一 基础语法 1 基本操作 输出:
1 2 3 4 print ("每日增长系数:%.1f,经过%d天的增长后,股价达到了:%0.2f" % (stock_price_daily_growth_factor, print (f"公司:{name} ,股票代码:{stock_code} ,当前股价:{stock_price} " )
输入:input()
1 2 name = input ("请告诉我你是谁?\n" )print (f"我知道了,你是:{name} " )
变量类型查看:type(num)
注释:
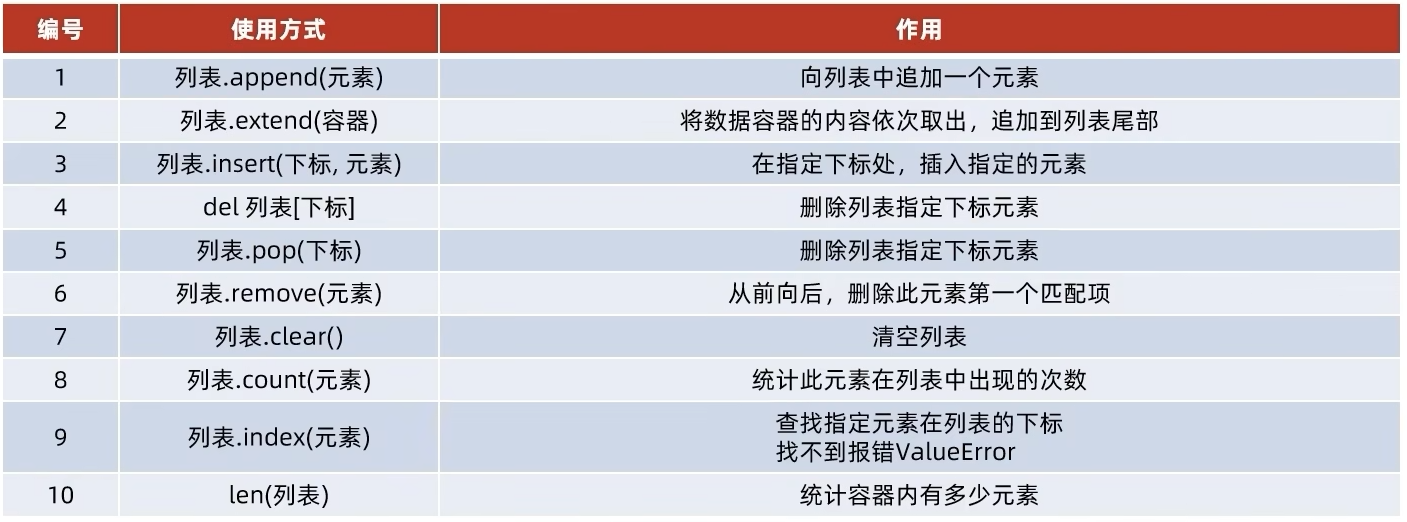
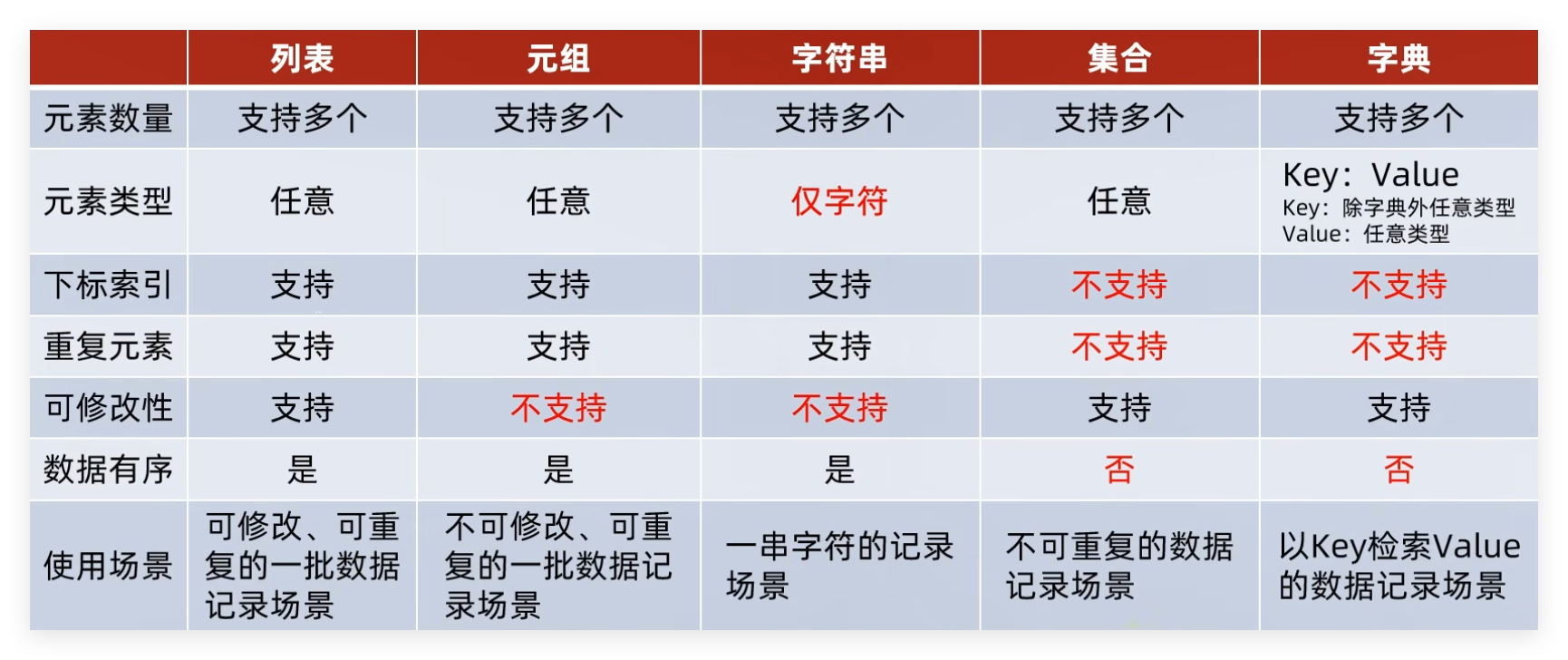
2 数据容器 2.1 列表 2.2 元组 元组如下特点:
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是有序存储的(下标索引)
允许重复数据存在
不可以修改(增加或删除元素等 )支持for循环
多数特性和list一致,不同点在于不可修改的特性
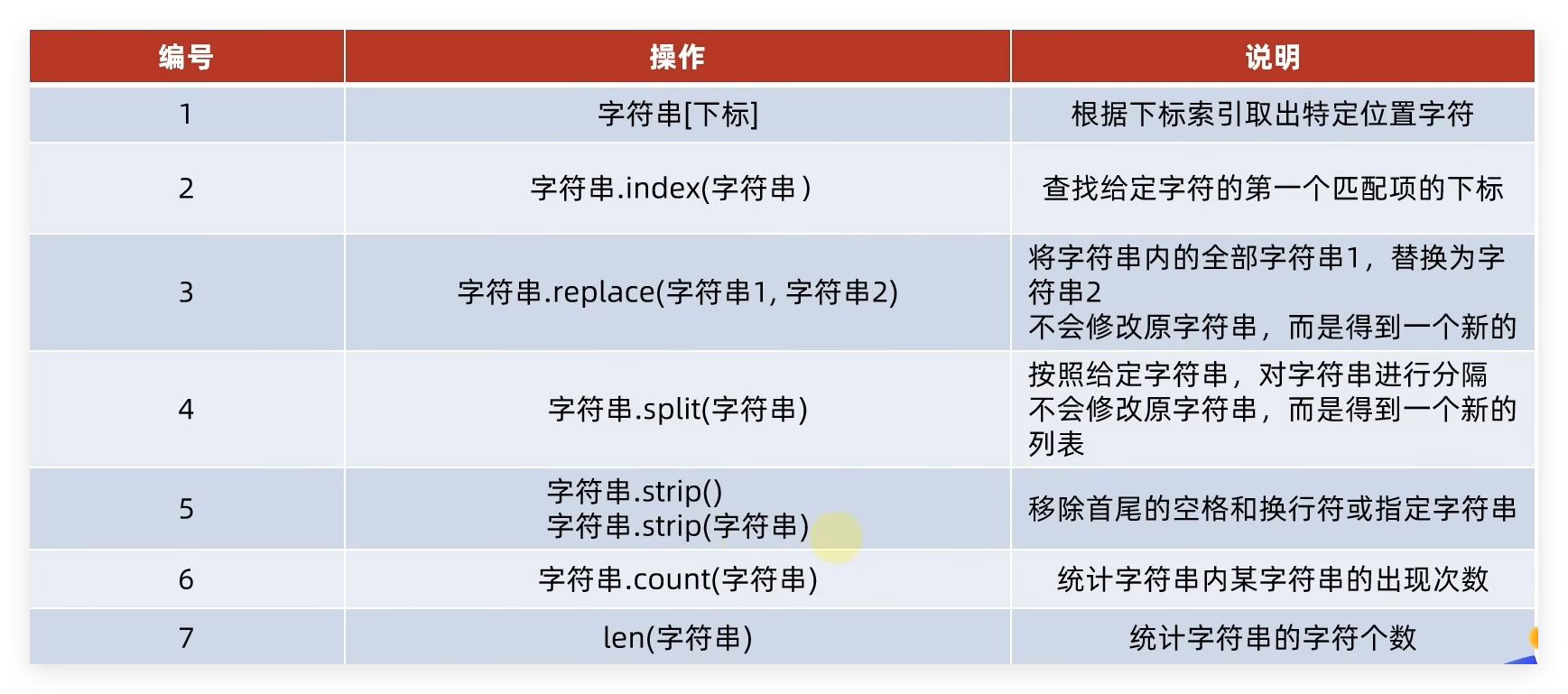
2.3 字符串 字符串常用操作 :
作为数据容器,字符串有如下特点:
只可以存储字符串
长度任意(取决于内存大小)
支持下标索引
允许重复字符串存在
不可以修改(增加或删除元素等) 支持for循环
序列的操作——切片
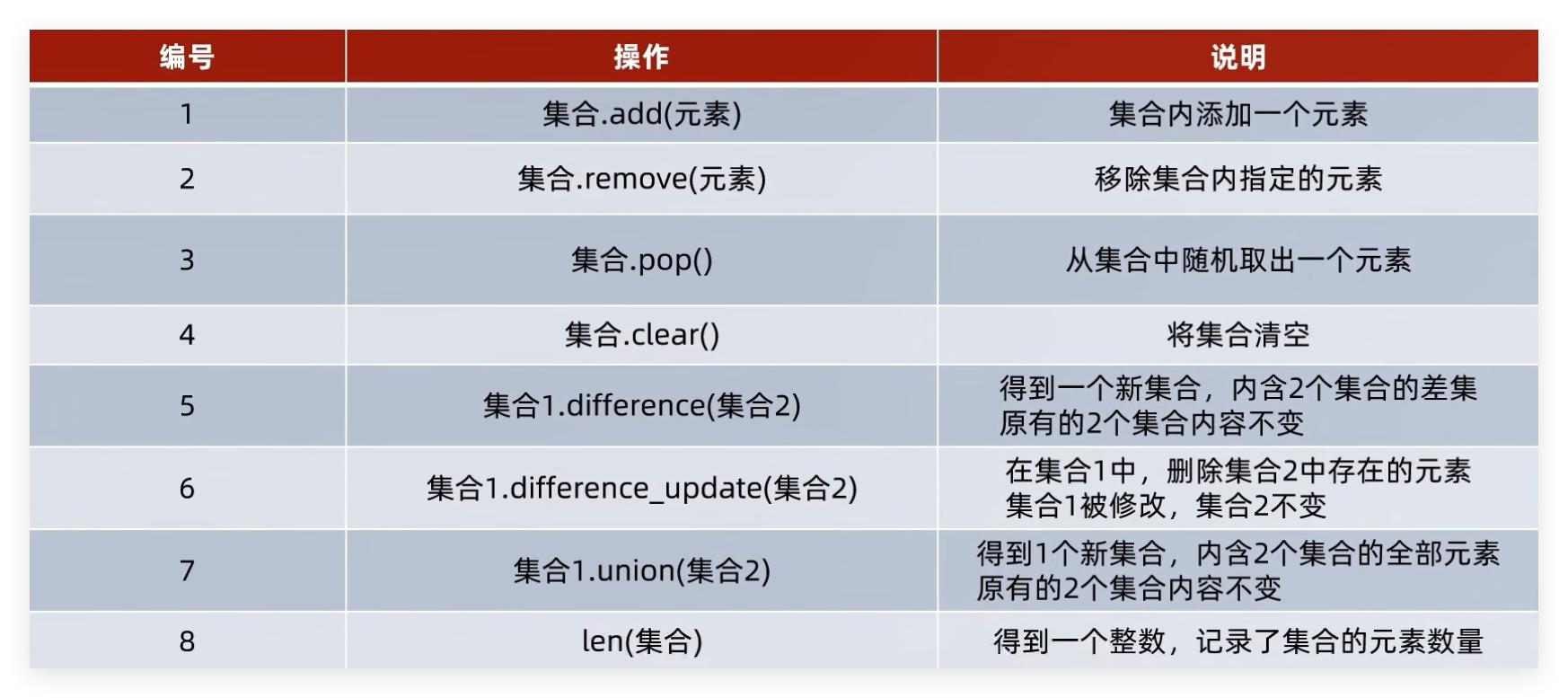
2.4 集合 特点:
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是无序存储的(不支持下标索引) 不允许重复数据存在 可以修改(增加或删除元素等)
支持for循环
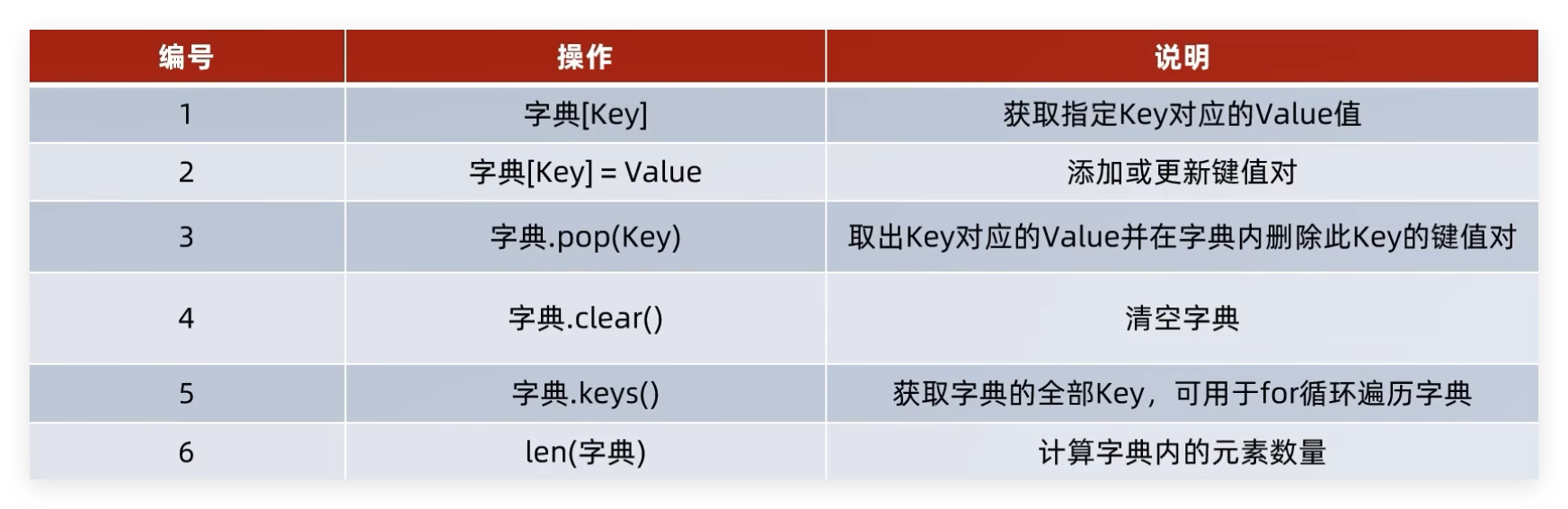
2.5 字典 特点:
可以容纳多个数据
可以容纳不同类型的数据
每一份数据是KeyValue键值对
可以通过Key获取到Value,Key不可重复(重复会覆盖)
不支持下标索引
可以修改(增加或删除更新元素等)
支持for循环,不支持while循环
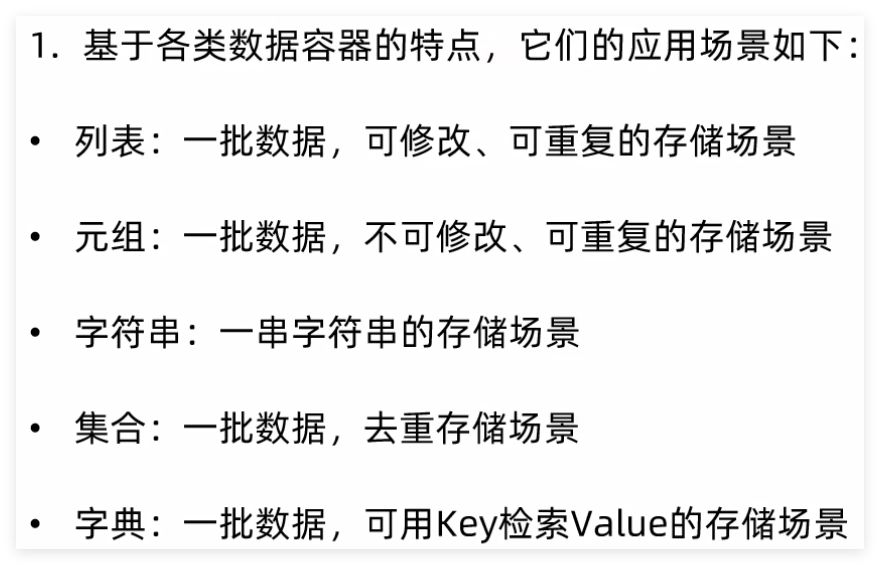
3 数据容器特点对比 数据容器可以从以下视角进行简单的分类:
是否支持下标索引
支持:列表、元组、字符串-序列类型
不支持:集合、字典-非序列类型
是否支持重复元素
支持:列表、元组、字符串-序列类型
不支持:集合、字典-非序列类型
是否可以修改
使用场景:
sorted(容器,[reverse = True])
4 函数操作 4.1 多种参数使用形式 1 2 3 4 def user_info (name, age, gender ):print (f'您的姓名是{name} ,年龄是:{age} ,性别是:{gender} ' )"tom" , 20 , "男" )
位置参数不定长 :传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
1 2 3 4 def user_info (*args ):print (args)"tom" , 20 , "男" )
关键字参数不定长 :参数是“键=值”形式的形式的情况下,所有的“键=值”都会被kwargs接受,同时会根据“键=值”组成字典
1 2 3 4 5 def user_info3 (**kwargs ):print (kwargs)"tom" , age=20 , gender="男" )
4.2 匿名函数 4.2.1 函数作为参数传递 1 2 3 4 5 6 7 8 9 10 11 12 13 14 def test_func (mult_func ):2 , 2 )print (f"计算的结果是:{result} " )def mult_func (x, y ):return x * y
4.2.2 lambda函数 函数的定义中
def键字,可以定义带有名称的函数
lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用
无名称的匿名函数,只可临时使用一次 。
匿名函数定义语法:
lambda 是关键字,表示定义匿名函数
传入参数表示匿名函数的形式参数,如:x,y表示接收2个形式参数
函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码
1 2 3 4 5 6 7 8 def test_func (mult_func ):2 , 2 )print (f"计算的结果是:{result} " )lambda x, y: x * y)
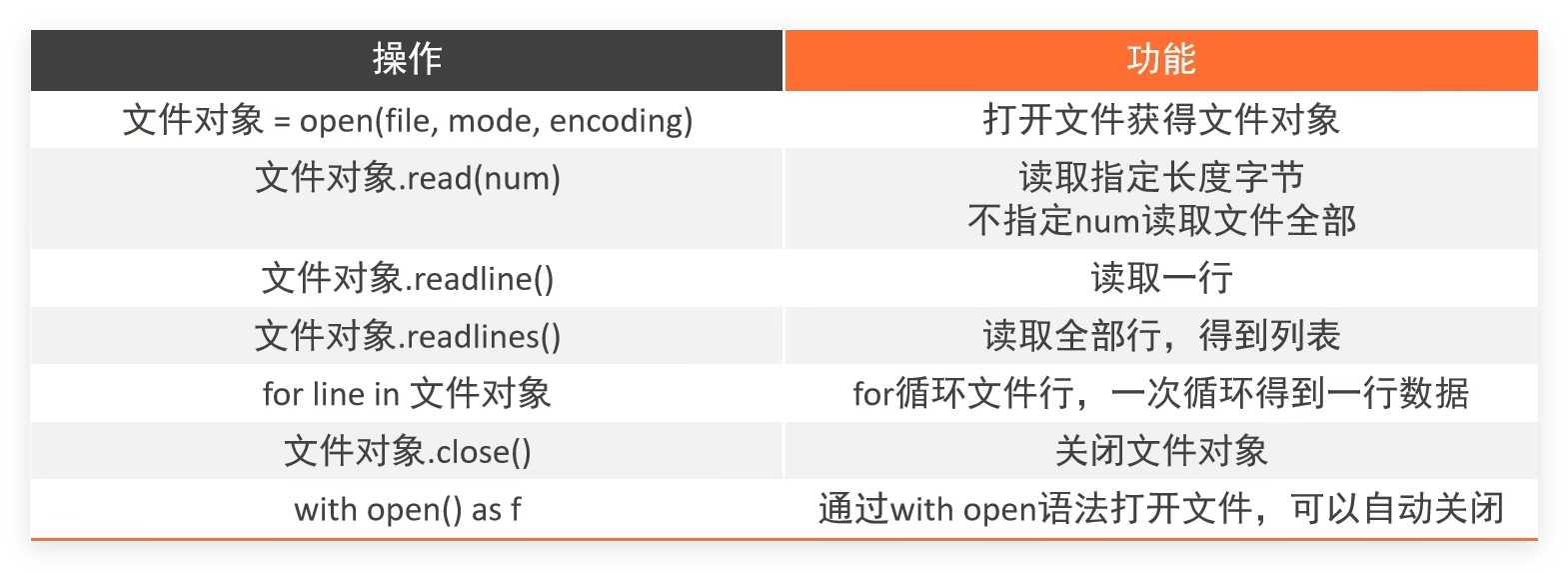
二 文件操作 2.1 基本概念 在Python,使用open函数,可以打开一个已经存在的文件,或者创建一个新文件,语法如下:
1 open (name,mode,encoding)
name:是要打开的目标文件名的字符串(可以包含文件所在的具体路径)。
mode:设置打开文件的模式(访问模式):只读、写入、追加等。
encoding:编码格式(推荐使用UTF-8)
示例代码:
1 2 f = open ('python.txt' ,'r' ,encoding="UTF-8" )
2.2 读取相关操作 read()方法:
num表示要从文件中读取的数据的长度(单位是字节),如果没有传入num,那么就表示读取文件中所有的数据
readlines()方法:
readlines可以按照行的方式把整个文件中的内容进行一次性读取,并且返回的是一个列表,其中每一行的数据为一个元素。
1 2 3 4 with open ("python.txt" , "r" ) as f:
2.3 写入相关操作 覆盖用w
2.写入的方法有:
wirte(),写入内容
flush(),刷新内容到硬盘中
3.注意事项:
w模式,文件不存在,会创建新文件
w模式,文件存在,会清空原有内容
close()方法,带有flush()方法的功能
追加用a
三 异常 3.1 异常概念
捕获异常的作用在于:提前假设某处会出现异常,做好提前准备,当真的出现异常的时候,可以有后续手段。
1 2 3 4 try :print (name)except NameError as e:print ('name变量名称未定义错误' )
异常的finally
finally表示的是无论是否异常都要执行的代码,例如关闭文件。
1 2 3 4 5 6 7 8 try :open ('test.txt' , 'r' )except Exception as e:open ('test.txt' , 'w' )else :print ('没有异常,真开心' )finally :
异常的传递
异常是具有传递性的
当函数func01 中发生异常,并且没有捕获处理这个异常的时候,异常会传递到函数func02 ,当func02也没有捕获处理这个异常的时候main函数会捕获这个异常,这就是异常的传递性
提示:当所有函数都没有捕获异常的时候,程序就会报错
3.2 模块
什么是模块?
Python 模块(Module),是一个Python 文件,以.py 结尾。模块能定义函数,类和变量,模块里也能包含可执行的代码
模块的作用 :python中有很多各种不同的模块,每一个模块都可以帮助我们快速的实现一些功能,比如实现和时间相关的功能就可以使用time模块。我们可以认为一个模块就是一个工具包,每一个工具包中都有各种不同的工具供我们使用进而实现各种不同的功能。
大白话:模块就是一个Python文件,里面有类、函数、变量等,我们可以拿过来用(导入模块去使用)
1 2 3 4 5 6 7 8 from 模块名] import [模块 | 类 | 变量 | 函数 |*][as 别名]import 模块名from 模块名 import 类、变量、方法等from 模块名 import *import 块名 as 别名from 模块名 import 功能名 as 别名
name__main变量使用
if name main
03_my_module_use.py
1 2 3 import my_moduleprint (my_module.add(1 , 4 ))
my_module.py
1 2 3 4 5 def add (a, b ):return a + bif __name__ == '__main__' :print (add(7 , 2 ))
3.3 Python包 3.3.1 自定义包 创建包必须要有文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 """ 演示python包 """ from my_package import *
3.3.2 安装第三方包 什么是第三方包?
我们知道,包可以包含一堆的Python模块,而每个模块又内含许多的功能。所以,我们可以认为:一个包,就是一堆同类型功能的集合体。在Python程序的生态中,有许多非常多的第三方包(非Pvthon官方),可以极大的帮助我们提高开发效率,如:
科学计算中常用的:numpy包
数据分析中常用的:pandas包
大数据计算中常用的:pyspark、apache-flink包
图形可视化常用的:matplotlib、pyecharts
人工智能常用的:tensorflow
这些第三方包,极大的丰富了python的编程生态,提高了我们的开发效率
安装方法:
由于pip是连接的国外的网站进行包的下载,所以有的时候会速度很慢我们可以通过如下命令,让其连接国内的网站进行包的安装:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple 包名称
pip install 包名称
四 可视化 4.1 基本介绍 4.1.1 json数据格式
json :是一种轻量级的数据交互格式,采用完全独立于编程语言的文本格式来存储和表示数据(就是字符串)
Python语言使用ISON有很大优势,因为:JSON无非就是一个单独的字典或一个内部元素都是字典的列表,所以JSON可以直接和
Python的字典或列表进行无缝转换。
json格式数据转化
通过 json.dumps(data)方法把python数据转化为了 json数据
data= json.dumps(data)
如果有中文可以带上:ensure ascii-False参数来确保中文正常转换通过json.loads(data)方法把josn数据转化为了python列表或字典
4.1.2 pyecharts模块介绍 Echarts 是个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是门富有表达立的语言,很适合用于数据处理。当数据分析遇上数据可视化时pyecharts 诞生了
set _global opts方法(全局配置)
1 2 3 4 5 6 7 line.set_global_opts("测试" , pos_left = "center" , pos_bottom = "1%" ),True ),True )True )True ),
4.2 折线图可视化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 """ 演示可视化需求1:折线图开发 """ import jsonfrom pyecharts.charts import Linefrom pyecharts.options import *open ("utils/美国.txt" , "r" , encoding="utf-8" )open ("utils/日本.txt" , "r" , encoding="utf-8" )open ("utils/印度.txt" , "r" , encoding="utf-8" )"jsonp_1629344292311_69436(" , "" )"jsonp_1629350871167_29498(" , "" )"jsonp_1629350745930_63180(" , "" )2 ]2 ]2 ]'data' ][0 ]['trend' ]'data' ][0 ]['trend' ]'data' ][0 ]['trend' ]'updateDate' ][:314 ]'updateDate' ][:314 ]'updateDate' ][:314 ]'list' ][0 ]['data' ][:314 ]'list' ][0 ]['data' ][:314 ]'list' ][0 ]['data' ][:314 ]"美国确诊人数" , us_y_data, label_opts=LabelOpts(is_show=False ))"日本确诊人数" , jp_y_data, label_opts=LabelOpts(is_show=False ))"印度确诊人数" , in_y_data, label_opts=LabelOpts(is_show=False ))"2020年美日印三国确诊人数对比折线图" , pos_left="center" , pos_bottom='1%' )"03_折线图.html" )
4.3 地图可视化 地图现在版本更新必须将其补全
4.3.1 全国地图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 """ @Project :pythonProject @File :05_全国疫情可视化地图开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/23 19:45 """ import jsonfrom pyecharts.charts import Mapfrom pyecharts.options import TitleOpts, VisualMapOptsimport jsonimport oswith open ("疫情.txt" , "r" , encoding="utf-8" ) as f:"lastUpdateTime" ]str (lastUpdateTime)'chinaTotal' ]"chinaAdd" ]"isShowAdd" ],print (isShowAdd)"showAddSwitch" ],"areaTree" ][0 ]["children" ]for province in province_list:if province["name" ] in ["北京" , "上海" , "天津" , "重庆" ]:"name" ] += "市" elif province["name" ] in ["香港" , "澳门" , ]:"name" ] += "特别行政区" elif province["name" ] in ["内蒙古" , "西藏" ]:"name" ] += "自治区" elif province["name" ] == "广西" :"name" ] = "广西壮族自治区" elif province["name" ] == "新疆" :"name" ] = "新疆维吾尔自治区" elif province["name" ] == "宁夏" :"name" ] = "宁夏回族自治区" else :"name" ] += "省" "lastUpdateTime" : lastUpdateTime,"chinaTotal" : chinaTotal,"chinaAdd" : chinaAdd,"isShowAdd" : isShowAdd,"showAddSwitch" : showAddSwitch,"areaTree" : [data["areaTree" ][0 ]]"areaTree" ][0 ]["children" ] = province_listFalse , indent=4 )with open ("疫情.txt" , "w" , encoding="utf-8" ) as f:
完成前期准备工作之后:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 """ @Project :pythonProject @File :05_全国疫情可视化地图开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/23 19:45 """ import jsonfrom pyecharts.charts import Mapfrom pyecharts.options import TitleOpts, VisualMapOptsopen ("utils/疫情.txt" , "r" , encoding="utf-8" )"areaTree" ][0 ]["children" ]for province_data in province_data_list:"name" ]"total" ]["confirm" ]print (data_list)map = Map()map .add("各省份确诊人数" , data_list, "china" )map .set_global_opts("全国疫情可视化地图" ),True ,True ,"min" : 1 , "max" : 99 , "label" : "1-99人" , "color" : "#CCFFFF" },"min" : 100 , "max" : 999 , "label" : "100-999人" , "color" : "#FFFF99" },"min" : 1000 , "max" : 4999 , "label" : "1000-4999人" , "color" : "#FF9966" },"min" : 5000 , "max" : 9999 , "label" : "5000-9999人" , "color" : "#FF6666" },"min" : 10000 , "max" : 99999 , "label" : "10000-99999人" , "color" : "#CC3333" },"min" : 100000 , "label" : "10000人以上" , "color" : "#990033" },map .render("05_全国疫情可视化地图.html" )
4.3.2 省级地图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 """ @Project :pythonProject @File :06_省级疫情可视化开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/25 15:38 """ import jsonfrom pyecharts.charts import Mapfrom pyecharts.options import *open ("../utils/疫情.txt" , "r" , encoding="UTF-8" )"areaTree" ][0 ]["children" ][1 ]["children" ]for city_data in cities_data:"name" ] + "市" "total" ]["confirm" ]map = Map()map .add("江苏省疫情分布" , data_list, "江苏" ).set_global_opts("全国疫情可视化地图" ),True ,True ,"min" : 1 , "max" : 9 , "label" : "1-9人" , "color" : "#CCFFFF" },"min" : 10 , "max" : 99 , "label" : "10-99人" , "color" : "#FFFF99" },"min" : 100 , "max" : 199 , "label" : "100-199人" , "color" : "#FF9966" },"min" : 200 , "max" : 299 , "label" : "200-299人" , "color" : "#FF6666" },"min" : 300 , "max" : 399 , "label" : "300-399人" , "color" : "#CC3333" },"min" : 400 , "label" : "400人以上" , "color" : "#990033" },map .render("06_省级疫情可视化开发.html" )
4.4 柱状图 4.4.1 基础柱状图 设置步骤:
通过Bar()构建一个柱状图对象
和折线图一样,通过add_xaxis()和add_yaxis()添加x和y轴数据
通过柱状图对象的:reversal_axis(),反转x和y轴
通过label_opts=LabelOpts(position=”right”)设置数值标签在右侧显示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 """ @Project :pythonProject @File :07_基础柱状图开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/25 16:57 """ from pyecharts.charts import Barfrom pyecharts.options import *"英国" , "美国" , "中国" ])"GDP" , [100 , 200 , 300 ], label_opts=LabelOpts(position="right" ), color="#990033" )"07_基础柱状图.html" )
4.4.2 基础时间柱状图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 """ @Project :pythonProject @File :08_基础时间线柱状图开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/25 17:45 """ from pyecharts.charts import *from pyecharts.options import *from pyecharts.globals import *"英国" , "美国" , "中国" ])"GDP" , [10 , 20 , 80 ], label_opts=LabelOpts(position="right" ))"英国" , "美国" , "中国" ])"GDP" , [40 , 50 , 90 ], label_opts=LabelOpts(position="right" ))"英国" , "美国" , "中国" ])"GDP" , [70 , 100 , 200 ], label_opts=LabelOpts(position="right" ))"theme" : ThemeType.LIGHT}"2017年" )"2018年" )"2019年" )True ,1000 ,True ,True "08_基础时间线柱状图.html" )
4.4.3 动态图绘制 列表的sort方法
使用方式:
列表.sort(key=选择排序依据的函数,reverse=TruelFalse)
参数key,是要求传入一个函数,表示将列表的每一个元素都传入函数中,返回排序的依据
参数reverse,是否反转排序结果,True表示降序,False表示升序
python版本3.7之后字典就开始排序了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 """ @Project :pythonProject @File :10_GDP动态柱状图开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/25 18:25 """ from pyecharts.charts import Bar, Timelinefrom pyecharts.options import *from pyecharts.globals import ThemeTypeopen ("../utils/1960-2019全球GDP数据.csv" , "r" , encoding="GB2312" )0 )for line in data_lines:int (line.split("," )[0 ])"," )[1 ]float (line.split("," )[2 ])try :except KeyError:"theme" : ThemeType.LIGHT})for year in data_dict.keys():lambda element: element[1 ], reverse=True )0 :8 ]for element in data_year:0 ])1 ] / 1000000000 )"GDP(亿)" , y_data, label_opts=LabelOpts(position="right" ))f"{year} 年全球前8国家GDP数据" )str (year))1000 ,True ,True ,True "10_1960-2019全球GDP前8国家.html" )
五 面向对象 5.1 基本概念 5.1.1 成员变量 1 2 3 4 5 6 7 class student :None None def say_hi (self, msg ):print (f"Hi大家好,我是{self.name} ,{msg} " )
5.1.2 类、对象和构造方法 类、对象:
1.现实世界的事物由什么组成?
类也可以包含属性和行为,所以使用类描述现实世界事物是非常合适的
构造方法:
Python类可以使用: –init–()方法,称之为构造方法。
可以实现:
在创建类对象(构造类)的时候,会自动执行
在创建类对象(构造类)的时候,将传入参数自动传递给 init 方法使用。
1 2 3 4 5 6 7 8 9 class Student :None None None def __init__ (self, name, age, tel ):self .name = nameself .age = ageself .tel =tel
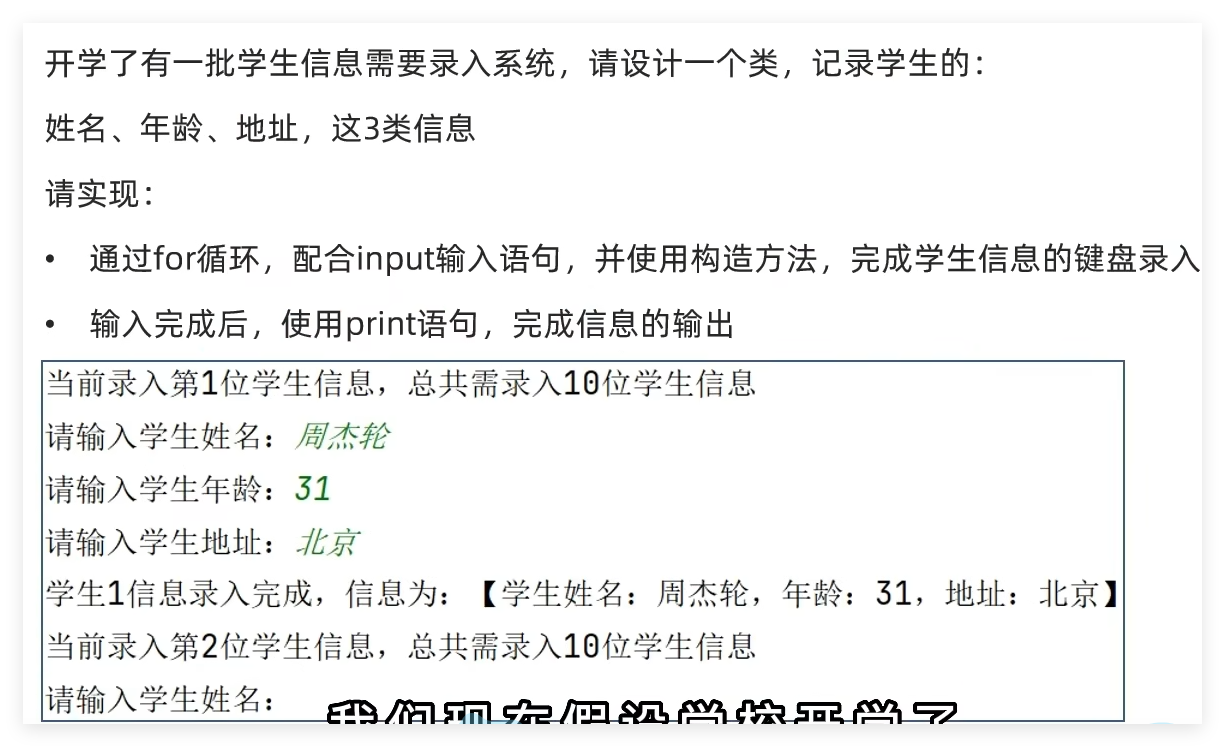
例题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 """ @Project :pythonProject @File :创建类对象.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/25 20:30 """ class Student :def __init__ (self, name, age, address ):self .name = nameself .age = ageself .address = addressfor i in range (3 ):print (f"当前录入第{i + 1 } 位学生,总共需要录入3位" )input ("请输入学生姓名:" )input ("请输入学生年龄:" )input ("请输入学生地址:" )print (f"学生{i + 1 } 信息的信息录入完成,学生的信息为:【姓名:{student.name} ,年龄:{student.age} ,地址:{student.address} 】" })
5.1.3 内置方法 魔术方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 """ @Project :pythonProject @File :02_内置方法.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/25 21:21 """ from traceback import print_tbclass Student :def __init__ (self, name, age ):self .name = nameself .age = agedef __str__ (self ):return f"Student类对象,name:{self.name} ,age:{self.age} " def __lt__ (self, other ):return self .age < other.agedef __le__ (self, other ):return self .age <= other.agedef __eq__ (self, other ):return self .age == other.age"周杰伦" , 30 )"邓紫棋" , 20 )print (student1)print (student1 < student2)"周杰伦" , 30 )"邓紫棋" , 33 )print (student3 <= student4)"周杰伦" , 30 )"邓紫棋" , 30 )print (student5 == student6)
5.2 封装 私有成员
类中提供了私有成员的形式来支持:私有成员变量;私有成员方法
定义私有成员的方式非常简单,只需要:
私有成员变量:变量名以__开头(2个下划线)
私有成员方法:方法名以__开头(2个下划线)
即可完成私有成员的设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 """ @Project :pythonProject @File :03_封装课后练习题.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/28 09:32 """ class Phone :True def __check_5g (self ):if self .__is_5g_enable:print ("5g is enable" )else :print ("5g is disable" )def check_5g (self ):self .__check_5g()
5.3 继承 5.3.1 单继承和多继承
单继承:一个类继承另一个类
多继承:一个类继承多个类,按照顺序从左向右依次继承
多继承中,如果父类有同名方法或属性,先继承的优先级高于后继承
pass关键字的作用是什么:
pass是占位语句,用来保证函数(方法)或类定义的完整性,表示无内容,空的意思
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 """ @Project :pythonProject @File :04_继承.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/28 10:01 """ from symtable import Classclass Phone :None "IT_CAST" def call_by_5g (self ):print ("5g通话已开启" )class NFCReader :"第五代" "HM" def read_card (self ):print ("NFC读卡器已开启" )def wrire_card (self ):print ("NFC写卡器已开启" )class RedRemoteControl :"红外遥控" def control (self ):print ("红外遥控器已开启" )class MyPhone (Phone, NFCReader, RedRemoteControl):pass print (phone.producer)
5.3.2 复写和父类成员 **复写:**子类继承父类的成员属性和成员方法后,如果对其“不满意”,那么可以进行复写。即:在子类中重新定义同名的属性或方法即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 """ @Project :pythonProject @File :04_继承_复写.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 18:40 """ class Phone :None "IT_CAST" def call_by_5g (self ):print ("5g通话已开启" )class MyPhone (Phone ):"123456789012345" "Made in China" def call_by_5g (self ):print ("5g通话已开启,请拨打110" )print (myPhone.IMEI)print (myPhone.producer)
调用父类成员:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 """ @Project :pythonProject @File :04_继承_复写.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 18:40 """ class Phone :None "IT_CAST" def call_by_5g (self ):print ("5g通话已开启" )class MyPhone (Phone ):"123456789012345" "Made in China" def call_by_5g (self ):print ("开启单核模式,确保通话的时候省电" )print (f"父类的厂商是:{Phone.producer} " )self )print ("----------------------" )print (f"父类的厂商是:{super ().producer} " )super ().call_by_5g()print ("关闭单核模式,确保通话的时候省电" )print (myPhone.IMEI)print (myPhone.producer)
5.4 注解 5.4.1 类型注解 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 """ @Project :pythonProject @File :05_类型注解.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 19:37 """ import jsonimport randomint = 10 str = "hello" float = 10.0 bool = True class Student :pass list = [1 , 2 , 3 ]tuple = (1 , 2 , 3 )dict = {"name" : "alaskaboo" }set = {1 , 2 , 3 }list [int ] = [1 , 2 , 3 ]tuple [int , str , bool ] = (1 , "heima" , True )dict [str , int ] = {"name" : 10 }1 , 10 ) '{"name": "alaskaboo"}' ) def func ():return 10
类型注解主要功能在于:
帮助第三方IDE工具(如PyCharm)对代码导入类型推送,协助做代码提示
帮助开发者自身对变量进行类型注释(备注 )
5.4.2 形参注解 1 2 def 函数方法名 (形参名:类型, 形参名:类型 ):pass
1 2 3 4 5 def add (x:int , y:int ):return x + ydef func (data: list ):pass
5.4.3 Union类型 Union联合类型注解,在变量注解、函数(方法)形参和返回值注解中,均可使用。
1 2 3 4 5 6 7 8 9 from typing import Union list [Union [str , int ]] = [1 , 2 , "heima" , "python" ]dict [str , Union [str , int ]] = {"name" : "alaska" , "age" : 10 }def func (data: Union [str , int ] ) -> Union [int , str ]:pass
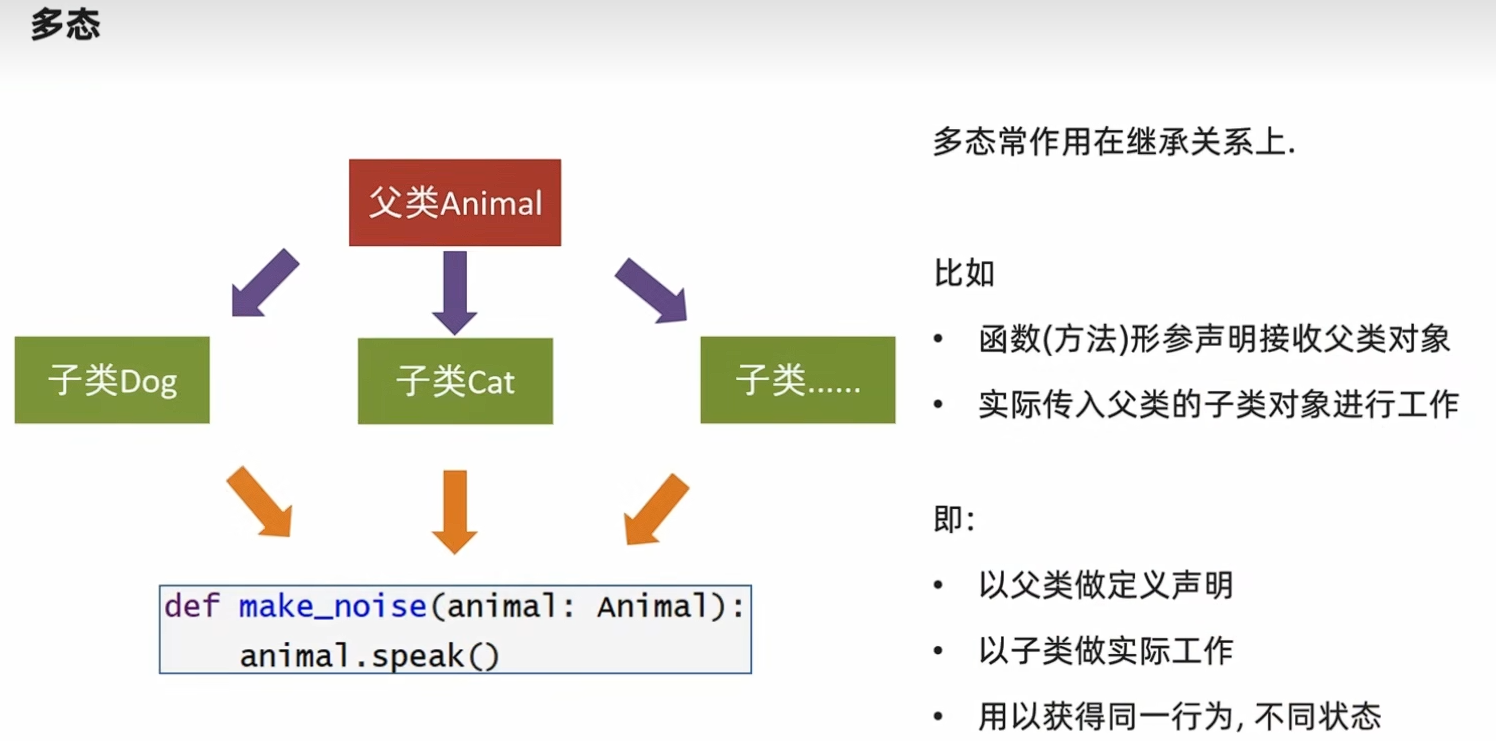
5.5 多态 概念:多种状态,即完成某个行为时,使用不同的对象会得到不同的状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 """ @Project :pythonProject @File :06_多态.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 20:16 """ class Animal :def speak (self ):pass class Dog (Animal ):def speak (self ):print ("wang wang" )class Cat (Animal ):def speak (self ):print ("miao miao" )def make_noise (animal: Animal ):
空调例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class AC :def cool_wind (self ):"""制冷""" pass def hot_wind (self ):"""制热""" pass def swing_l_r (self ):"""左右摆风""" pass class Midea_AC (AC ):def cool_wind (self ):"""制冷""" print ("midea cool" )def hot_wind (self ):"""制热""" print ("midea hot" )def swing_l_r (self ):"""左右摆风""" print ("midea swing" )class GREE_AC (AC ):def cool_wind (self ):"""制冷""" print ("gree cool" )def hot_wind (self ):"""制热""" print ("gree hot" )def swing_l_r (self ):"""左右摆风""" print ("gree swing" )def make_coll (ac: AC ):
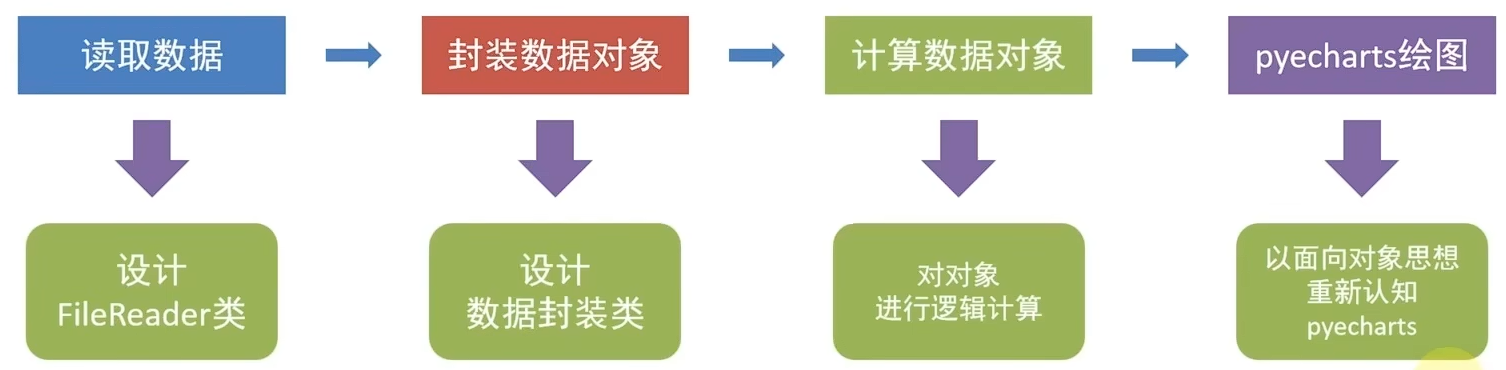
综合案例 data_define.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 """ @Project :定义数据类型 @File :data_define.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 20:36 """ class Record :def __init__ (self, date, order_id, money, province ):self .date = dateself .order_id = order_idself .money = moneyself .province = provincedef __str__ (self ):return f"{self.date} , {self.order_id} , {self.money} , {self.province} "
file_define.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 """ @Project :和文件相关的类定义 @File :file_define.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 20:42 """ import jsonfrom data_define import Recordclass FileReader :def read_data (self ) -> list [Record]:""" 读取文件数据,将数据转换为Record对象,并将其list封装返回 :return: """ pass class TextFileReader (FileReader ):def __init__ (self, file_path ):self .file_path = file_pathdef read_data (self ) -> list [Record]:open (self .file_path, 'r' , encoding='utf-8' )list [Record] = []for line in f.readlines():"," )0 ], data_list[1 ], int (data_list[2 ]), data_list[3 ])return record_listclass JsonTextFileReader (FileReader ):def __init__ (self, file_path ):self .file_path = file_pathdef read_data (self ) -> list [Record]:open (self .file_path, 'r' , encoding='utf-8' )list [Record] = []for line in f.readlines():'date' ], data_dict['order_id' ], int (data_dict['money' ]), data_dict['province' ])return record_listif __name__ == '__main__' :"utils/2011年1月销售数据.txt" )"utils/2011年2月销售数据JSON.txt" )for l in list1:print (l)for l in list2:print (l)
main.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 """ @Project :面向对象,数据分析案例 @File :main.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 20:35 """ from pyecharts.options import TitleOpts, LabelOptsfrom file_define import *from data_define import *from pyecharts.charts import Barfrom pyecharts import *from pyecharts.globals import ChartType"utils/2011年1月销售数据.txt" )"utils/2011年2月销售数据JSON.txt" )list [Record] = text_file_reader.read_data()list [Record] = json_file_reader.read_data()list [Record] = jan_data + feb_datafor record in all_data:if record.date in data_dict.keys():else :list (data_dict.keys()))"销售额" , list (data_dict.values()), label_opts=LabelOpts(is_show=False ))"2011年1月-2月每日销售额" ),"2011年1月-2月每日销售额.html" )
六 SQL 分组聚合
6.1 数据库连接 1.Python中使用什么第三方库来操作MySQL?如何安装?
使用第三方库为:pymysql
安装:pip install pymysql
2.如何获取链接对象?
from pymysqlimport Connection 导包
Connection(主机,端口,账户,密码)即可得到链接对象
链接对象.close()关闭和MySQL数据库的连接
3.如何执行SQL查询
通过连接对象调用cursor()方法,得到游标对象
游标对象.execute()执行SQL语句
游标对象.fetchall()得到全部的查询结果封装入元组内
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 """ @Project :pythonProject @File :01_pymysql入门.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/04 18:50 """ from pymysql import Connect'localhost' ,3306 ,'root' ,'root' ,'utf8' "test" )'SeLeCt * from student' )for row in result:print (row)
6.2 数据插入 数据插入有两种方法:
方法一——使用conn.commit()方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 """ @Project :pythonProject @File :02_数据插入.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/04 19:22 """ from pymysql import Connect'localhost' ,3306 ,'root' ,'root' ,'utf8' "test" )'insert into student(name,addr,age,gender) values("Alaska","上海",24,"男")' )
方法二——直接设置autocommit=True
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 """ @Project :pythonProject @File :02_数据插入.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/04 19:22 """ from pymysql import Connect'localhost' ,3306 ,'root' ,'root' ,'utf8' True "test" )'insert into student(name,addr,age,gender) values("Alaska","上海",24,"男")' )
6.3 综合案例 03_综合案例.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 """ @Project :pythonProject @File :03_综合案例.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/04 19:29 """ from file_define import *from data_define import *from pymysql import Connection"utils/2011年1月销售数据.txt" )"utils/2011年2月销售数据JSON.txt" )list [Record] = text_file_reader.read_data()list [Record] = json_file_reader.read_data()list [Record] = jan_data + feb_data"localhost" ,3306 ,"root" ,"root" ,True "py_sql" )for record in all_data:f"insert into orders(order_id, order_date, order_price, order_province)" f" values('{record.order_id} ','{record.date} ', {record.money} , '{record.province} ')" )print (sql)
data_define.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 """ @Project :定义数据类型 @File :data_define.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 20:36 """ class Record :def __init__ (self, date, order_id, money, province ):self .date = dateself .order_id = order_idself .money = moneyself .province = provincedef __str__ (self ):return f"{self.date} , {self.order_id} , {self.money} , {self.province} "
file_define.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 """ @Project :和文件相关的类定义 @File :file_define.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/10/29 20:42 """ import jsonfrom data_define import Recordclass FileReader :def read_data (self ) -> list [Record]:""" 读取文件数据,将数据转换为Record对象,并将其list封装返回 :return: """ pass class TextFileReader (FileReader ):def __init__ (self, file_path ):self .file_path = file_pathdef read_data (self ) -> list [Record]:open (self .file_path, 'r' , encoding='utf-8' )list [Record] = []for line in f.readlines():"," )0 ], data_list[1 ], int (data_list[2 ]), data_list[3 ])return record_listclass JsonTextFileReader (FileReader ):def __init__ (self, file_path ):self .file_path = file_pathdef read_data (self ) -> list [Record]:open (self .file_path, 'r' , encoding='utf-8' )list [Record] = []for line in f.readlines():'date' ], data_dict['order_id' ], int (data_dict['money' ]), data_dict['province' ])return record_listif __name__ == '__main__' :"utils/2011年1月销售数据.txt" )"utils/2011年2月销售数据JSON.txt" )for l in list1:print (l)for l in list2:print (l)
七 PySpark实战 7.1 基本概念 定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 """ @Project :pythonProject @File :01_基础准备.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/04 21:18 """ from pyspark import SparkConf, SparkContext"local[*]" ).setAppName("test_spark_app" )print (sc.version)
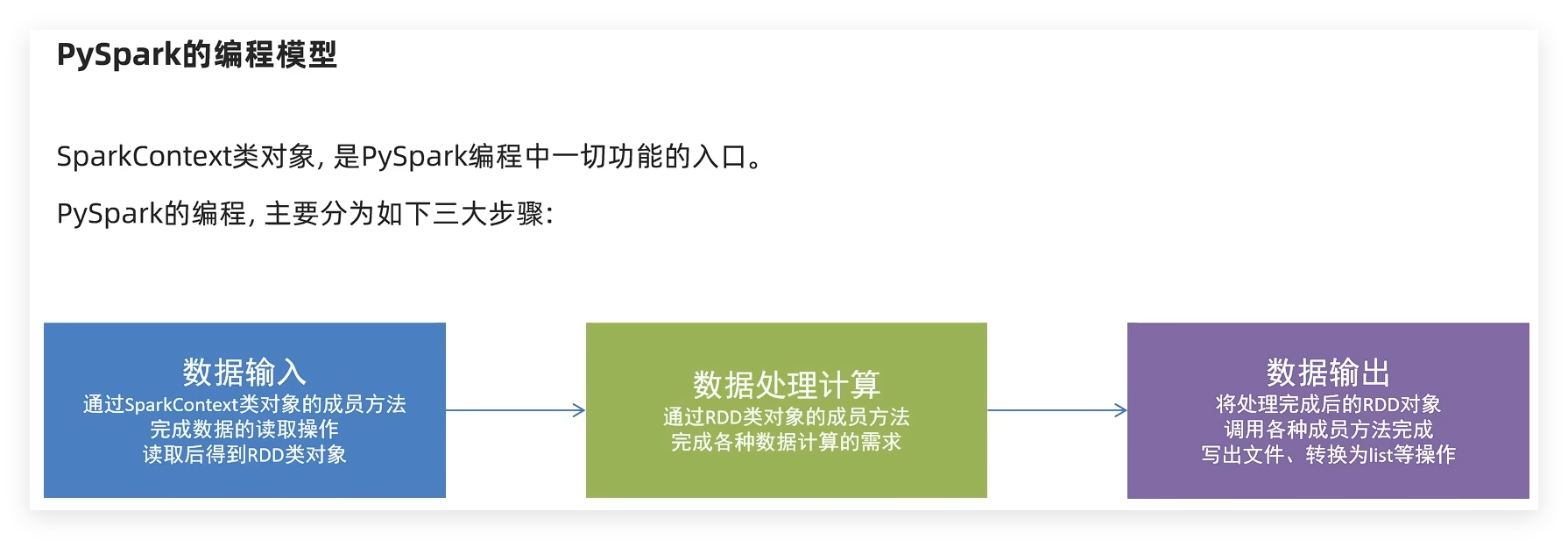
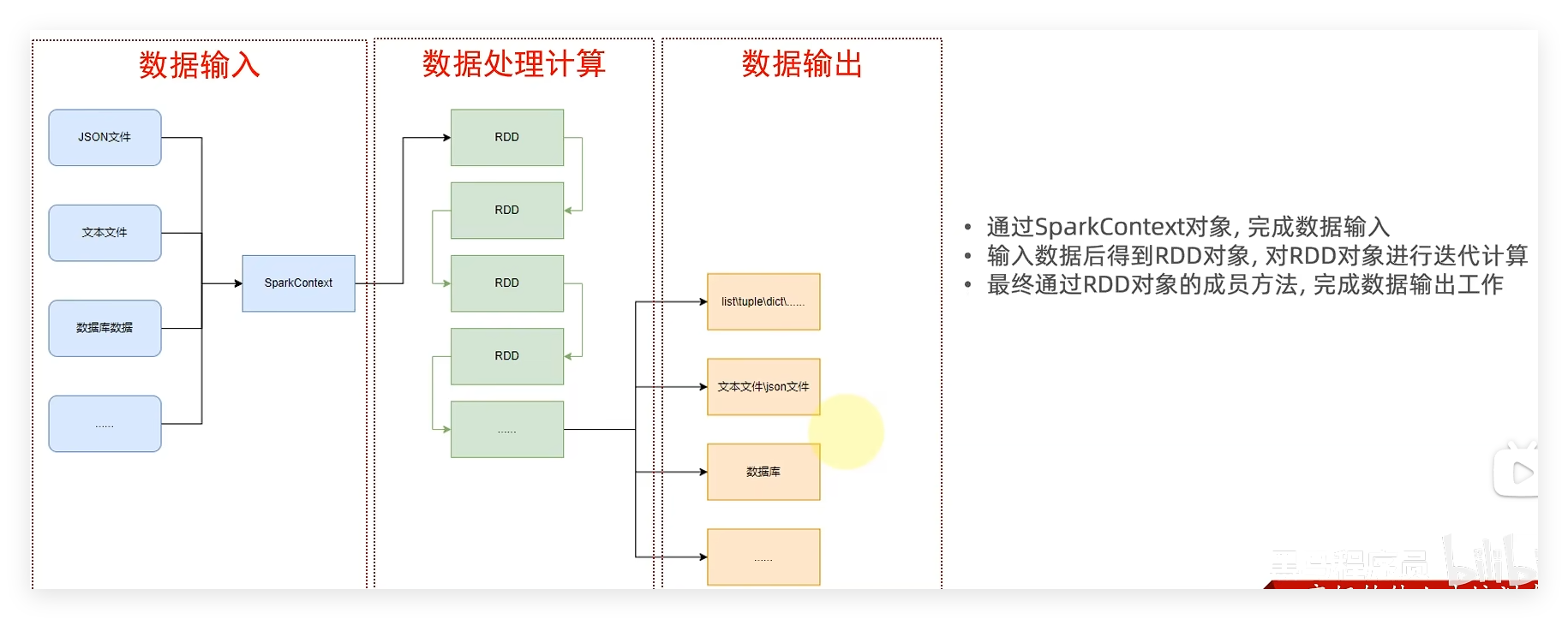
7.2 RDD对象 如图可见,PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(ResilientDistributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
数据存储在RDD内
各类数据的计算方法,也都是RDD的成员方法
RDD的数据计算方法,返回值依旧是RDD对象
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 """ @Project :pythonProject @File :02_spark文件读取.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 15:02 """ from pyspark import *"local[*]" ).setAppName("test_park" )print (sc.textFile("utils/hello.txt" ).collect())
7.3 RDD算子 7.3.1map和flatMap算子 功能:map算子,一条条处理(是将RDD的数据处理的逻辑 基于map算子中接收的处理函数),返回新的RDD
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 """ @Project :pythonProject @File :02_spark文件读取.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 15:02 """ from pyspark import SparkConf, SparkContextimport os"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' "local[*]" ).setAppName("test_park" )1 , 2 , 3 , 4 , 5 ])def func (element ):return element * 10 print (rdd.map (func).collect())
改进lambda
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 """ @Project :pythonProject @File :02_spark文件读取.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 15:02 """ from pyspark import SparkConf, SparkContextimport os"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' "local[*]" ).setAppName("test_park" )1 , 2 , 3 , 4 , 5 ])print (rdd.map (lambda x: x * 10 ).map (lambda x: x + 5 ).collect())
flatMap:唯一不同就是对结果接触嵌套
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 """ @Project :pythonProject @File :03_flatMap.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 16:09 """ from pyspark import SparkConf, SparkContextimport os"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' "local[*]" ).setAppName("test_park" )"itheima itcast hello" , "hello world" , "hello itheima" ])print (rdd.map (lambda x: x.split(" " )).collect())print (rdd.flatMap(lambda x: x.split(" " )).collect())
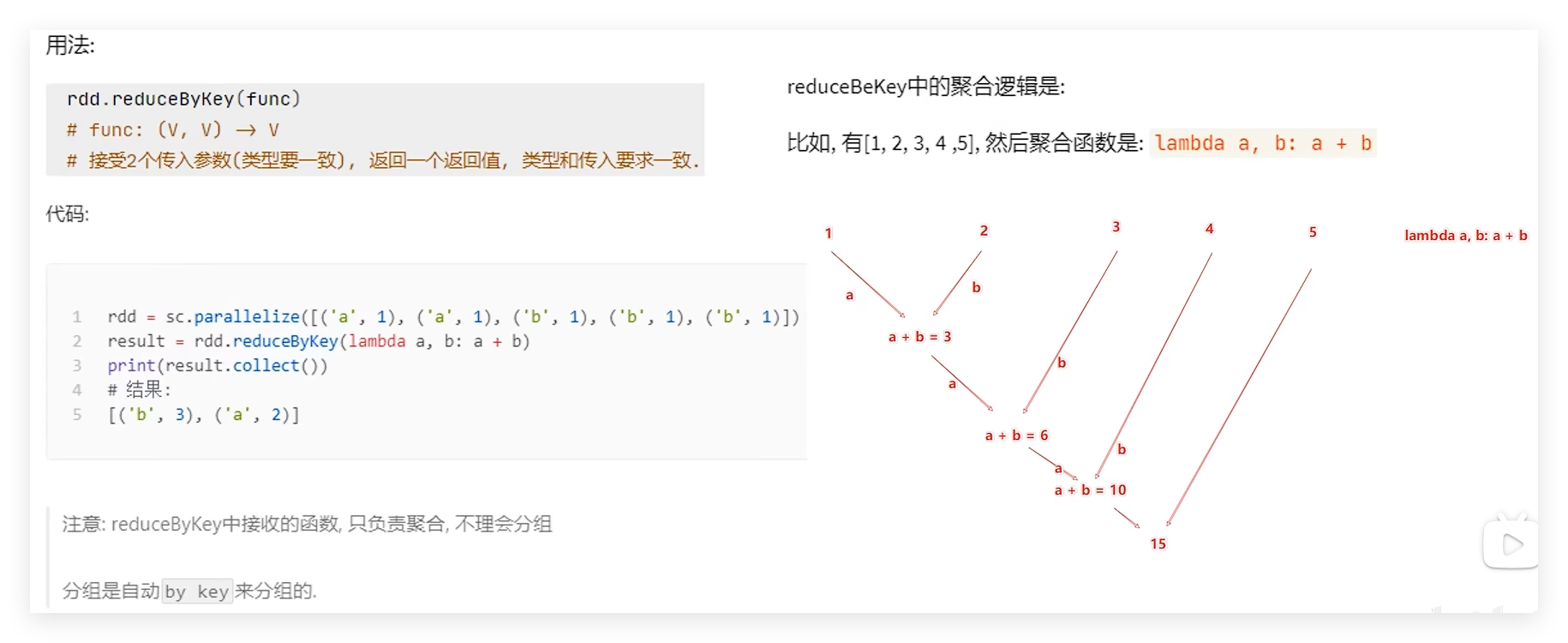
7.3.2 reduceByKey 功能:针对KV型RDD,自动按照key分组,然后根据你提供的聚合逻辑,完成组内数据(value)的聚合操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 """ @Project :pythonProject @File :04_reduceByKey.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 18:53 """ from pyspark import SparkConf, SparkContextimport os"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' "local[*]" ).setAppName("test_park" )'男' , 88 ), ('女' , 99 ), ('男' , 77 ), ('女' , 66 ), ('男' , 87 )])print (rdd.reduceByKey(lambda x, y: x + y).collect())
综合统计案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 """ @Project :pythonProject @File :05_综合案例.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 18:58 """ from pyspark import *import os"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' 'local[*]' ).setAppName('account_spark' )"utils/hello.txt" )print (rdd.flatMap(lambda x: x.split(" " )).map (lambda x: (x, 1 )).reduceByKey(lambda x, y: x + y).collect())
1 2 3 4 5 itheima itheima itcast itheima
输出结果:[(‘itcast’, 4), (‘python’, 6), (‘itheima’, 7), (‘spark’, 4), (‘pyspark’, 3)]
7.3.3 filter、distinct和sortBy
filter:过滤掉不想要的,留下来的结果是想要的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 """ @Project :pythonProject @File :06_filter.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 19:19 """ from pyspark import SparkConf, SparkContextimport os"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' "local[*]" ).setAppName("test_park" )1 , 2 , 3 , 4 , 5 ])print (rdd.filter (lambda x: x % 2 == 0 ).collect())
distinct:表示对RDD数据去重,返回新的RDD数据
1 2 3 4 1 , 2 , 2 , 3 , 3 , 4 , 6 , 9 , 8 , 1 , 7 , 5 ])print (rdd.filter (lambda x: x % 2 == 0 ).distinct().collect())
sortBy:对数据进行排序,基于拟定的排序依据
1 2 3 4 rdd.sortBy(func, ascending=False , numPartitions=1 )
综合案例2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 """ @Project :pythonProject @File :07_综合案例2.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/05 19:42 """ from pyspark import *import os, json"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' 'local[*]' ).setAppName('account_spark' )"utils/orders.txt" )lambda x: x.split('|' ))map (lambda x: json.loads(x))map (lambda x: (x['areaName' ], int (x['money' ])))print ("全国售卖商品销售额排序" , city_with_money_rdd.reduceByKey(lambda x, y: x + y).sortBy(lambda x: x[1 ], ascending=False ).collect())print ("全部售卖商品类别" , dict_rdd.map (lambda x: x['category' ]).distinct().collect())print ("北京市售卖商品类别" , dict_rdd.filter (lambda x: x['areaName' ] == '北京' ).map (lambda x: x['category' ]).distinct().collect())
7.3.4 take、reduce和count、
reduce:按照传入的逻辑进行聚合
take:取出RDD的前N个元素,组成list返回
count:统计数据个数
7.4 算子写入文件 hadoop设置分区为1的两种方式:
方式1,SparkConf对象设置属性全局并行度为1
1 2 3 conf = SparkConf().setMaster('local[*]' ).setAppName('account_spark' )set ("spark.default.parallelism" , "1" )
方式2,创建RDD的时候设置(parallelize方法传入numSlices参数为1)
1 2 3 4 5 6 1 , 2 , 3 , 4 , 5 , 6 , 7 , 8 , 9 , 10 ], numSlices=1 )"hello" , 3 ), ("Spark" , 5 ), ("Hi" , 7 )], 1 )1 , 3 , 5 ], [6 , 7 , 9 ], [11 , 13 , 11 ]], 1 )
综合案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 """ @Project :pythonProject @File :09_综合案例3.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/06 08:39 """ from pyspark import SparkContext, SparkConfimport os, json"PYSPARK_PYTHON" ] = 'E:/Environment/python/python3.10.11/python.exe' 'HADOOP_HOME' ] = 'E:\Environment\hadoop-3.4.0' "hotSearch" ). \"local[*]" ). \set ("spark.default.parallelism" , "1" )"utils/search_log.txt" )map (lambda x: (x.split("\t" )[0 ][:2 ], 1 )). \lambda x, y: x + y). \lambda x: x[1 ], ascending=False , numPartitions=1 ). \3 )print ("需求1的结果是:" , result_rdd)map (lambda x: (x.split("\t" )[2 ], 1 )). \lambda x, y: x + y). \lambda x: x[1 ], ascending=False , numPartitions=1 ). \3 )print ("需求2的结果是:" , search_rdd)filter (lambda x: "黑马程序员" in x). \map (lambda x: (x.split("\t" )[0 ][:2 ], 1 )). \lambda x, y: x + y). \lambda x: x[1 ], ascending=False , numPartitions=1 ). \1 )print ("需求3的结果是:" , key_max_in_time_rdd)map (lambda x: x.split("\t" )). \map (lambda x: {"Time" : x[0 ], "User_id" : x[1 ], "Search_word" : x[2 ],"Search_count" : x[3 ], "Clicks_count" : x[4 ], "Search_URL" : x[5 ]}). \"search_log_json" )
八 高阶学习 8.1 闭包 概念:为了改变全局变量有被修改的风险,在函数嵌套的前提下,内部函数使用了外部函数的变量,并且外部函数返回了内部函数,我们把这个使用外部函数变量的内部函数称为闭包。
优点,使用闭包可以让我们得到:
无需定义全局变量即可实现通过函数,持续的访问、修改某个值
闭包使用的变量的所用于在函数内,难以被错误的调用修改
缺点:
由于内部函数持续引用外部函数的值,所以会导致这一部分内存空间不被释放一直占用内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 def create_logo_printer (logo: str ) -> callable :""" 创建一个打印带有logo的消息的函数 :param logo: logo文本 :return: 一个打印带有logo的消息的函数logo_printer """ def logo_printer (msg: str ) -> None :""" 打印带有logo的消息 :param msg: 消息文本 :return: None """ return print (f"<{logo} >{msg} <{logo} >" )return logo_printer"中国" )"重庆" )
使用nonlocal关键字修改外部函数的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 def create_accumulator (initial_value: int ) -> callable :""" Creates an accumulator function that adds a given increment to the initial value. Args: initial_value: The initial value of the accumulator. Returns: A function that takes an increment and returns the updated accumulator value. """ def accumulator (increment: int ) -> int :nonlocal initial_valueprint (initial_value)return accumulator10 )23 )
ATM小案例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def create_account (initial_amount=0 ):def transaction (amount, deposit=True ):nonlocal balanceif deposit:print (f"存款:+{amount} , 余额:{balance} " )else :if balance >= amount:print (f"取款:-{amount} , 余额:{balance} " )else :print ("余额不足" )def get_balance ():return balancereturn transaction, get_balance1000 )500 , deposit=True ) 200 , deposit=False ) print (get_balance())
8.2 装饰器
普通写法
1 2 3 4 5 6 7 8 9 def sleep ():import randomimport timeprint ("sleeping..." )1 , 5 ))print ("I want to sleep" )print ("I have slept" )
装饰器一般写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def decorator (func ):def wrapper ():print ("I want to sleep" )print ("I have slept" )return wrapperdef sleep ():import randomimport timeprint ("sleeping..." )1 , 5 ))
语法糖写法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def decorator (func ):def wrapper ():print ("I want to sleep" )print ("I have slept" )return wrapper@decorator def sleep ():import randomimport timeprint ("sleeping..." )1 , 5 ))
8.3 设计模式 8.3.1 单例模式 概念:单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
定义:保证一个类只有一个实例,并提供一个访问它的全局访问点
适用场景:当一个类只能有一个实例,而客户可以从一个众所周知的访问点访问它时。
单例模式_strTools.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 """ @Project :pythonProject @File :单例模式_strTools.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/07 20:17 """ from 单例模式_strTools import str_toolsprint (id (t1))print (id (t2))
单例模式_strTools.py
1 2 3 4 5 6 7 8 9 10 11 12 """ @Project :pythonProject @File :单例模式_strTools.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/07 20:17 """ class StrTools :pass
输出结果:相当于使用的一个实例化对象~
1 2 3 4 2199380285360 2199380285360 0
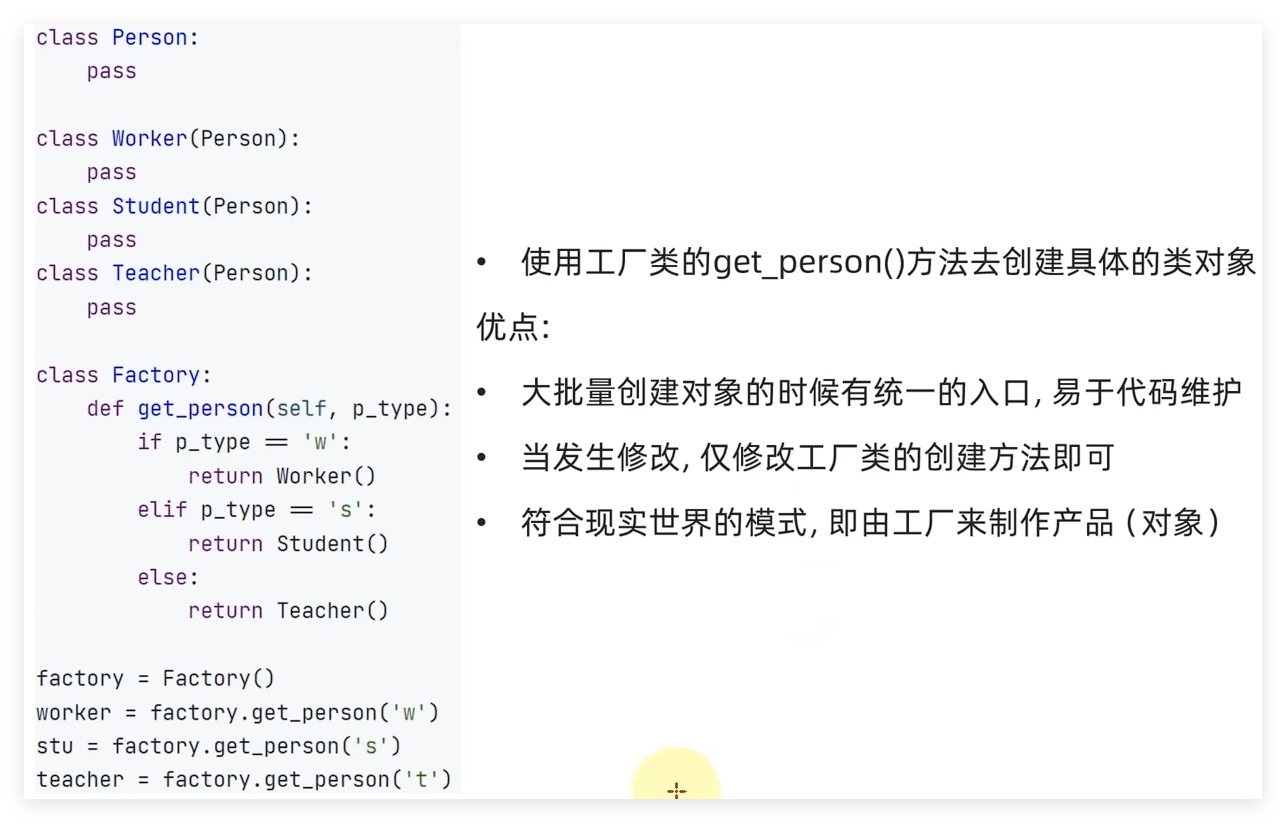
8.3.2 工厂模式 概念:当需要大量创建一个类的实例的时候,可以使用工厂模式。即,从原生的使用类的构造去创建对象的形式迁移到,基于工厂提供的方法去创建对象的形式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 """ @Project :pythonProject @File :05_工厂模式.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/07 20:28 """ class Person :pass class Worker (Person ):print ("I am a worker" )class Student (Person ):print ("I am a student" )class Teacher (Person ):print ("I am a teacher" )class Factory :def get_person (self, person_type ):if person_type == 'worker' :return Worker()elif person_type == 'student' :return Student()else :return Teacher()print (factory.get_person('worker' ))print (factory.get_person('student' ))print (factory.get_person('teacher' ))
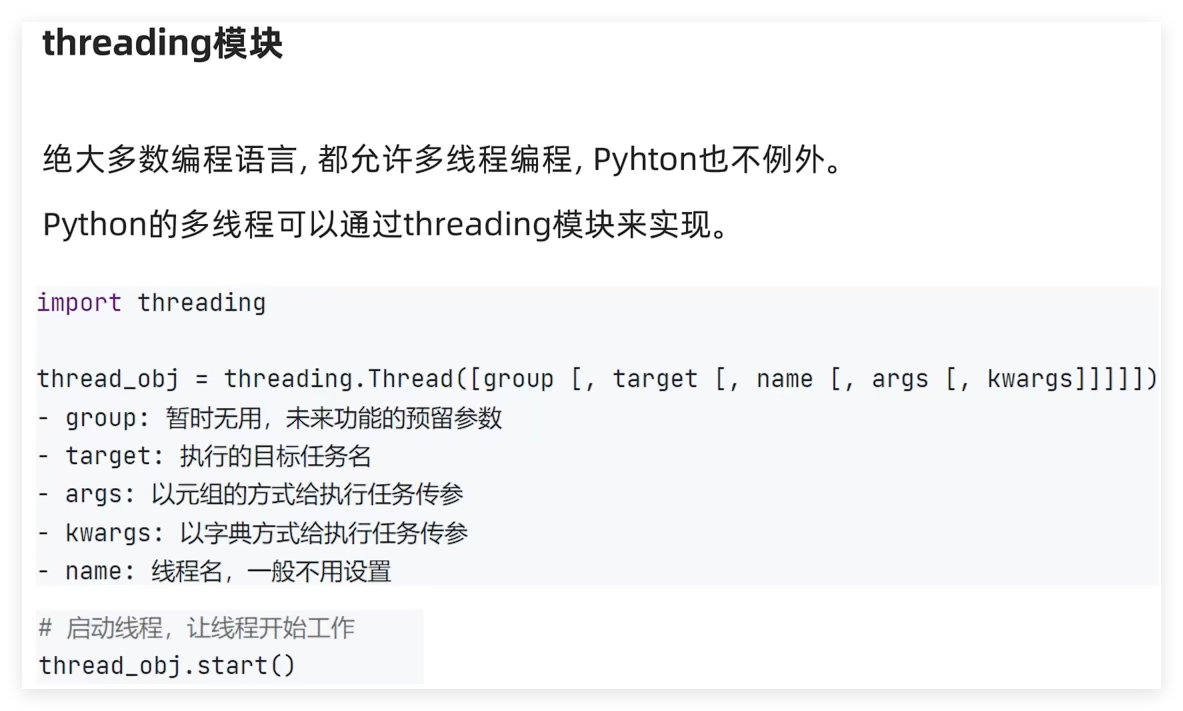
8.4 多线程 8.4.1 进程、线程和并行执行 进程:就是一个程序,运行在系统之上,那么便称之这个程序为一个运行进程,并分配进程ID方便系统管理。
并行执行:同一时间做不同的工作。
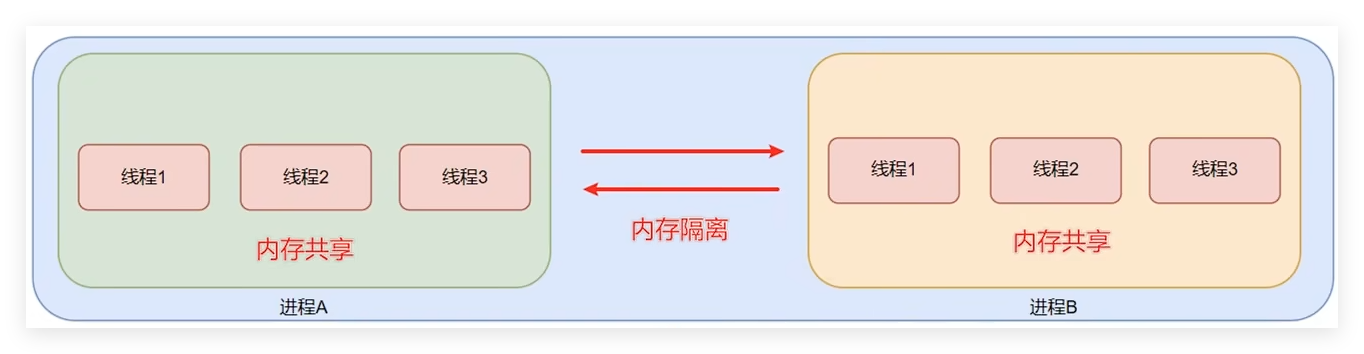
进程之间就是并行执行的,操作系统可以同时运行好多程序,这些程序都是在并行执行。
进程之间是内存隔离的,即不同的进程拥有各自的内存空间。这就类似于不同的公司拥有不同的办公场所。
线程之间是内存共享的,线程是属于进程的,一个进程内的多个线程之间是共享这个进程所拥有的内存空间的,
这就好比,公司员工之间是共享公司的办公场所。
8.4.2 多线程编程 单线程示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import timedef sing ():while True :print ("I am singing...." )1 )def dance ():while True :print ("I am dancing...." )1 )if __name__ == '__main__' :
多线程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 """ @Project :pythonProject @File :06_多线程.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/07 21:33 """ import time, threadingdef sing (msg ):while True :print (msg)1 )def dance (msg ):while True :print (msg)1 )if __name__ == '__main__' :'我在唱歌' ,))'msg' :'我在跳舞' })
8.5 网络编程 socket(简称 套接字)是进程之间通信一个工具,好比现实生活中的插座,所有的家用电器要想工作都是基于插座进行,进程之间想要进行网络通信需要socket 。
8.5.1 服务端编程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 """ @Project :pythonProject @File :07_socket_服务端开发.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/08 18:33 """ import socket'127.0.0.1' , 8888 ))5 )print (f"接收到了客户端的连接,客户端的信息是:{address} " )while True :str = conn.recv(1024 ).decode("utf-8" )print (f"客户端发来的消息是:{data} " )input ("请输入你要和客户端回复的消息:" )if msg == "exit" :break "utf-8" ))
8.5.2 客户端编程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 """ @Project :pythonProject @File :08_socket_客户端开发.py.py @IDE :PyCharm @Author :AlaskaBoo @Date :2024/11/08 19:08 """ import socket'127.0.0.1' , 8888 ))while True :input ("请输入要给服务器发送的消息:" )if msg == 'exit' :break 'utf-8' ))1024 )print (f"服务端回复的消息是:{receive_data.decode('utf-8' )} " )
8.6 正则表达式 8.6.1 基本概念 正则表达式,又称规则表达式(Regular Expression),是使用单个字符串来描述、匹配某个句法规则的字符串,常被用来检索、替换那些符合某个模式(规则)的文本。即字符串定义规则,并通过规则去验证字符串是否匹配。
比如,验证一个字符串是否是符合条件的电子邮箱地址,只需要配置好正则规则,即可匹配任意邮箱。
比如通过正则规则:(^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$)即可匹配一个字符串是否是标准邮箱格式
但如果不使用正则,使用ifelse来对字符串做判断就非常困难了
Python正则表达式,使用re模块,并基于re模块中三个基础方法来做正则匹配。
分别是:match、search、findall 三个基础方法
re.match(匹配规则,被匹配字符串)
从被匹配字符串开头进行匹配,匹配成功返回匹配对象(包含匹配的信息),匹配不成功返回空
低阶使用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 """ @Project :pythonProject @File :09_正则表达式.py @IDE :PyCharm @Author :AlaskaBoo @Date :2024/11/08 19:53 """ import re'python itheima itcast python python itheima' match ("python" , s)print (result)"itcast" , s)print (result)"python" , s)print (result)
8.6.2 元字符匹配
字符
功能
.
匹配任意一个字符(除了\n),\.匹配点本身
[]
匹配[]中列举的字符
\d
匹配数字,即0-9
\D
匹配非数字
\s
匹配空白,即空格、tab键
\S
匹配非空白
\w
匹配单词字符,即a-z、A-Z、0-9、_
\W
匹配非单词字符
数量匹配:
字符
功能
*
匹配前一个规则的字符出现0至无数次
+
匹配前一个规则的字符出现1至无数次
?
匹配前一个规则的字符出现出现0次或1次
{m}
匹配前一个规则的字符出现出现m次
{m,}
匹配前一个规则的字符出现至少出现m次
{m,n}
匹配前一个规则的字符出现m到n次
边界匹配:
字符
功能
^
匹配字符串开头
$
匹配字符串结尾
\b
匹配一个单词的边界
\B
匹配非单词边界
分组匹配:
字符
功能
|
匹配左右任意一个表达式
()
将括号中字符作为一个分组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 """ @Project :pythonProject @File :09_正则表达式_元字符匹配.py @IDE :PyCharm @Author :AlaskaBoo @Date :2024/11/08 20:21 """ import re"itcast1 @@python131¥%R#$%^&*() !! 666 ##itheima3" r"[a-zA-Z0-9]" , s)print (result)"^[a-zA-Z0-9]{6,10}$" "itcast1" '123456789990' print (re.findall(r, s))print (re.findall(r, s1))print ("-----------------------" )"^[1-9][0-9]{4,10}$" "123456789" '123456789990' print (re.findall(r, s))print (re.findall(r, s1))r"(^[\w-]+(\.[\w-]+)*@(163|qq|gmail)(\.[\w-]+)+$)" "upchh@example.com" 'anpch@126.com' 'envkt@163.com' 'envkt@qq.com' 'envkt@gmail.com' print (re.match (r, s))print (re.match (r, s1))print (re.match (r, s2))print (re.match (r, s3))print (re.match (r, s4))
8.7 递归
概念:在满足条件的情况下,函数自己调用自己的一种特殊编程
技巧递归需要注意什么?
注意退出的条件,否则容易变成无限递归
注意返回值的传递,确保从最内层,层层传递到最外层
os模块的3个方法
os.listdir,列出指定目录下的内容
os.path.isdir,判断给定路径是否是文件夹,是返回True,否返回False
os.path.exists,判断给定路径是否存在,存在返回True,否则返回False
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 """ @Project :pythonProject @File :10_递归.py @IDE :PyCharm @Author :Alaskaboo @Date :2024/11/08 21:05 """ import osdef test_os ():print (os.path.exists("E:\Markdown" ))def get_files_recursion_from_dir (path ):""" 从指定的文件夹中使用递归的方式,获取全部的文件列表 :param path: 被判断的文件夹 :return: list,包含全部的文件,如果目录不存在或者无文件就返回一个空list """ print (f"当前调用的路径是:{path} " )if os.path.exists(path):for f in os.listdir(path):'/' + fif os.path.isdir(new_path):else :else :print (f"指定文件目录{path} ,不存在" )return []return file_listif __name__ == '__main__' :print (get_files_recursion_from_dir(r"D:\上工程文件" ))