水平和垂直方向上对图像进行卷积操作,从而得到图像在两个方向上的梯度值。
1 2 3 4 1 , 0 , ksize=3 )'sobelx' )
具体实现步骤:
1 2 3 4 5 6 7 8 9 10 11 12 1 , 0 , ksize=3 )'sobelx' )0 ,1 ,ksize=3 )'sobely' )0.5 ,sobely,0.5 ,0 )'sobelxy' )
不建议直接计算,效果很差!!!
1.4.2 Scharr算子
1.4.3 laplacian算子 噪音点比较敏感
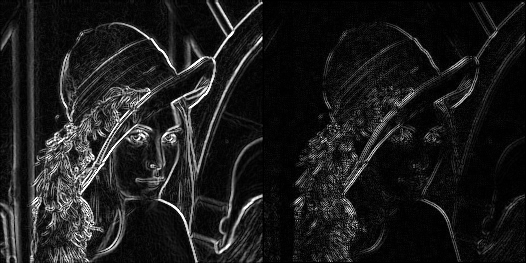
三个算子对比图(从左2至右分别是sobel、scharrx、laplacian):
1.5 边缘检测 Canny边缘检测
使用高斯滤波器,以平滑图像,滤除噪声。
计算图像中每个像素点的梯度强度和方向。
应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
通过抑制孤立的弱边缘最终完成边缘检测。
1 2 3 4 5 6 7 8 img=cv2.imread("car.png" ,cv2.IMREAD_GRAYSCALE)120 ,250 )50 ,100 )'res' )
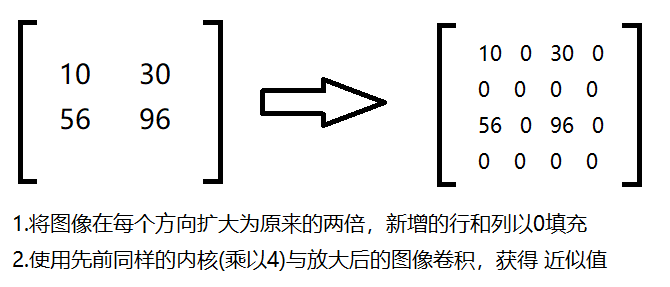
1.6 图像金字塔 1.6.1 高斯金字塔 1 高斯金字塔:向下采样方法(图像缩小,提取特征,降噪)
1 高斯金字塔:向上采样方法(图像放大,生成模型,恢复细节)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 img=cv2.imread("AM.png" )'img' )print (img.shape)'up' )print (up.shape)'down' )print (down.shape)'up2' )print (up2.shape)'up_down' )'up_down' )
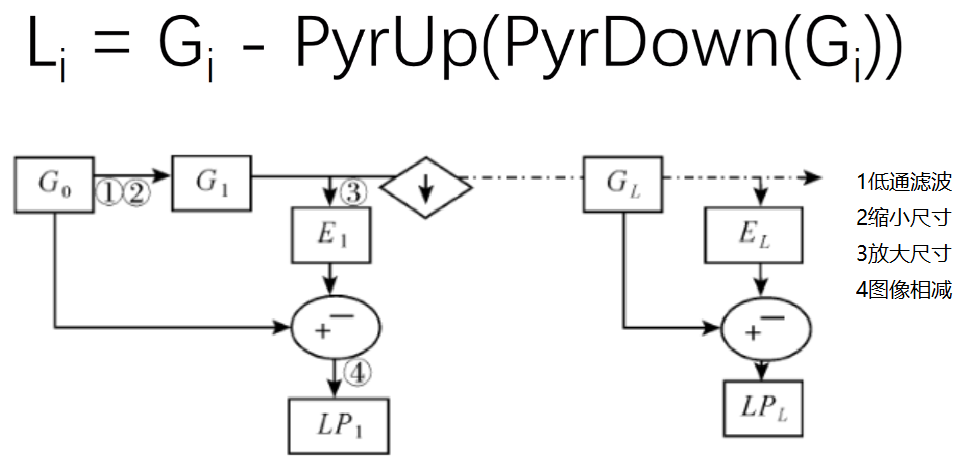
1.6.2 拉普拉斯金字塔 1 2 3 4 5 6 7 8 up=cv2.pyrUp(img)'img-up_down' )'l_1' )
1.7 图像轮廓 操作解析:
cv2.findContours(img, mode,method)
mode:轮廓检索模式
RETR_EXTERNAL :只检索最外面的轮廓;
RETR_LIST:检索所有的轮廓,并将其保存到一条链表当中;
RETR_CCOMP:检索所有的轮廓,并将他们组织为两层:顶层是各部分的外部边界,第二层是空洞的边界;
RETR_TREE:检索所有的轮廓,并重构嵌套轮廓的整个层次;
method:轮廓逼近方法
CHAIN_APPROX_NONE:以Freeman链码的方式输出轮廓,所有其他方法输出多边形(顶点的序列)。
CHAIN_APPROX_SIMPLE:压缩水平的、垂直的和斜的部分,也就是,函数只保留他们的终点部分。
1 2 3 4 5 6 7 'car.png' )127 , 255 , cv2.THRESH_BINARY)'thresh' )
绘制轮廓
1 2 3 4 5 1 , (0 , 0 , 255 ), 2 )'res' )
轮廓特征
1 2 3 4 5 6 7 8 0 ]True )
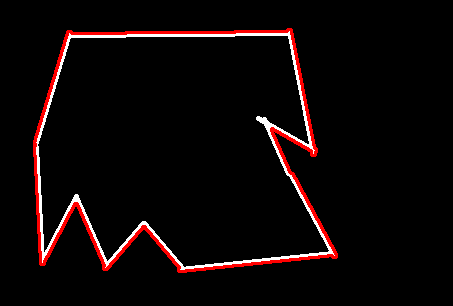
轮廓近似
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 img = cv2.imread('contours2.png' )127 , 255 , cv2.THRESH_BINARY)0 ]1 , (0 , 0 , 255 ), 2 )'res' )
1 2 3 4 5 6 7 8 9 0.1 * cv2.arcLength(cnt, True )True )1 , (0 , 0 , 255 ), 2 )'res' )
注:这个不规整主要是跟计算轮廓的0.1有关
边界矩形:
1 2 3 4 5 6 7 8 9 10 img = cv2.imread('contours.png' )127 , 255 , cv2.THRESH_BINARY)5 ]0 ,255 ,0 ),2 )'img' )
1 2 3 4 5 area = cv2.contourArea(cnt)float (area) / rect_areaprint ('轮廓面积与边界矩形比' ,extent)
输出结果:轮廓面积与边界矩形比 0.5154317244724715
外接圆
1 2 3 4 5 (x, y), radius = cv2.minEnclosingCircle(cnt)int (x), int (y))int (radius)0 , 255 , 0 ), 2 )'img' )
1.8 模板匹配
模板匹配和卷积原理很像,模板在原图像上从原点开始滑动,计算模板与(图像被模板覆盖的地方)的差别程度,这个差别程度的计算方法在opencv里有6种,然后将每次计算的结果放入一个矩阵里,作为结果输出。假如原图形是AxB大小,而模板是axb大小,则输出结果的矩阵是(A-a+1)x(B-b+1)
TM_SQDIFF:计算平方不同,计算出来的值越小,越相关
TM_CCORR:计算相关性,计算出来的值越大,越相关
TM_CCOEFF:计算相关系数,计算出来的值越大,越相关
TM_SQDIFF_NORMED:计算归一化平方不同,计算出来的值越接近0,越相关
TM_CCORR_NORMED:计算归一化相关性,计算出来的值越接近1,越相关
TM_CCOEFF_NORMED:计算归一化相关系数,计算出来的值越接近1,越相关
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 methods = ['cv2.TM_CCOEFF' , 'cv2.TM_CCOEFF_NORMED' , 'cv2.TM_CCORR' ,'cv2.TM_CCORR_NORMED' , 'cv2.TM_SQDIFF' , 'cv2.TM_SQDIFF_NORMED' ]for meth in methods:eval (meth)print (method)if method in [cv2.TM_SQDIFF, cv2.TM_SQDIFF_NORMED]:else :0 ] + w, top_left[1 ] + h)255 , 2 )121 ), plt.imshow(res, cmap='gray' )122 ), plt.imshow(img2, cmap='gray' )'w' )
匹配多个对象(超级玛丽的小金币)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 img_rgb = cv2.imread('mario.jpg' )'mario_coin.jpg' , 0 )2 ]0.8 for pt in zip (*loc[::-1 ]): 0 ] + w, pt[1 ] + h)0 , 0 , 255 ), 2 )'img_rgb' , img_rgb)0 )
1.9 直方图 cv2.calcHist(images,channels,mask,histSize,ranges)
images: 原图像图像格式为 uint8 或 float32。当传入函数时应 用中括号 [] 括来例如[img]
channels: 同样用中括号括来它会告函数我们统幅图 像的直方图。如果入图像是灰度图它的值就是 [0]如果是彩色图像 的传入的参数可以是 [0][1][2] 它们分别对应着 BGR。
mask: 掩模图像。统整幅图像的直方图就把它为 None。但是如果你想统图像某一分的直方图的你就制作一个掩模图像并使用它。
histSize:BIN 的数目。也应用中括号括来
ranges: 像素值范围常为 [0, 256]
直方图均衡化:
1 2 3 img = cv2.imread('clahe.jpg' ,0 ) 256 )
1 2 3 equ = cv2.equalizeHist(img) 256 )
1.10 傅里叶变换
我们生活在时间的世界中,早上7:00起来吃早饭,8:00去挤地铁,9:00开始上班。。。以时间为参照就是时域分析。
但是在频域中一切都是静止的!
https://zhuanlan.zhihu.com/p/19763358
傅里叶变换的作用
高频:变化剧烈的灰度分量,例如边界
低频:变化缓慢的灰度分量,例如一片大海
滤波
低通滤波器:只保留低频,会使得图像模糊
高通滤波器:只保留高频,会使得图像细节增强
操作流程:
opencv中主要就是cv2.dft()和cv2.idft(),输入图像需要先转换成np.float32 格式。
得到的结果中频率为0的部分会在左上角,通常要转换到中心位置,可以通过shift变换来实现。
cv2.dft()返回的结果是双通道的(实部,虚部),通常还需要转换成图像格式才能展示(0,255)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import numpy as npimport cv2from matplotlib import pyplot as plt'lena.jpg' , 0 )20 * np.log(cv2.magnitude(dft_shift[:, :, 0 ], dft_shift[:, :, 1 ]))121 ), plt.imshow(img, cmap='gray' )'Input Image' , c='w' ), plt.xticks([]), plt.yticks([])122 ), plt.imshow(magnitude_spectrum, cmap='gray' )'Magnitude Spectrum' , c='w' ), plt.xticks([]), plt.yticks([])
上面输出的图片中,input Image由 dft 变换后的图片,Magnitude Spectrum是频谱图
Magnitude Spectrum由 idft 可转化为input Image
低通滤波:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import numpy as npimport cv2from matplotlib import pyplot as plt'lena.jpg' , 0 )int (rows / 2 ), int (cols / 2 )2 ), np.uint8)30 :crow + 30 , ccol - 30 :ccol + 30 ] = 1 0 ], img_back[:, :, 1 ]) 121 ), plt.imshow(img, cmap='gray' )'Input Image' , c='w' ), plt.xticks([]), plt.yticks([])122 ), plt.imshow(img_back, cmap='gray' )'Result' , c='w' ), plt.xticks([]), plt.yticks([])
高通滤波:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 img = cv2.imread('lena.jpg' , 0 )int (rows / 2 ), int (cols / 2 ) 2 ), np.uint8)30 :crow + 30 , ccol - 30 :ccol + 30 ] = 0 0 ], img_back[:, :, 1 ])121 ), plt.imshow(img, cmap='gray' )'Input Image' , c = 'w' ), plt.xticks([]), plt.yticks([])122 ), plt.imshow(img_back, cmap='gray' )'Result' , c = 'w' ), plt.xticks([]), plt.yticks([])
总结
因为在频域中,我们可以很容易的分离出图像的高频和低频部分,然后通过滤波的方式,去除图像中的噪声,或者是增强图像的细节。
这样的方式更加的高效,而且更加的方便。
2 背景建模 帧差法
由于场景中的目标在运动,目标的影像在不同图像帧中的位置不同。该类算法对时间上连续的两帧图像 进行差分运算 ,不同帧对应的像素点相减,判断灰度差的绝对值,当绝对值超过一定阈值时,即可判断为运动目标,从而实现目标的检测功能。
帧差法非常简单,但是会引入噪音和空洞问题
3 label标注
安装:pip install labelme
启动:labelme
六 爬虫相关 1 正则表达式 Regular Expression,正则表达式,一种使用表达式的方式对字符串进行匹配的语法规则。
正则的语法:
使用元字符进行排列组合用来匹配字符串,在线测试正则表达式
元字符:具有固定含义的特殊符号
常用元字符:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 . 匹配除换行符以外的任意字符
量词:控制前面的元字符出现的次数
1 2 3 4 5 6 * 重复零次或更多次+ 重复一次或更多次
贪婪匹配和惰性匹配
2 re模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import re""" <div class='jay'><span id='1'>郭麒麟</span></div> <div class='jj'><span id='2'>宋铁</span></div> <div class='join'><span id='3'>大聪明</span></div> <div class='solar'><span id='4'>范思哲</span></div> <div class='tory'><span id='5'>胡说八道</span></div> """ compile (r"<div class='(?P<class>.*?)'><span id='(?P<id>\d+)'>(?P<name>.*?)</span></div>" , re.S)for item in obj.finditer(s):print (item.group("class" ))print (item.group("id" ))print (item.group("name" ))
3 request模块 3.1 人名搜索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import requestsdef get_html (url ):'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36' return resp.textinput ("请输入你想查询的人名:" )f'https://www.sogou.com/web?query={query} ' print (get_html(url))
3.2 百度翻译 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import requests'https://fanyi.baidu.com/sug' input ("请输入你想查询的单词:" )'kw' : queryprint (resp.json())
3.3 豆瓣电影 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import requests'https://movie.douban.com/j/chart/top_list' "type" : "24" ,"interval_id" : "100:90" ,"action" : "" ,"start" : 0 ,"limit" : 20 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36' print (resp.request.headers)print (resp.json())open ('movie.txt' , 'w' , encoding='utf-8' ).write(resp.text)print ("ok" )
4 实战模块 4.1 bs4图片下载 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import requests'https://movie.douban.com/j/chart/top_list' "type" : "24" ,"interval_id" : "100:90" ,"action" : "" ,"start" : 0 ,"limit" : 20 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36' print (resp.request.headers)print (resp.json())open ('movie.txt' , 'w' , encoding='utf-8' ).write(resp.text)print ("ok" )
4.2 盗版天堂 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 import requestsimport re'https://www.dytt8899.com/' 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/135.0.0.0 Safari/537.36 Edg/135.0.0.0' False ) 'gb2312' compile (r"2025必看热片.*?<ul>(?P<content>.*?)</ul>" , re.S)compile (r"<a href='(?P<href>.*?)'" , re.S)compile (r'◎片 名(?P<name>.*?)<br />.*?<td ' r'style="WORD-WRAP: break-word" bgcolor="#fdfddf"><a href="(?P<download>.*?)"' , re.S)for item in res:"content" )for movie_item in movie_url:"href" ).strip("/" )for child_url in child_href_list:False )'gb2312' with open ("看片爬虫.csv" , "a" , encoding="gb2312" ) as f:"name" ) + "," + result.group("download" ) + "\n" )