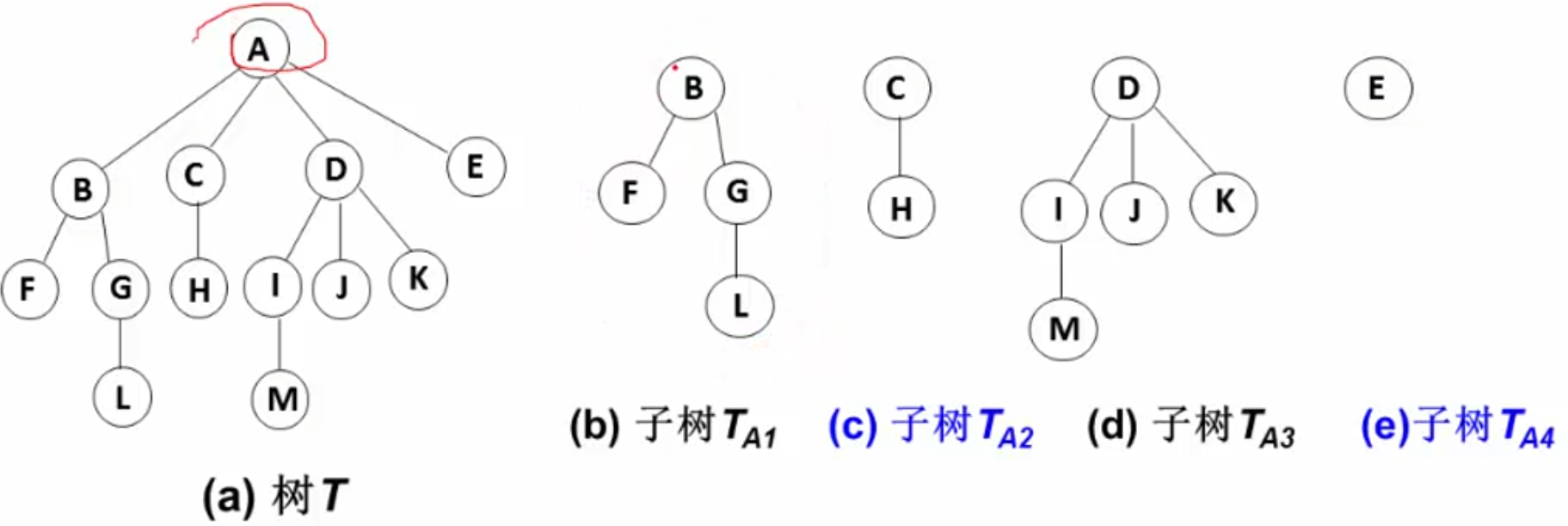
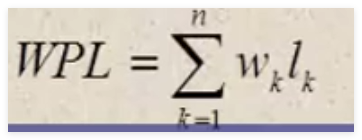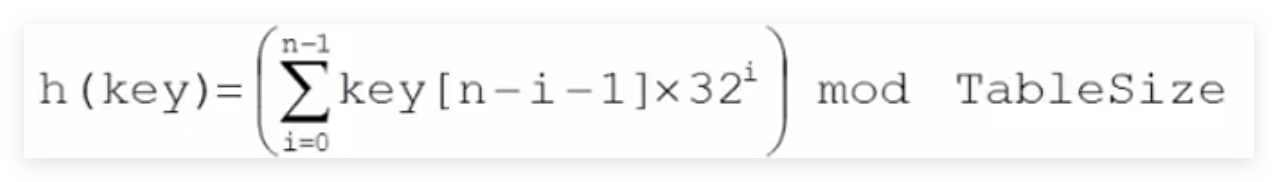一、队列 1.多项式相关 加法运算实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 Polynomial PolyAdd (Polynomial P1, Polynomial P2) {int sum;malloc (sizeof (struct PolyNode));while (P1 && P2)switch (Compare(P1->expon, P2->expon)){case 1 :break ;case -1 :break ;case 0 :if ( sum )Attach(sum, P1->expon, &rear);break ;for ( ; P1; P1=P1->link)Attach(P1->coef, P1->expon, &rear);for ( ; P2; P2 = P2->link)Attach(P2->coef, P2->expon, &rear);NULL ;free (temp);return front;void Attach ( int c, int e, Polynomial *pRear ) malloc (sizeof (struct PolyNode));NULL ;
2.多项式练习题 方法一:
数组 :编程简单、调试容易;事先确定数组大小
链表 :动态性强;编程略微复杂、调试比较困难
数据结构设计
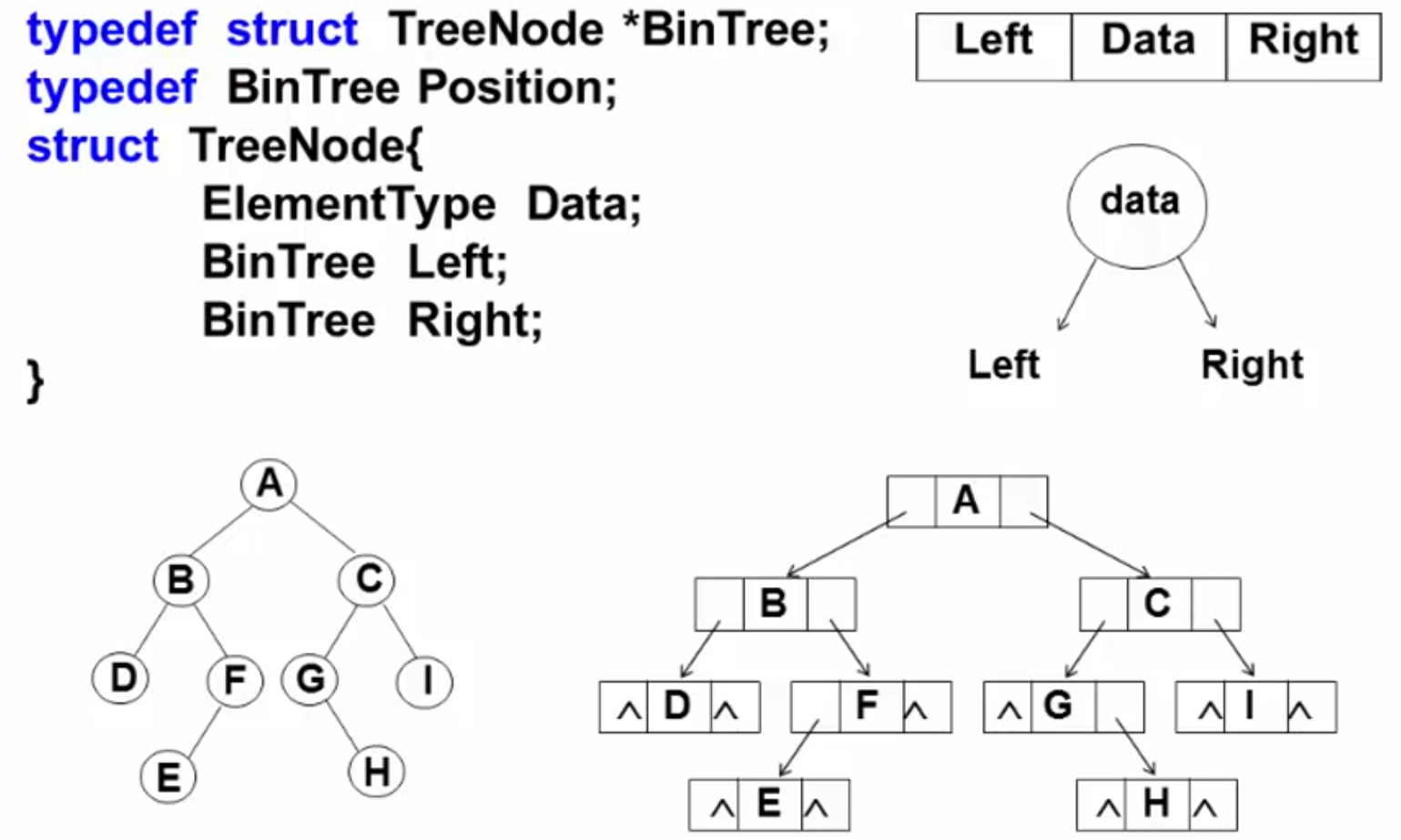
1 2 3 4 5 6 typedef struct PolyNode *Polynomial ;struct PolyNode {int coef;int expon;
程序框架 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 读入程序:ReadPoly () int c, e, N;scanf ("%d" ,&N);malloc (sizeof (struct PolyNode));NULL ;while (N--){scanf ("%d %d" , &c, &e);free (t);return P; void lynomial *pRear )malloc (sizeof (struct PolyNode));NULL ;
二、树 1 基本概念 定义:n(n≥0)个结点构成的有限集合。当n=0时,称为空树;对于任一棵非空树(n>0),它具备以下性质:
树中有一个称为 “根(Root)” 的特殊结点,用r表示;
其余结点可分为m(m>0)个互不相交的有限集T1,T2…. ,Tm,其中每个集合本身又是一棵树,称为原来树的“子树(Sub Tree )”
作用 :用于查找。查找又分为静态和动态.
特点 :
子树是不相交的;
除了根节点外,每个结点有且仅有一个父节点
一棵树N 个结点的树有N-1 条边
树的基本术语
结点的度(Degree):结点的子树个数;
树的度:树的所有结点中最大的度数树的度;
叶结点(Leaf):度为0的结点;
父结点(Parent):有子树的结点是其子树的根结点的父结点;
子结点(Child):若A结点是B结点的父结点,则称B结点是A结点的子结点;子结点也称孩子结点;
兄弟结点(Sibling):具有同一父结点的各结点彼此是兄弟结点;
路径和路径长度:从结点n1到nk的路径为一个结点序列n1,n2,…,nk,ni是 ni+1的父结点。路径所包含边的个数为路径的长度。
祖先结点(Ancestor):沿树根到某一结点路径上的所有结点都是这个结点的祖先结点。
子孙结点(Descendant)::某一结点的子树中的所有结点是这个结点的子孙。
11.结点的层次(Level):规定根结点在1层其它任一结点的层数是其父结点的层数加1.12.树的深度(Depth):树中所有结点中的最大层次是这棵树的深度。
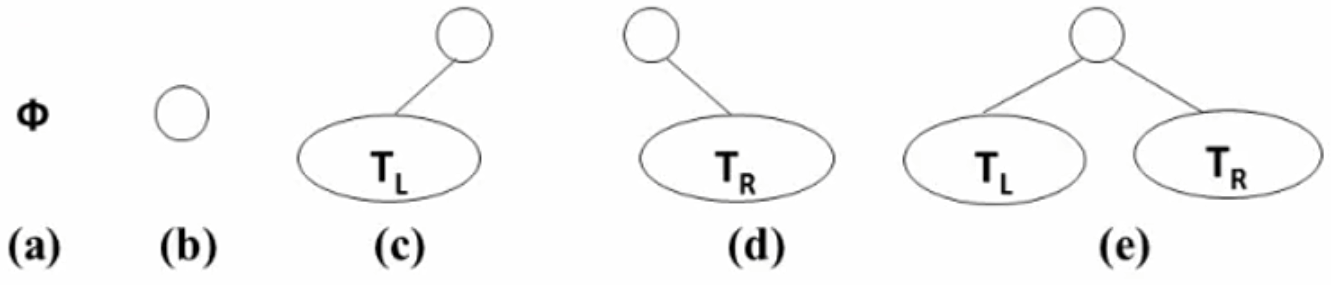
2 二叉树 2.1 基本概念 2.1.1 二叉树定义
一个又穷的结点集合。这个集合可以为空,若不为空,则它是由根节点和称为其左子树T˪和右子树Tᵣ的两个不相交的二叉树组成
几个重要性质
一个二叉树第i层的最大结点数为:2ⁱ⁻¹,i≥1。
深度为k的二叉树有最大结点总数为:2ᵏ-1,k≥1
对任何非空二叉树T,若n₀表示叶结点的个数、n₂是度为2的非叶结点个数,那么两者满足关系n₀=n₂+1
2.1.2 抽象数据定义
数据对象集:一个有穷的结点集合。若不为空,则由根结点和其左、右二叉子树组成。
Boolean lsEmpty ( BinTree BT):判别BT是否为空;
void Traversal ( BinTree BT):遍历,按某顺序访问每个结点;
BinTree CreatBinTree( ):创建一个二叉树。
2.1.3 五种基本形式 2.1.4 子树左右顺序之分 2.2 特殊二叉树 2.2.1 斜二叉树 2.2.2 完美二叉树(满二叉树)
2.2.3 完全二叉树 跟满二叉树相似,但是不同点是完全二叉树可以比满二叉树少后面连续的几个度。
2.3 存储结构 2.3.1 顺序存储
注:一般二叉树也可实现这种方法,但是必须造成空间额外的开销
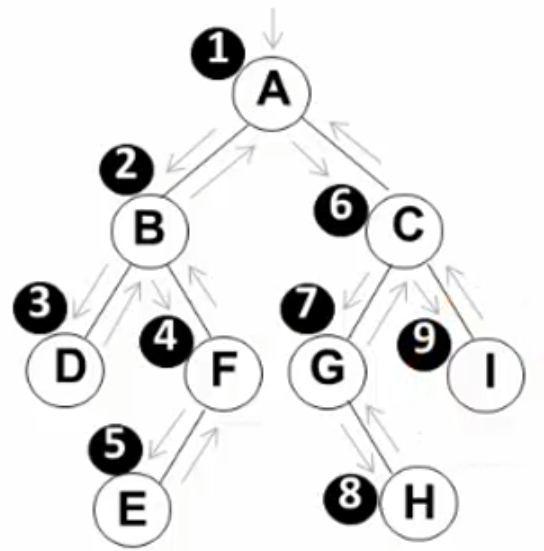
2.3.2 链表存储 2.4 常用的遍历 2.4.1 先序遍历 遍历过程(根、左子树、右子树):①访问根结点;②先序遍历其左子树;③先序遍历其右子树
1 2 3 4 5 6 7 8 void Preordertraversal (BinTree BT) if ( BT ){printf (“d", BT->Data); PreOrderTraversal( BT -> Left ); PreOrderTraversal( BT -> Right ); } }
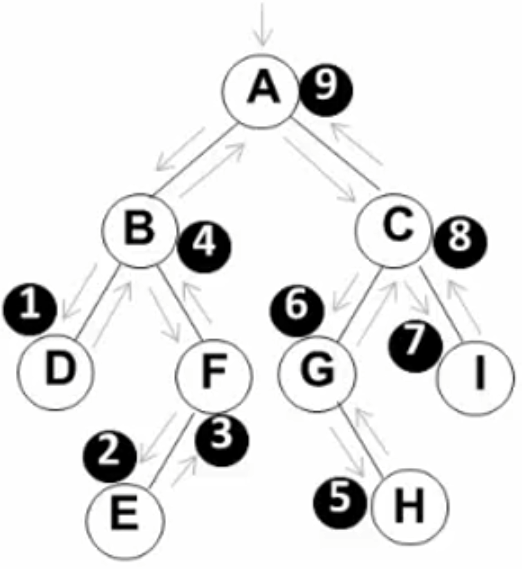
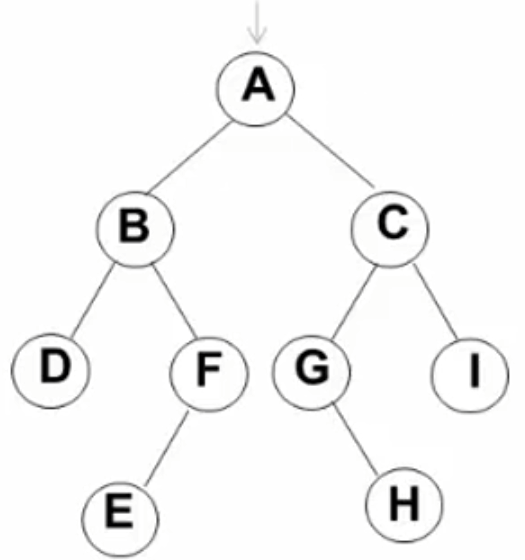
例:
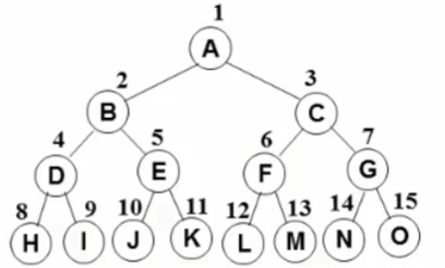
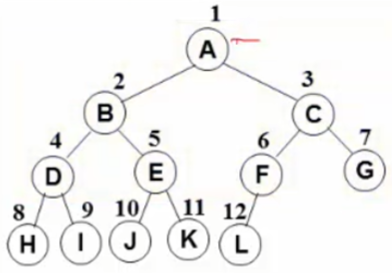
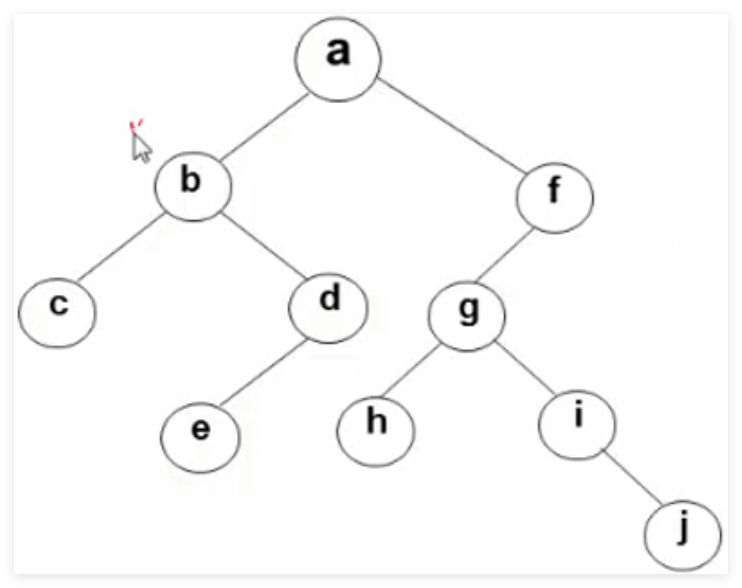
先序遍历 => A (B D F E) (C G H I)
先序非递归遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void InOrderTraversal ( BinTree BT ) while ( T || !IsEmpty(S) ){while ( T ){ printf (“%5 d”, T->Data); if ( !IsEmpty(S) ) {
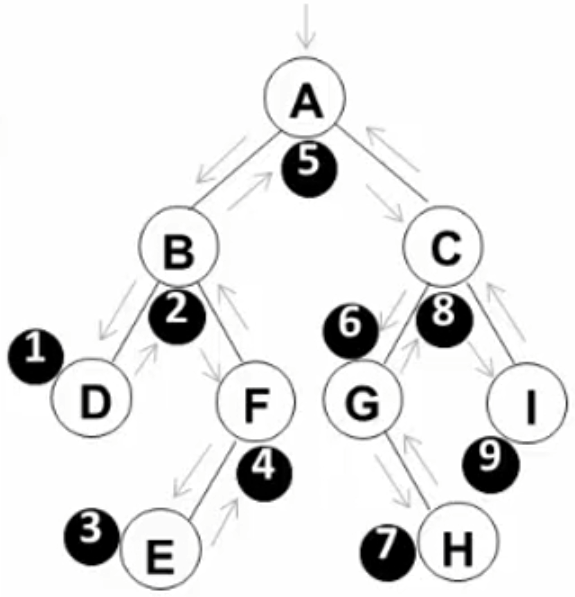
2.4.2 中序遍历 遍历过程(左子树、根、右子树):①先序遍历其左子树;②访问根结点;③先序遍历其右子树;
1 2 3 4 5 6 7 8 void Preordertraversal (BinTree BT) if ( BT ){printf (“d", BT->Data); PreOrderTraversal( BT -> Right ); } }
例:
中序遍历=> ( D B E F ) A ( G H C I)
中序也可以用递归来实现:
遇到一个结点,就把它压栈,并去遍历它的左子树;
当左子树遍历结束后,从栈顶弹出这个结点并访问它;
然后按其右指针再去中序遍历该结点的右子树。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void InOrderTraversal ( BinTree BT ) while ( T || !IsEmpty(S) ){while ( T ){ if ( !IsEmpty(S) ) {printf (“%5 d”, T->Data);
2.4.3 后序遍历 遍历过程(左子树、右子树、根):①先序遍历其左子树;②先序遍历其右子树③访问根结点;
1 2 3 4 5 6 7 8 void Preordertraversal (BinTree BT) if ( BT ){printf (“d", BT->Data); } }
例:
后序遍历=> (D E F B) (H G I C) A
后续非递归遍历:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void InOrderTraversal ( BinTree BT ) while ( T || !IsEmpty(S) ){while ( T ){ if ( !IsEmpty(S) ) {printf (“%5 d”, T->Data);
2.4.4 层次遍历 层次遍历过程:从上到下、从左到右。
**队列实现:**遍历从根结点开始,首先将根结点入队,然后开始执行循环:(结点出队、访问该结点、其左右儿子入队)
实现思路:
先放入A,抛出A。 再依次放入左右儿子B C,再抛出B。再放入B的左右儿子D F,抛出C。放入C的左右孩子G I,抛出D。由于D没有左右孩子,抛出F。放入E,抛出G。放入 H,抛出I,最后抛出E H。
A B C D F G I E H
1 2 3 4 5 6 7 8 9 10 11 12 13 14 void LevelOrderTraversal (BinTree BT) if ( !BT ) return ;while (!IsEmptyQ( Q )){printf (“%d\n”, T->Data); if ( T -> Left) AddQ( Q, T->Left);if ( T -> Right) AddQ( Q, T->Right);
2.5 二叉树的应用 2.5.1 输出二叉树中的叶子结点 再二叉树的遍历算法中增加检测结点的“左右子树是否都为空”。
1 2 3 4 5 6 7 8 void PrerderPrintLeaves (BinTree B) {if (BT ){if ( !BT -> Left && !BT -> Right ){printf (“%d", BT->Data ); PreOrderPrintLeaves(BT -> Left); PreOrderPrintLeaves(BT -> Right); } }
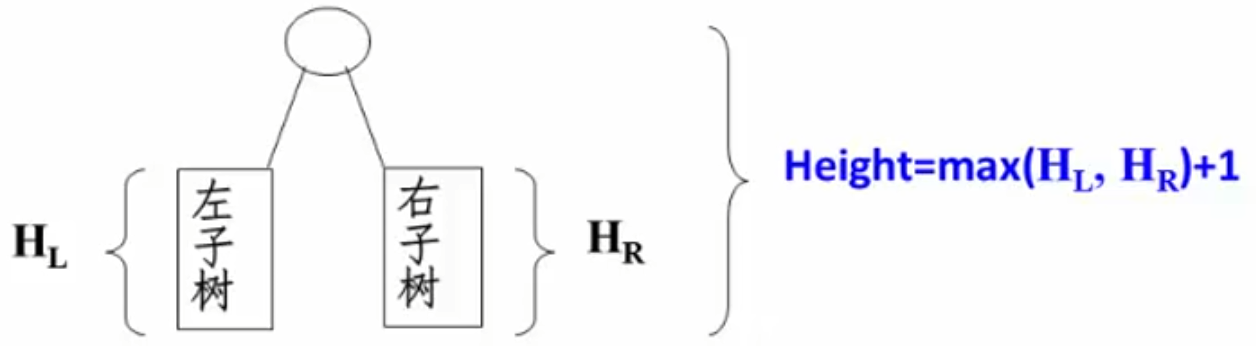
2.5.2 二叉树的高度 1 2 3 4 5 6 7 8 9 10 11 PostorderGetHeight( Bintree BT )int HL, HR, MaxH;if (BT ){return (MaxH + 1 ); else return 0 ;
注:查找的效率与树的高度有关
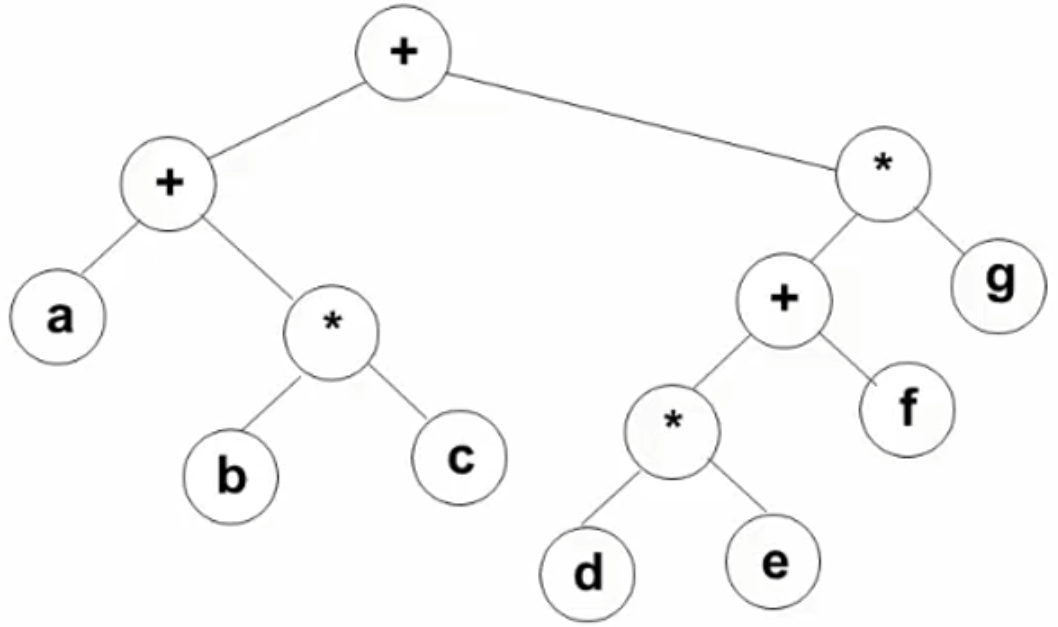
2.5.3 二元运算表达式树及其遍历 例:
三种不同的访问结果:
先序:++ a * b c * + * d e f g
中序:a + b * c + d * e + f * g (中序可能带来符号的问题,解决办法可添加符号进行运算)
后序:a b c * + d e * f + g * +
2.5.4 由两种遍历序列确定二叉树 必须要有两个中序遍历才行。因为必须确定根节点
先序序列:a b c d e f g h i j
2.5.5 同构树判断
给定两棵树T1和T2。如果T1可以通过若干次左右孩子互换就变成T2,则我们称两棵树是“同构”的。
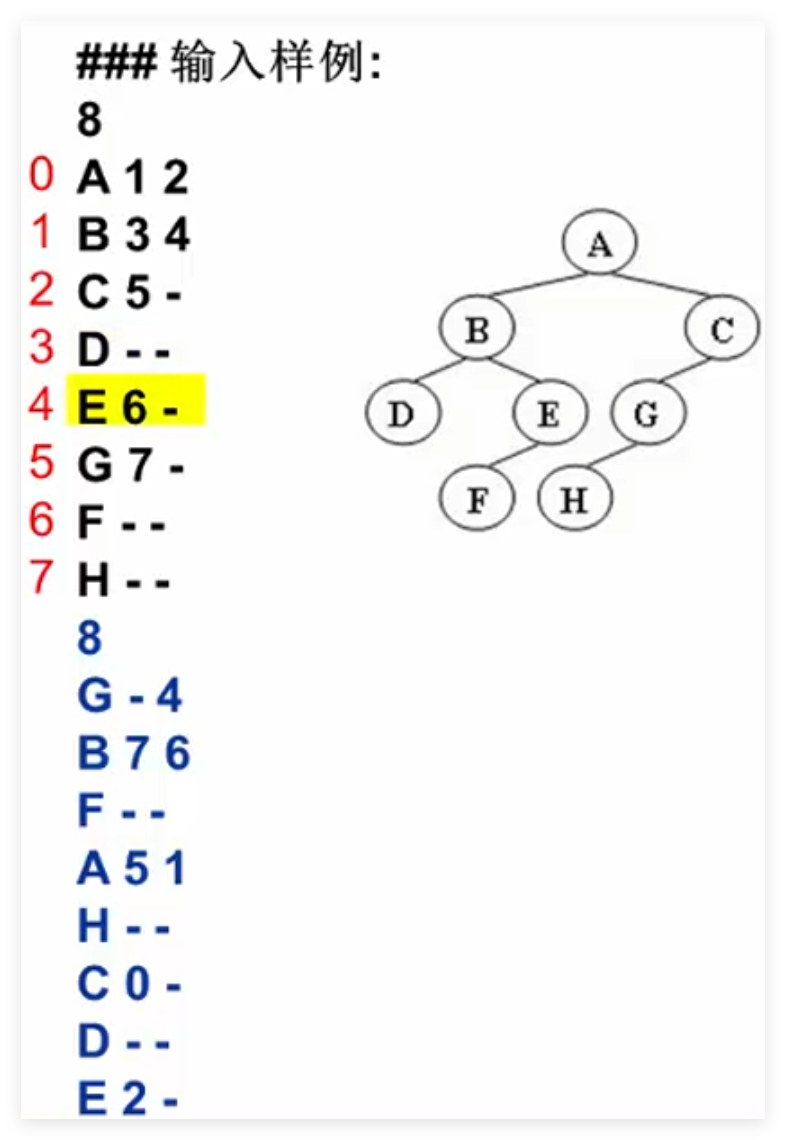
输入给出2棵二叉树的信息:
先在一行中给出该树的结点数,随后N行
第i行对应编号第i个结点,给出该结点中存储的字母、其左孩子结点的编号、右孩子结点的编号。
如果孩子结点为空,则在相应位置上给出“-”
求解思路:
二叉树表示
建二叉树
同构判别
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #define MaxTree 10 #define ElementType char #define Tree int #define Null -1 struct TreeNode { int main () {if (Isomorphic(R1, R2)) printf ("Yes\n" );else printf ("No\n" );return 0 struct TreeNode T[] ){scanf ("%d\n" , &N);if (N){for (i=0 ; i<N; i++) check[i]= 0 ;for (i=0 ; i<N; i++){scanf ("%c %c %c\n" , &T[i].Element, &cl, &cr);if (cl != '-' ){'0' ; 1 ;else T[i].Left = Null;for (i=0 ; i<N; i++)if (!check[i]) break ;return Root;int Isomorphic ( Tree R1, Tree R2 ) {if ((R1 == Null) && (R2 == Null) )return 1 ;if (( (R1==Null) && (R2 != Null) )|| ( (R1!=Null) && (R2==Null) ))return 0 ;if (T1[R1].Element != T2[R2].Element)return 0 ; if ((T1[R1].Left ==Null) && (T2[R2].Left == Null))return Isomorphic( T1[R1].Right, T2[R2].Right );if (( (T1[R1].Left!=Nul) && (T2[R2].Left!=Null)) && return (lsomorphic( T1[R1].Left, T2[R2].Left )&&else return ( lsomorphic( T1[R1].Left, T2[R2].Right) &&
3 二叉搜索树 二叉搜索树(BST,Binary Search Tree),也称二叉排序树或二叉查找树
非空左子树的所有键值小于其根结点的键值。
非空右子树的所有键值大于其根结点的键值。
左、右子树都是二叉搜索树
3.1 查找操作Find 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 Find ( ElementType X, BinTree BST) {if ( !BST ) return NULL ;if ( X > BST->Data)return Find(X, BST -> Right );if ( X < BST->Data ) return Find (X, BST -> Left) ;else return BST;FindMin ( BinTree BST) {if ( !BST ) return NULL ; else if ( !BST -> Left )return BST; else return FindMin(BST -> Left);FindMax ( BinTree BST) {if ( BST )while (BST -> Right) BST = BST -> Right;return BsT;
3.2 插入操作Insert 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 BinTree Insert ( ElementType X, BinTree BST) {if ( !BST ){malloc (sizeof (struct TreeNode));NULL ;else if (X<BST->Data )else if (X>BST->Data)return BST;
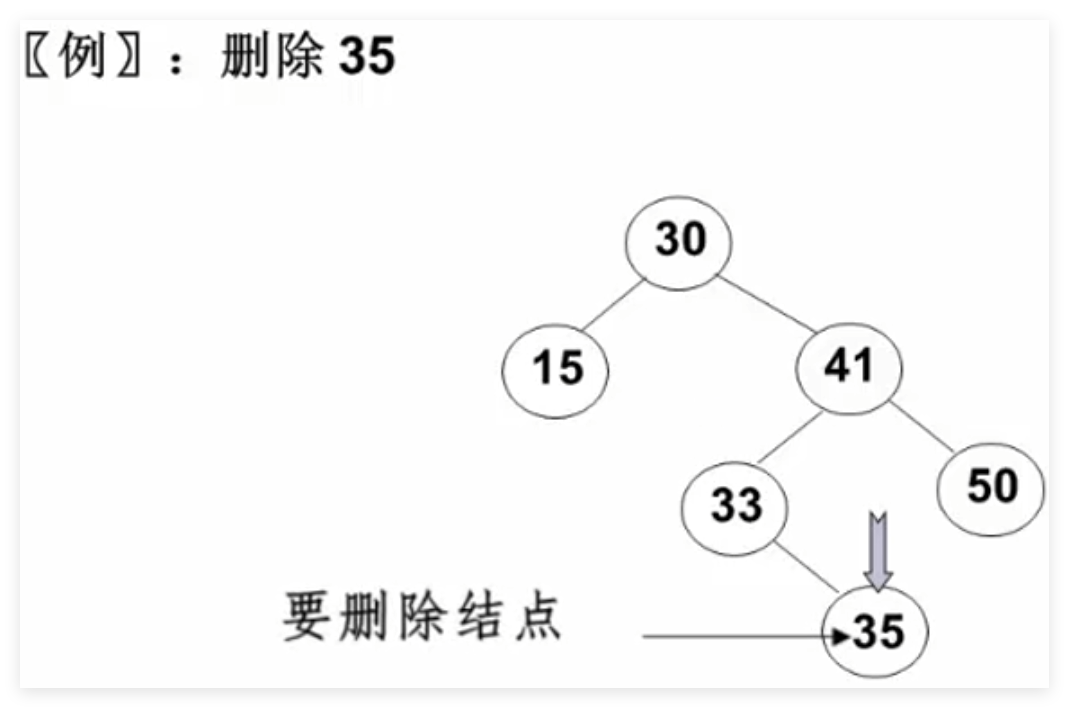
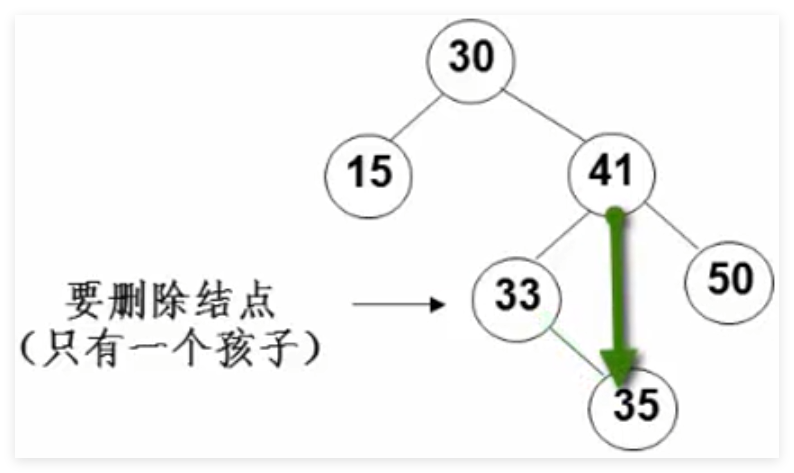
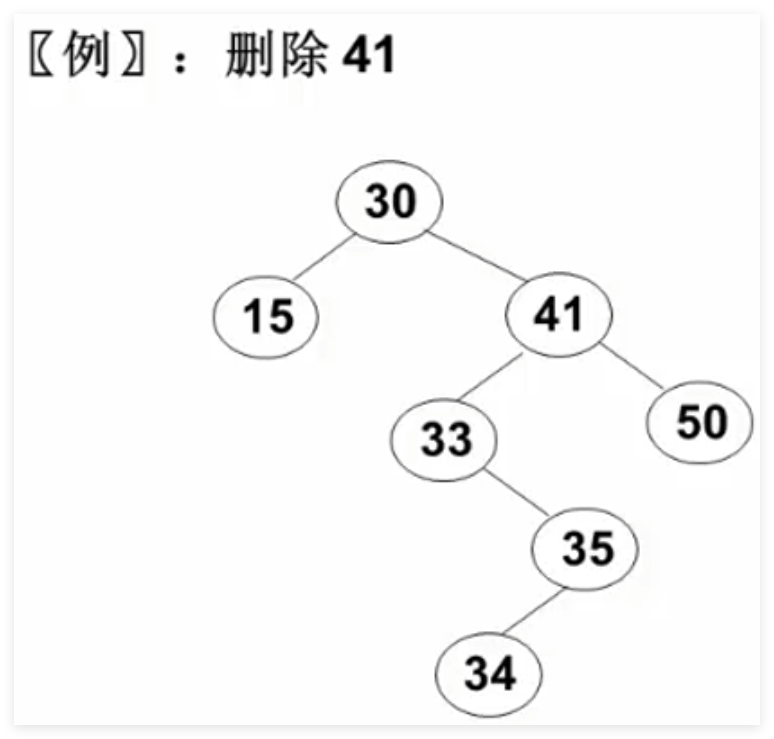
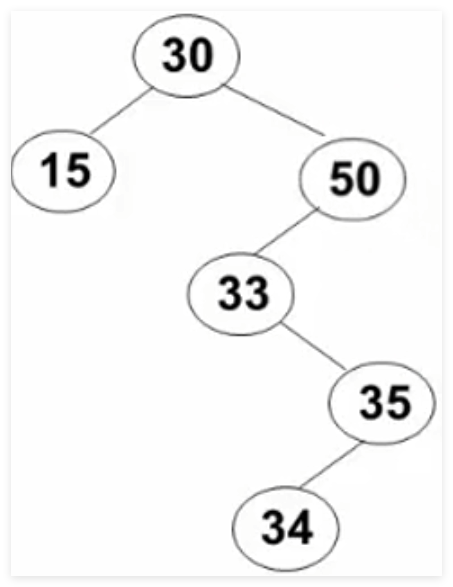
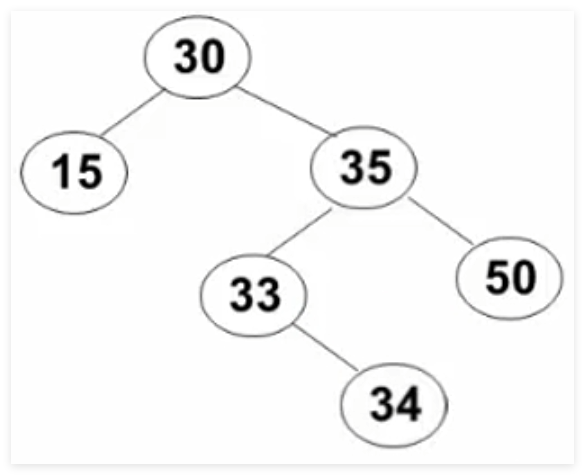
3.3 删除操作 要考虑的三种情况:
要删除的是叶结点 :直接删除,并再修改其父结点指针设置为NULL
要删除的结点只有一个孩子结点:将其父结点的指针指向要删除结点的孩子结点
要删除的结点有左、右两棵子树 :用另一结点替代被删除结点,即右子树的最小元素 或者左子树的最大元素
取右子树中的最小元素 替代:
取左子树中的最大元素 替代:
程序代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 BinTree Delete (ElementType X, BinTree BST) {if ( !BST ) printf ("要删除的元素未找到" );else if ( X < BST -> Data )else if ( X > BST -> Data )else if ( BST -> Left && BST -> Right){else {if ( !BST -> Left)else if ( !BsT -> Right)free ( Tmp );return BST;
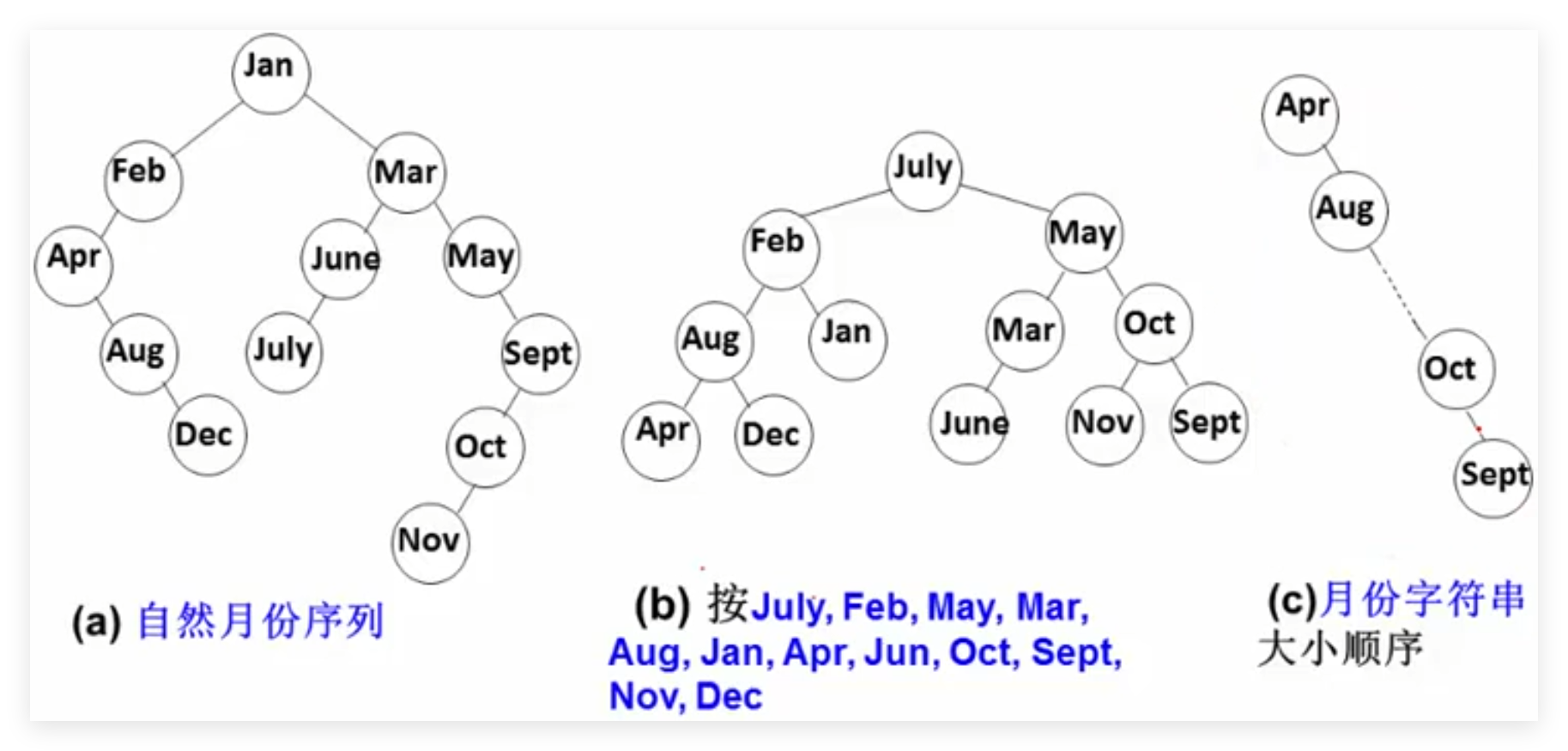
3.4 判别是否同一搜索树 求解思路
分别建两棵搜索树的判别方法
不建树的判别方法
建一棵树,再判别其他序列是否与该树一致
选择第3种进行设计
搜索树表示
建搜索树T
判别一序列是否与搜索树T一致
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 typedef struct TreeNode *Tree ;struct TreeNode {int v;int flag;int main () {int N, L, i;scanf ("%d" , &N);while (N) {scanf ("%d" , &L);for (i=0 ; i<L; i++){if (Judge(T, N)) printf ("Yes\n" );else printf ("No\n" );scanf ("%d" ,&N);return 0 ;MakeTree ( int N ) {int i, V;scanf ("%d" , &V);for (i=1 ; i<N; i++){scanf ("%d" ,&V);return T;NewNode ( int V ) {malloc (sizeof (struct TreeNode));NULL ;0 ;return T;insert ( Tree T, int V ) {if ( !T ) T = NewNode(V);else {if ( V > T -> v )else return T;int check ( Tree T, int V ) {if ( T -> flag ){if ( V < T -> v ) return check( T -> Left, V);else if ( V > T -> v ) return check( T -> Right, V);else return 0 ;else {if ( V == T -> v ){1 ;return 1 ;else return 0 ;int Judge ( Tree T, int N ) {int i, V, flag = 0 ;scanf ( "%d" , &V);if ( V != T->v ) flag = 1 ;else T -> flag = 1 ;for (i = 1 ; i < N; i++){scanf ("%d" , &V);if ( (!flag) && (!check(T, V))) flag = 1 ;if (flag) return 0 ;else return 1 ;void ResetT (TreeT) {if ( T -> Left) ResetT( T -> Left);if (T -> Right) ResetT( T -> Right);0 ;void FreeTree (TreeT) {if (T -> Left) FreeTree(T -> Left);if (T -> Right) FreeTree(T -> Right);free (T);
4 平衡二叉树 4.1 基本概念
平衡二叉树(Balanced Binary Tree) (AVL树) :空树,或者任一结点左、右子树高度差的绝对值不超过1,即**|BF(T)|≤1**
平衡因子(Balance Factor,简称BF) :BF(T)= h˪-hᵣ其中h˪和hᵣ分别为T的左、右子树的高度。
给定结点数为 n 的 AVL 树的最大高度为 O(log₂n)
搜索树节点不同的插入次序,将导致不同的深度和平均查找长度ASL
4.2 调平
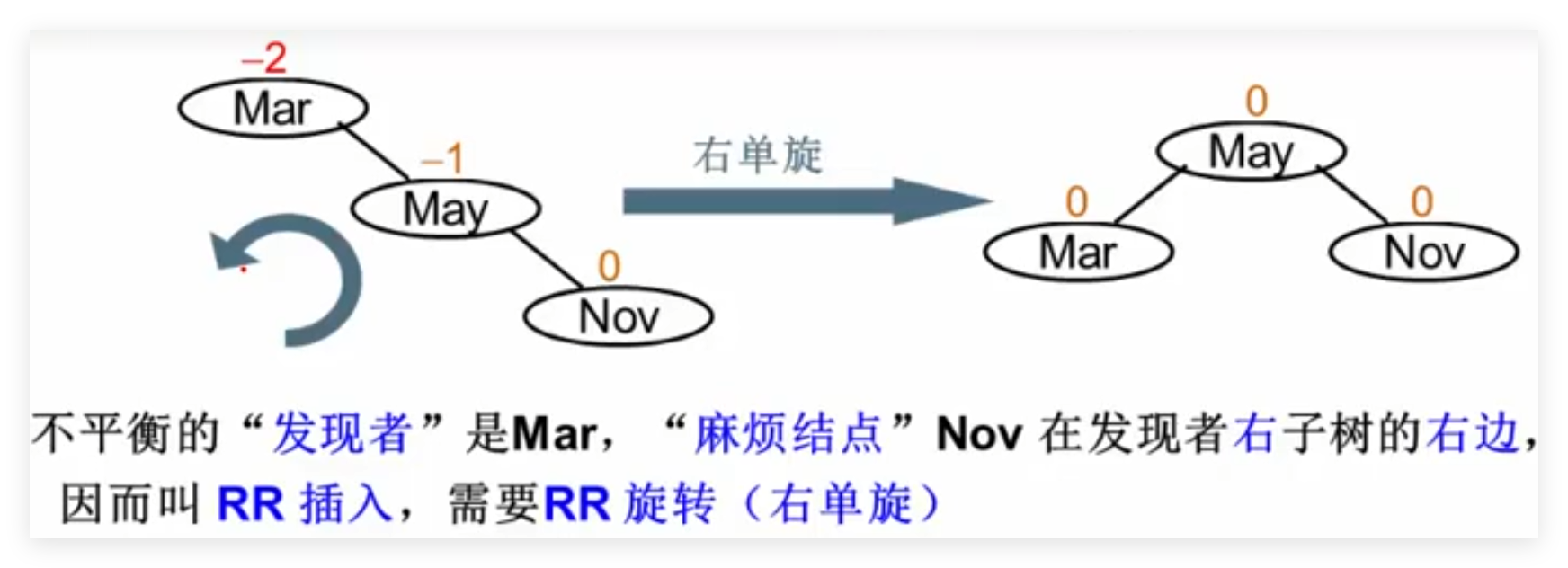
RR旋转
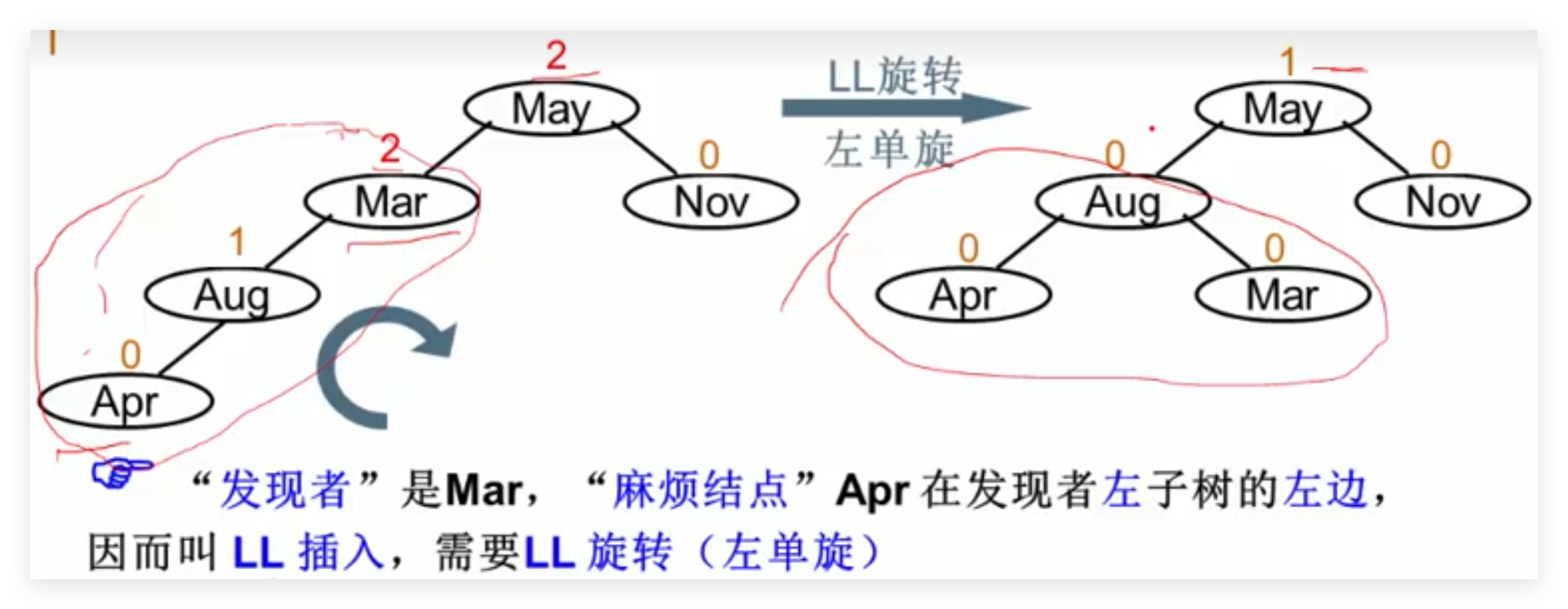
LL旋转
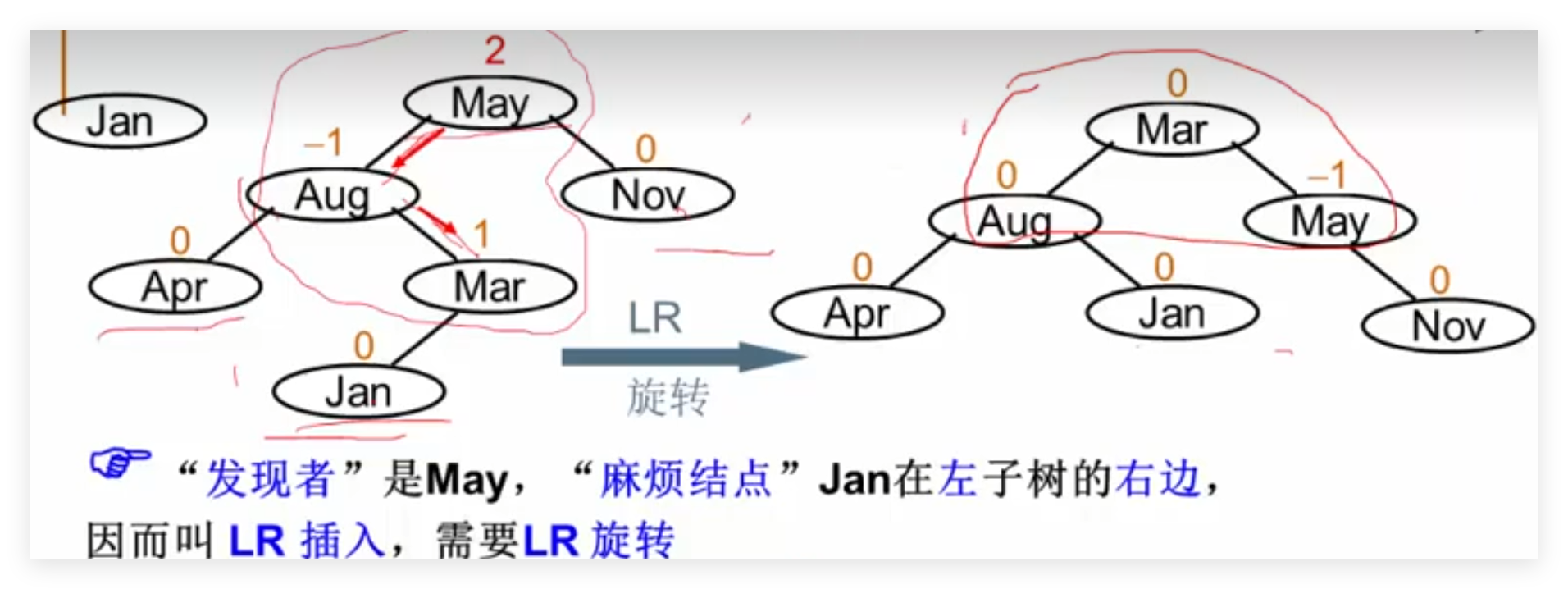
LR旋转
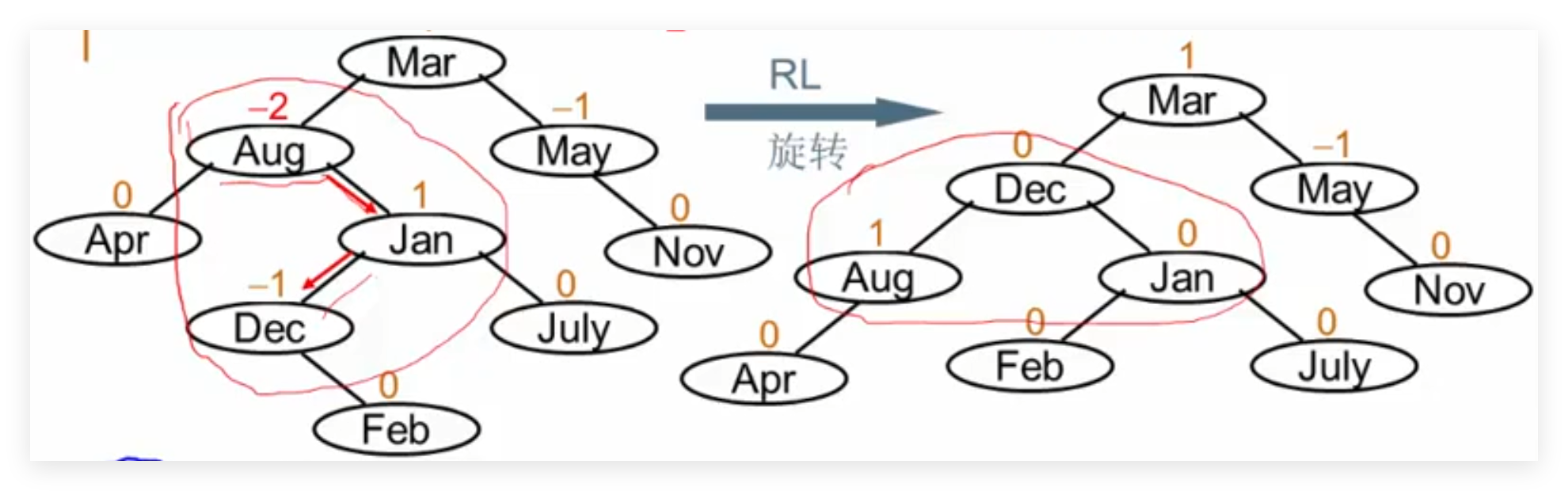
RL旋转
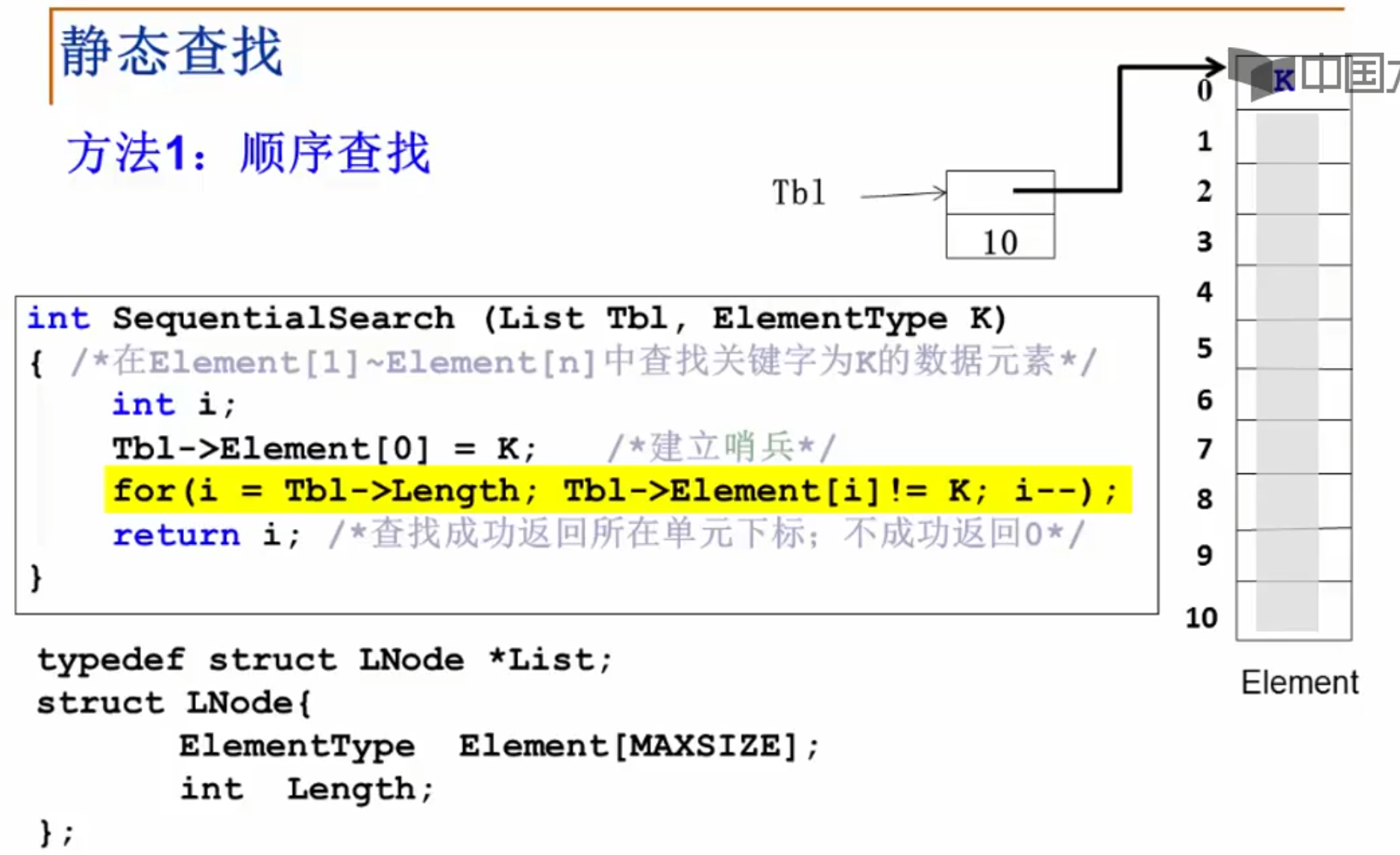
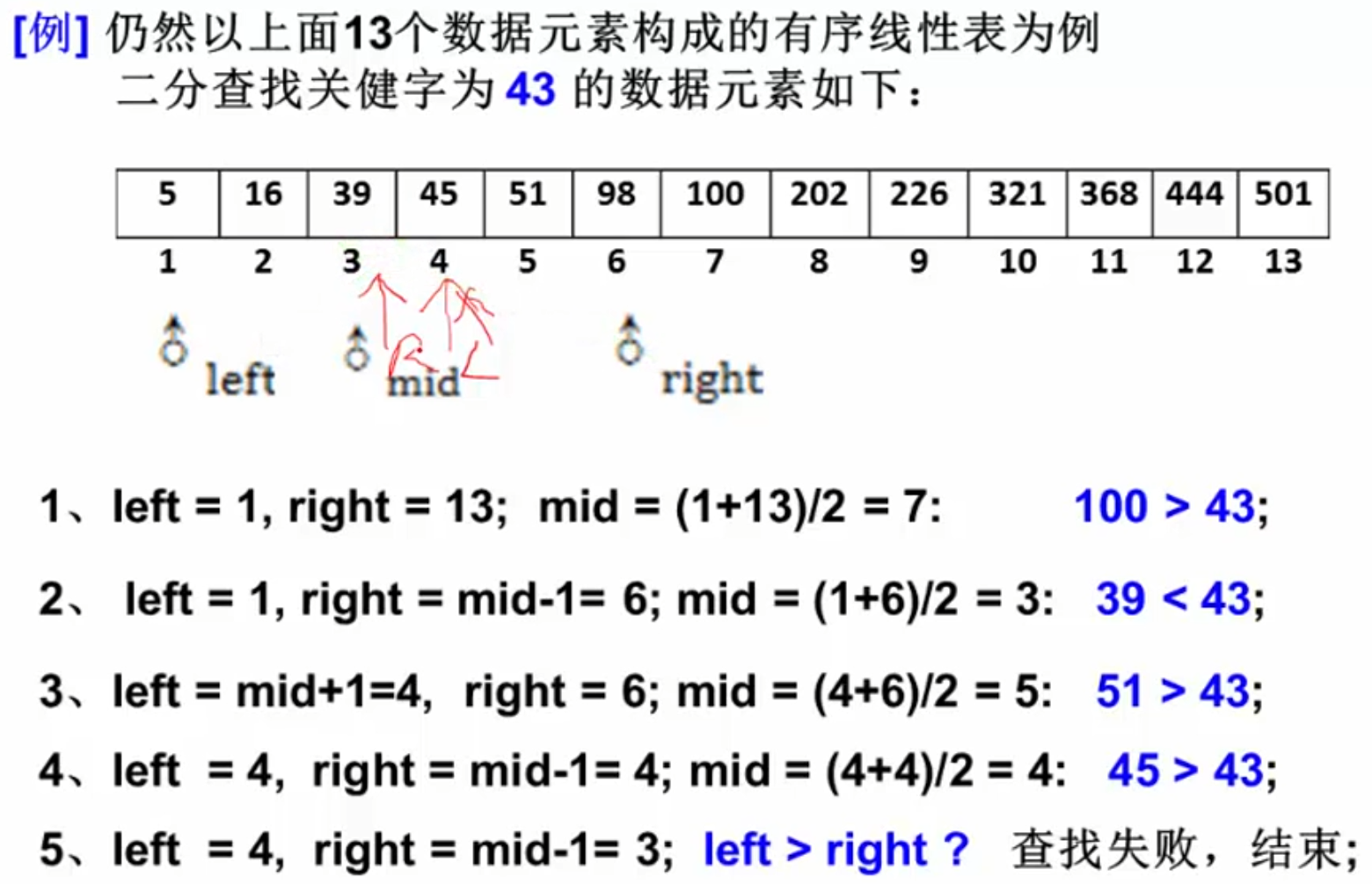
5 静态查找 5.1 顺序查找 5.2 二分查找(Binary Search) 实现算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 int BinarySearch ( List Tbl, ElementType K) int left, right, mid, NoFound=-1 ;1 ; while ( left <= right )2 ; if ( K < Tbl->Element[mid]) right = mid-1 ;else if ( K >Tbl->Element[mid]) left = mid+1 ; else return mid; return NotFound;
生成判断树
三、堆 1 基本概念 优先队列(Priority Queue):特殊的“队列 ”,取出元素的顺序是依照元素的优先权(关键字)大小,而不是元素进入队列的先后顺序。
堆的两个特性:
结构性:用数组表示的完全二叉树;
有序性:任一结点的关键字是其子树所有结点的最大值(或最小值)
最大堆(MaxHeap),也称“大顶堆“,最大值
最小堆(MinHeap),也称“小顶堆”,最小值
2 堆的操作
堆的数据结构
1 2 3 4 5 6 7 8 9 typedef struct HeapStruct *MaxHeap ;struct HeapStruct {int Size;int Capacity;
2.1 堆的创建 1 2 3 4 5 6 7 8 9 10 11 MaxHeap Create (int MaxSize) {malloc ( sizeof ( struct Heapstruct ) );malloc ((MaxSize + 1 ) * sizeof (ElementType));0 ;0 ] = MaxData;return H;
建立最大堆:将已经存在的N个元素按最大堆的要求存放在个一维数组中
方法1:通过插入操作,将N个元素一个个相继插入到一个初始为空的堆中去,其时间代价最大为0(N log N)。
方法2:在线性时间复杂度下建立最大堆。
(1)将N个元素按输入顺序存入,先满足完全二叉树的结构特性
(2)调整各结点位置,以满足最大堆的有序特性
2.2 堆的插入 将新增结点插入到从其父结点到根结点的有序序列中 ,时间复杂度:T(N) = O(log N)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void Insert (MaxHeap H, ElementType item) {int i;if (IsFu11(H)){printf ("最大堆已满" );return ;for (;H->Elements[i/2 ]<item;i/=2 )2 ];
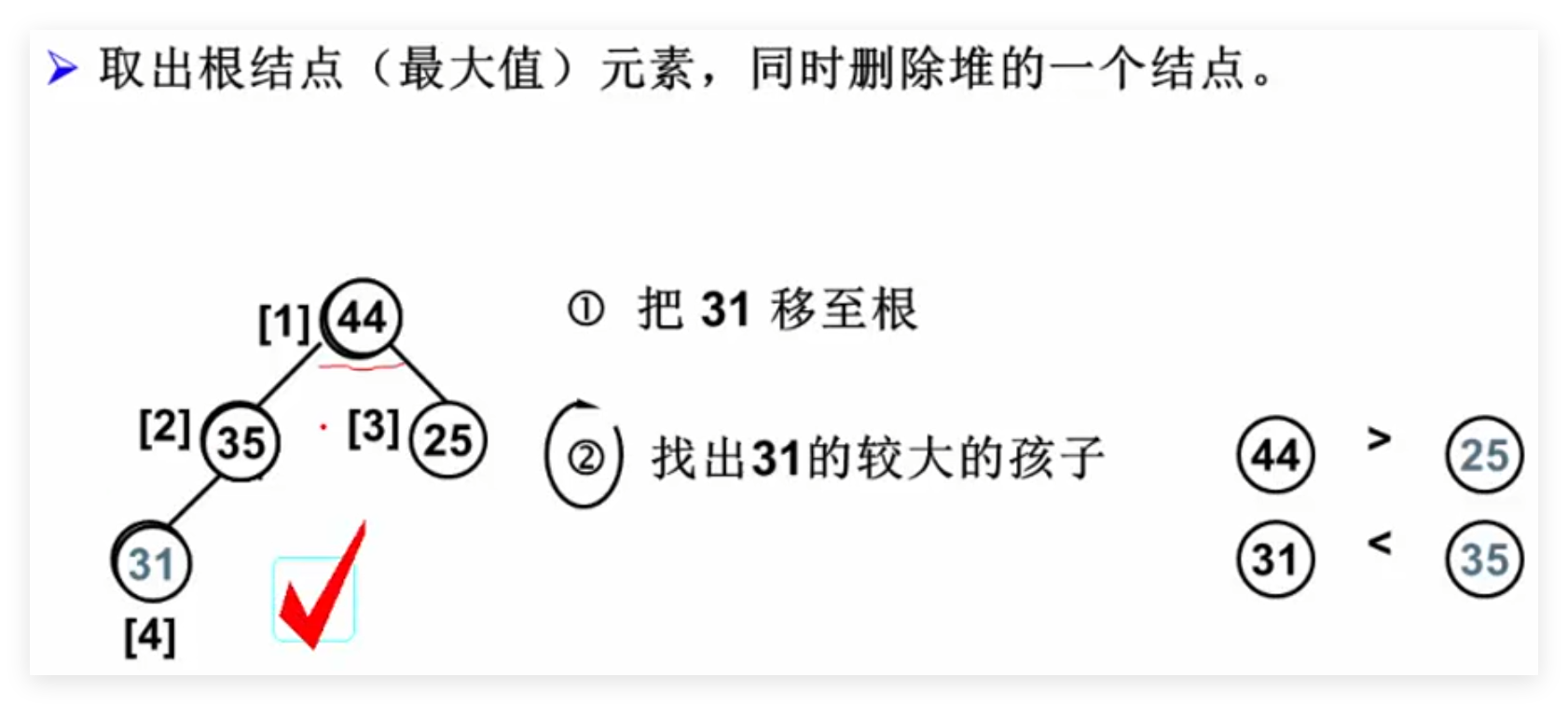
2.3 堆的删除 时间复杂度:T(N) = O (log N)
删除下标最大的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 DeleteMax ( MaxHeap H ) {int Parent, Child;if ( IsEmpty(H) ){printf ("最大堆已为空" );return ;1 ];for ( Parent = 1 ; Parent * 2 <= H -> Size; Parent =Child ){2 ;if ((Child!= H->Size) && (H -> Elements[Child] < H -> Elements[Child+1 ]))if (temp >= H -> Elements[Child]) break ;else return MaxItem;
3 哈夫曼树与哈夫曼编码 3.1 基本概念 定义:
带权路径长度(WPL):设二叉树有n个叶子结点,每个叶子结点带有权值Wₖ,从根结点到每个叶子结点的长度为Iₖ ,则每个叶子结点的带权路径长度之和就是:
最优二叉树或哈夫曼树:WPL最小的二叉树
时间复杂度:O(N log N)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 typedef struct TreeNode *HuffmanTree ;struct TreeNode {int weight;Huffman ( MinHeap H) {int i;for ( i = 1 ; i < H -> Size; i++){malloc (sizeof (struct TreeNode));return T;
特点:
没有度为1的结点;
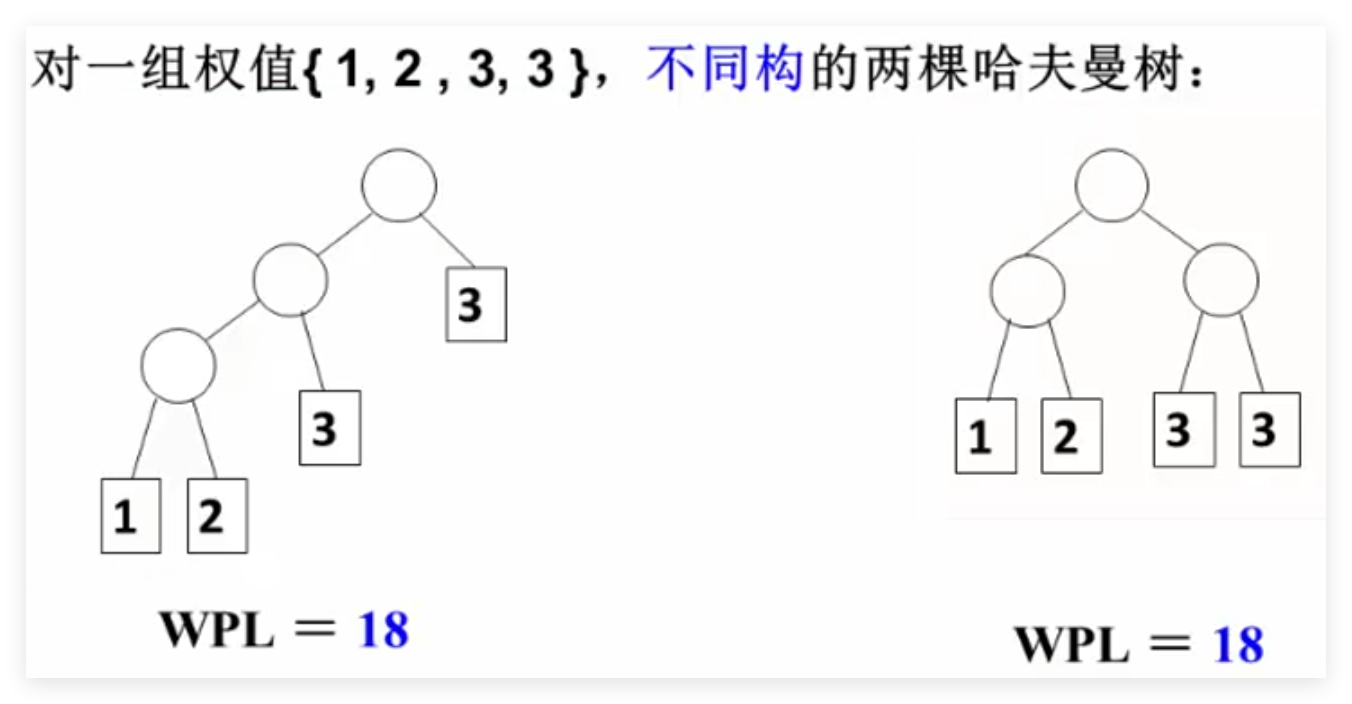
权值WPL相同,但是构造出来的树不同:
用途:它可以用来 生成文本的索引、单词频率统计和特征向量表示 等任务。 哈夫曼编码在各种需要对数据进行高效压缩和编码表示的应用中具有重要作用,能够显著减小数据的大小,提高数据传输和存储的效率。
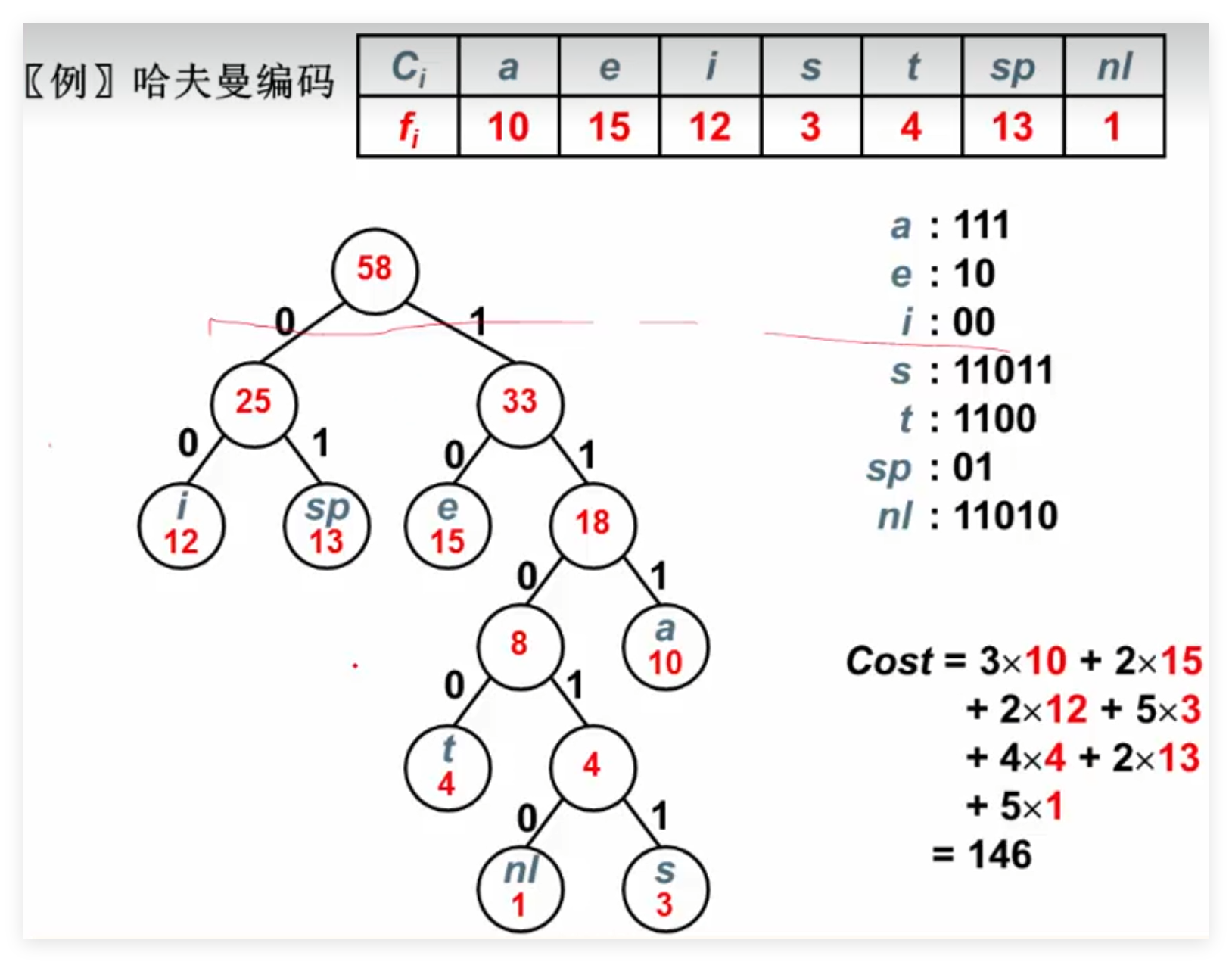
例子:
4 集合运算
集合运算:交、并、补、差,判定一个元素是否属于某一集合
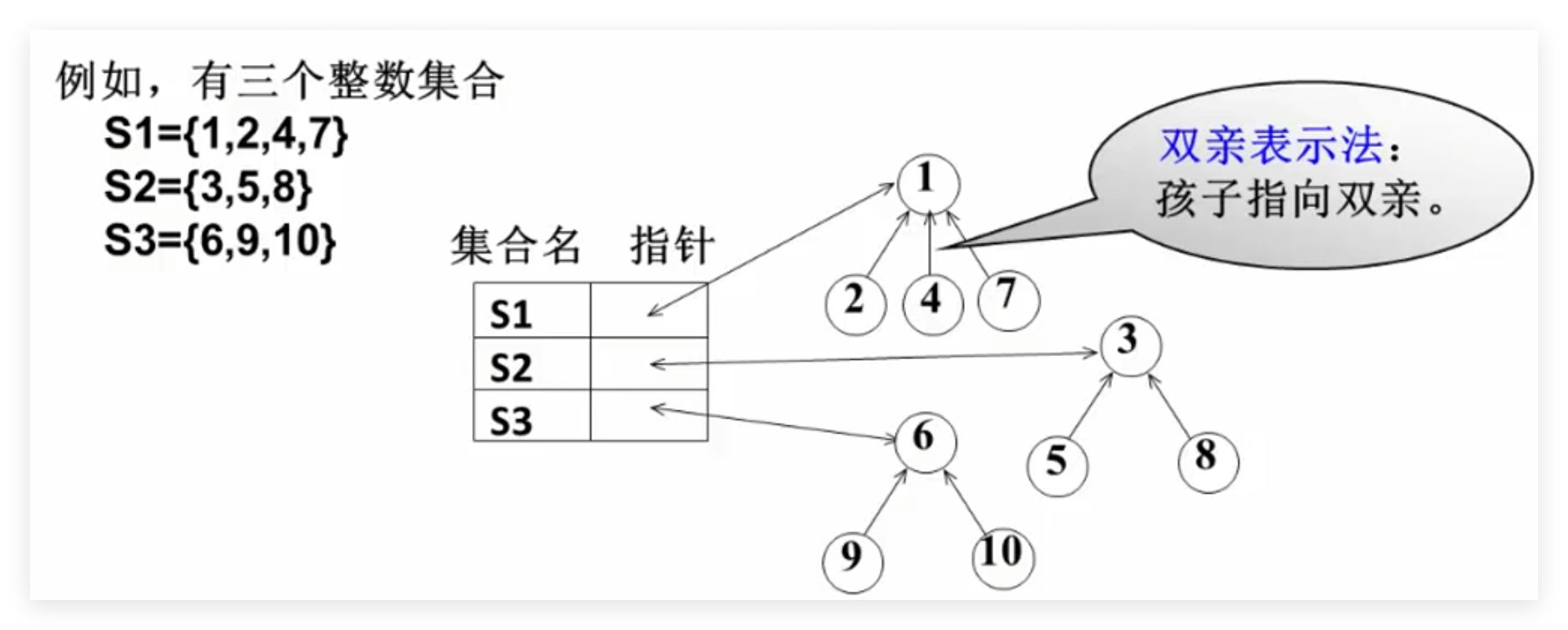
例子:
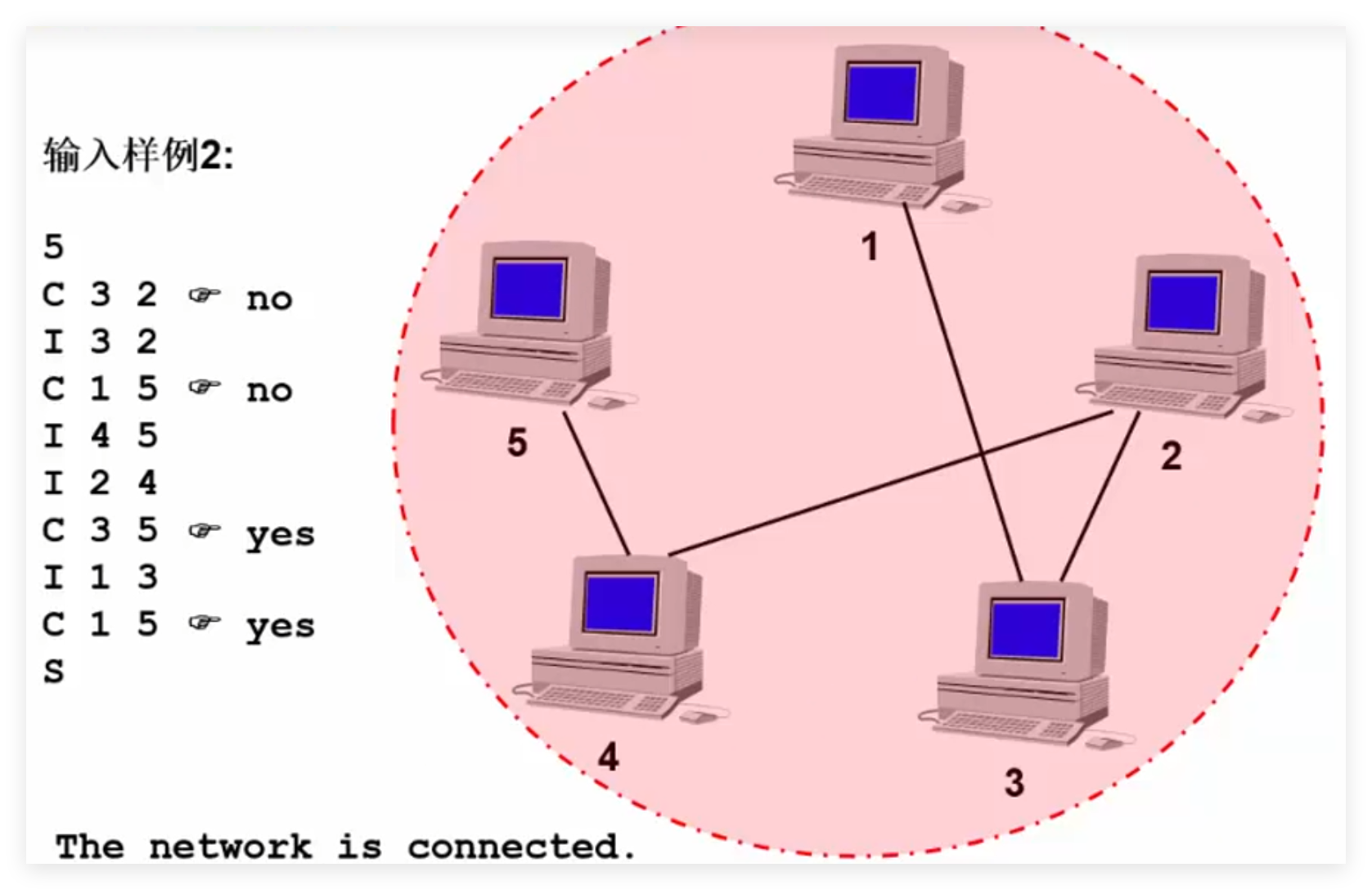
有10台电脑{1,2,3,…,9,10},已知下列电脑之间已经实现了连接:1和2、2和4、3和5、4和7、5和8、6和9、6和10
问:
2和7之间,5和9之间是否是连通的?
解决思路
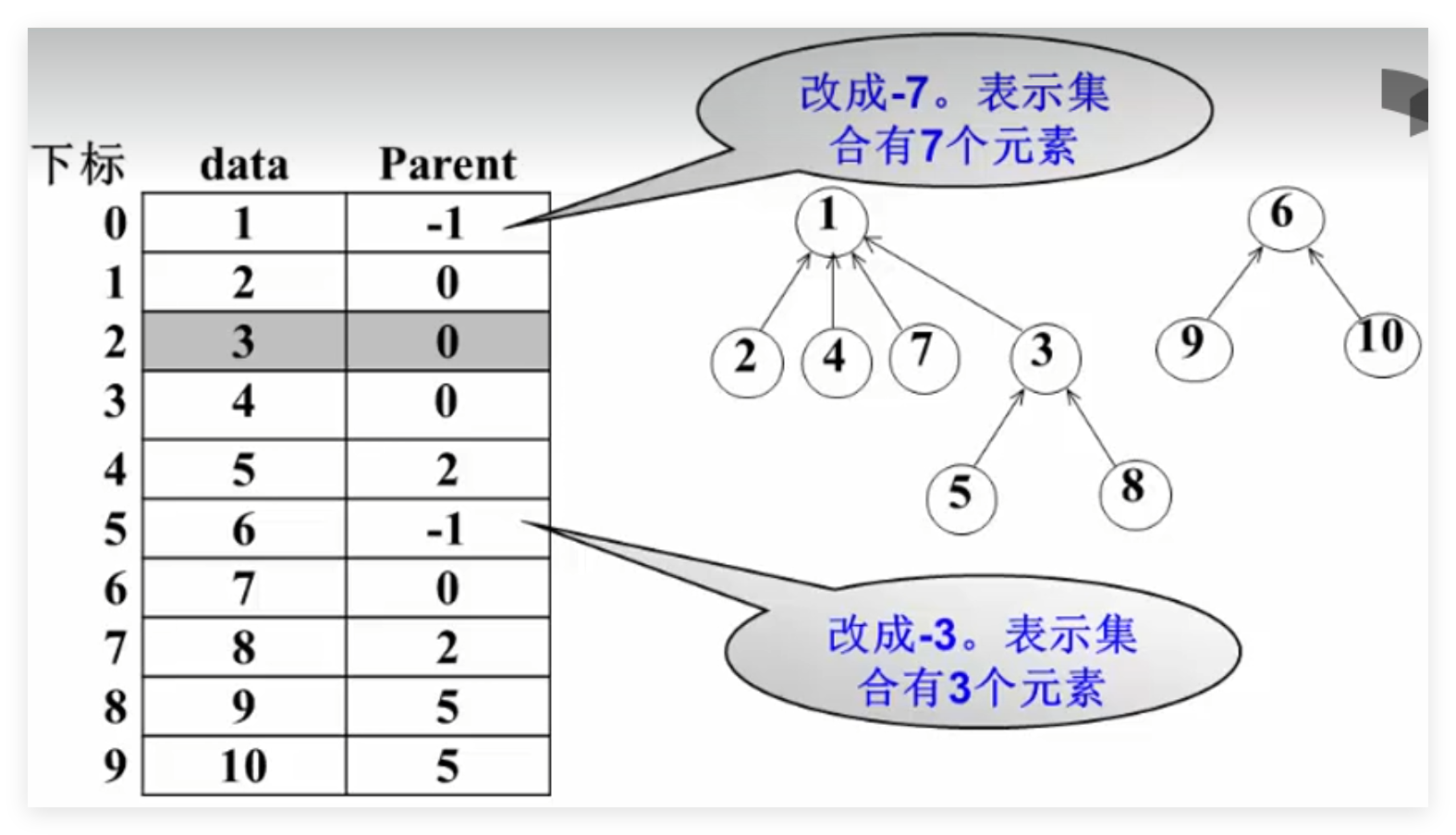
(1)将10台电脑看成10个集合{1},{2},{3},…,{9},{10};
(2)已知一种连接“x和y”,就将x和y对应的集合合并;
(3)查询“x和y是否是连通的”就是判别x和y是否属于同集合。
1 2 3 4 5 typedef struct {int Parent;
4.1 集合查找 1 2 3 4 5 6 7 8 9 10 11 12 int Find (SetType S[], ElementType X) {int i;for ( i = 0 ; i < MaxSize && S[i].Data != X; i++);if ( i >= MaxSize ) return -1 ;for ( ; S[il.Parent >= 0 ; i = S[i].Parent);return i;
4.2 集合的并运算
分别找到X1和X2两个元素所在集合树的根结点;
如果它们不同根,则将其中一个根结点的父结点指针设置成另一个根结点的数组下标。
1 2 3 4 5 6 void Union ( SetType s[ ], ElementType X1, ElementType X2) {int Rootl,Root2;if (Root1 != Root2 ) S[Root2].Parent = Root1;
简化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 typedef int Elementrype;typedef int setName;typedef ElementType SetType[Maxsize];Find (SetType S, ElementType X ) for ( ; S[X] >= 0 ; X = S[X]);return X;void Union ( SetType S, SetName Root1,SetName Root2 ) {
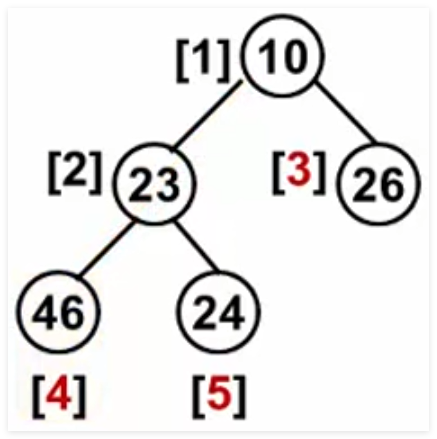
5 堆中的路径 5.1 程序设计题 将一系列给定数字插入一个初始为空的小顶堆H。随后对任意给定的下标“ i ”,打印从H[i]到根结点的路径。
输入样例:
5 3
46 23 26 24 10
5 4 3
输出样例:
24 23 10
46 23 10
26 10
程序设计:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 #define MAXN 1001 #define MINH -10001 int H[MAXN], size;void Create () {0 ;0 ] = MINH;void insert (int X) {int i;for (i = ++size; H[i/2 ] > X; i /= 2 )2 ];int main () {int n, m, x, i, j;scanf ("%d %d" , &n, &m);for ( i = 0 ; i < n; i++){scanf ("%d" , &x);for (i = 0 ; i < m; i++){scanf ("%d" , &j);printf ("%d" ,H[j]);while ( j > 1 ){ 2 ;printf (" %d" , H[j]);printf ("\n" );return 0 ;
例:判断系统是否连通
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 int main () { int n;char in;scanf ("&d\n" , &n);do {scanf ("%c" , &in);switch (in){case 'I' : Input connection (S) ; break ;case 'c' : Check connection (S) ; break ;case 'S' : Check network (S, n) ; break ;while (in != 'S' );return 0 ;void Input_connection ( SetType S) {scanf ("%d %d\n" , &u, &v);-1 );-1 );if (Rootl != Root2 )void Check_connection ( SetType S) {scanf ("%d %d\n" , &u, &v);-1 );-1 );if (Rootl == Root2 )printf ("yes\n" );else printf ("No\n" );
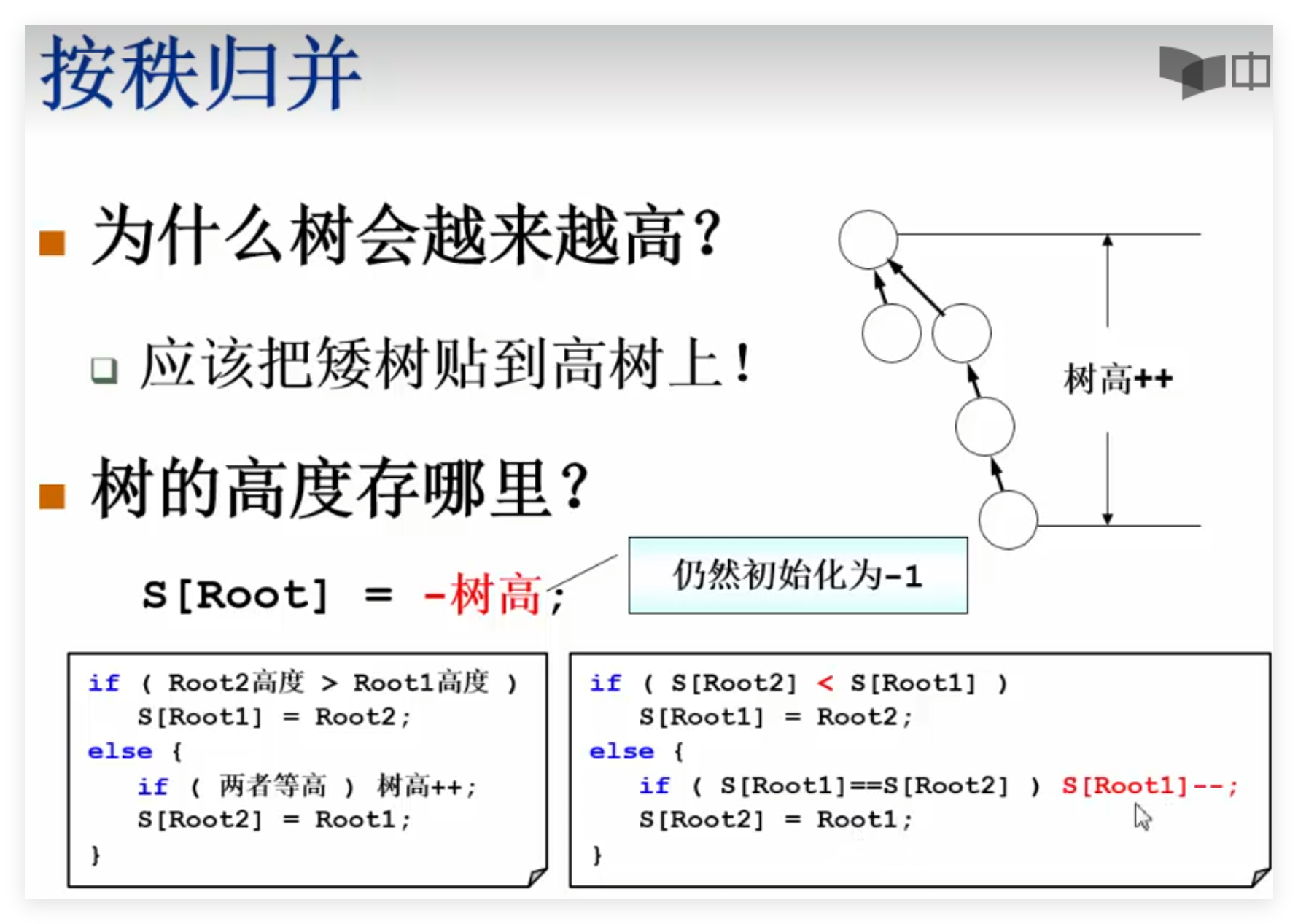
5.2 按秩归并(优化Union)
另一种做法:比规模,即把小树贴到大树上。S[Root]= -元素个数;
1 2 3 4 5 6 7 8 9 10 11 void Union ( SetType S, SetName Root1, SetName Root2) {if (S[Root2] < S[Root1]){else {
5.3 路径压缩(优化Find) 1 2 3 4 5 6 SetName Find ( SetType S, ElementType X) {if ( S[X]<0 ) return X;else return S[X]=Find(S,S[X]);
四、图 1 基本概念 1.1 抽象数据类型 类型名称:图(Graph)
数据对象集:G(V, E)由一个非空的有限顶点集合V和一个有限边集合E组成。
特点:
表示“多对多”的关系
包含
一组顶点:通常用V(Vertex)表示顶点集合
一组边:通常用E(Edge)表示边的集合
边是顶点对:(v,w)∈E,其中v,w∈V
有向边< v, w >表示从v指向w的边(单行线)
不考虑重边和自回路
1.2 邻接矩阵 1 2 3 4 5 6 7 8 9 10 优点"邻接点" (有边直接相连的顶点)"度" (从该点发出的边数为"出度" 指向该点的边数为“入度”)0 元素的个数0 元素的个数是“出度”;对应列非0 元素的个数是"入度"
1.3 邻接表 1 2 3 4 5 6 - 方便找任一顶点的所有“邻接点”2 E个结点(每个结点至少2 个域)
2 图的遍历 2.1 深度优先搜索 DFS:Depth First Search
1 2 3 4 5 6 void DFS (Vertexy) {true ;for ( V的每个邻接点W )if ( !visited[w] )
若有N个顶点、E条边,时间复杂度是
用邻接表存储图,有O(N+E);
用邻接矩阵存储图,有O(N²);
2.2 广度优先搜索 BFS: Breadth First Search
伪码描述
1 2 3 4 5 6 7 8 9 10 11 12 void BFs (VertexV) {true ;while (!IsEmpty(Q)){for (V的每个邻接点W)if (!visited[w]){true ;
若有N个顶点、E条边,时间复杂度是
用邻接表存储图,有O(N+E);
用邻接矩阵存储图,有O(N²);
3 图的表示 3.1 邻接矩阵表示 1 2 3 4 5 6 7 8 typedef struct GNode *PtrToGNode ;struct GNode {int Nv;int Ne;typedef PtrToGNode MGraph;
初始化一个有VertexNum个顶点但没有边图
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef int Vertex;CreateGraph (int VertexNum) {malloc (sizeof (struct GNode));0 ;for (V=0 ; V<Graph->Nv; V++)for (W=0 ; W<Graph->Nv; W++)0 ;return Graph;
向MGraph中插入边
1 2 3 4 5 6 7 8 9 10 11 12 13 typedef struct ENode *PtrToENode ;struct ENode {typedef PtrToENode Edge;void InsertEdge (MGraph Graph, Edge E) {
完整建立MGraph
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 MGraph BuildGraph () {int Nv, i;scanf ("&d" , &Nv);scanf ("&d" , &(Graph->Ne));if ( Graph->Ne != 0 ){malloc (sizeof (struct ENode));for (i=0 ; i<Graph->Ne; i++){scanf ("%d %d %d" , for (V=0 ; V<Graph->Nv; V++)scanf ("&c" ,&(Graph->Data[V]));return Graph;
3.2 邻接表表示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 typedef struct GNode *PtrToGNode ;struct GNode {int Nv; int Ne; typedef PtrToGNode LGraph;typedef struat Vnode {typedef struct AdjVNode *PtrToAdjVNode ;struct AdjVNode {
LGraph初始化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 typedef int Vertex;CreateGraph (int VertexNum) {malloc (sizeof (structGNode));0 ;for (V=0 :V<Graph->Nv;V++)NULL ;return Graph;
LGraph插入边:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void InsertEdge (LGraph Graph,EdgeE) {malloc (sizeof (struct AdjVNode));malloc (sizeof (struct AdjVNode));
4 图的最短路径 4.1 单源最短路径 无权单源最短
1 2 3 4 5 6 7 8 9 10 11 12 13 void Unweighted (Vertex S) while ( !IsEmpty(Q) ){for ( V的每个邻接点W )if ( dist[w]==-1 ){1 ;
有无权单源最短
4.1.1 Dijkstra算法 其他类似问题
要求数最短路径有多少条
count[s]=1;
如果找到更短路:count[w] = count[V];
如果找到等长路:count[w] += count[V];
要求边数最少的最短路
count[s]=0
如果找到更短路:count[w] = count[V] + 1;
如果找到等长路:count[w] = count[V] + 1;
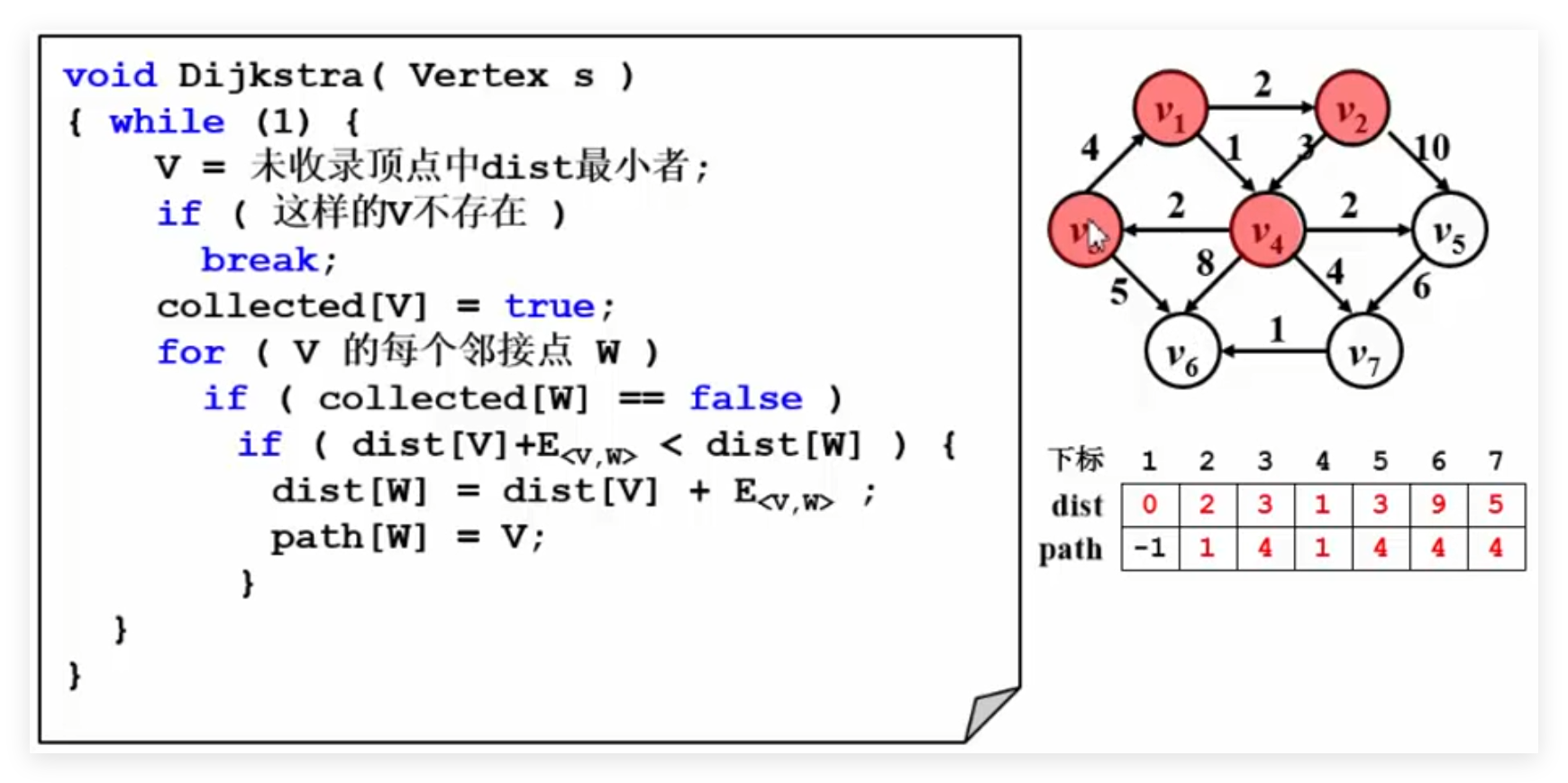
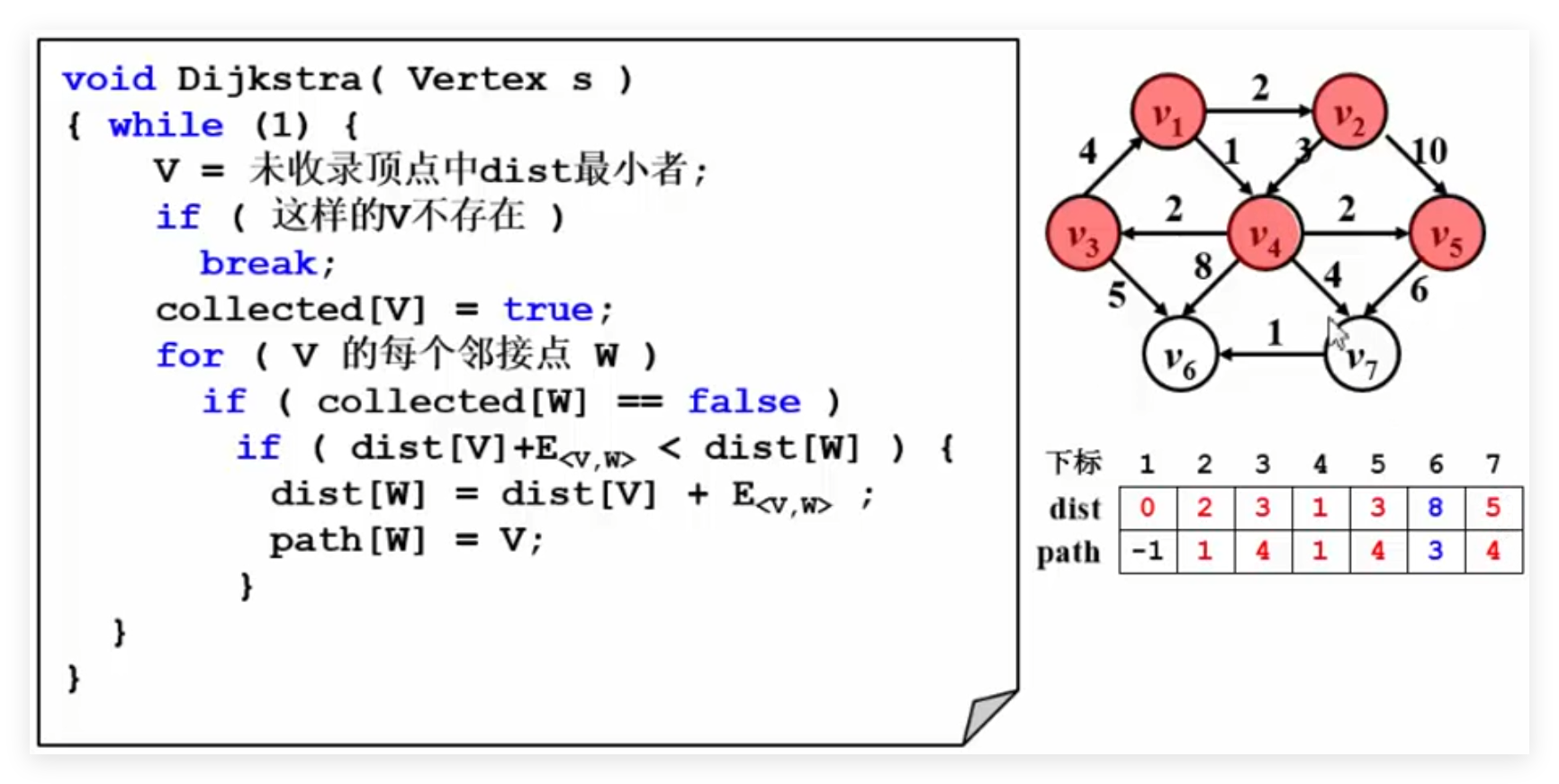
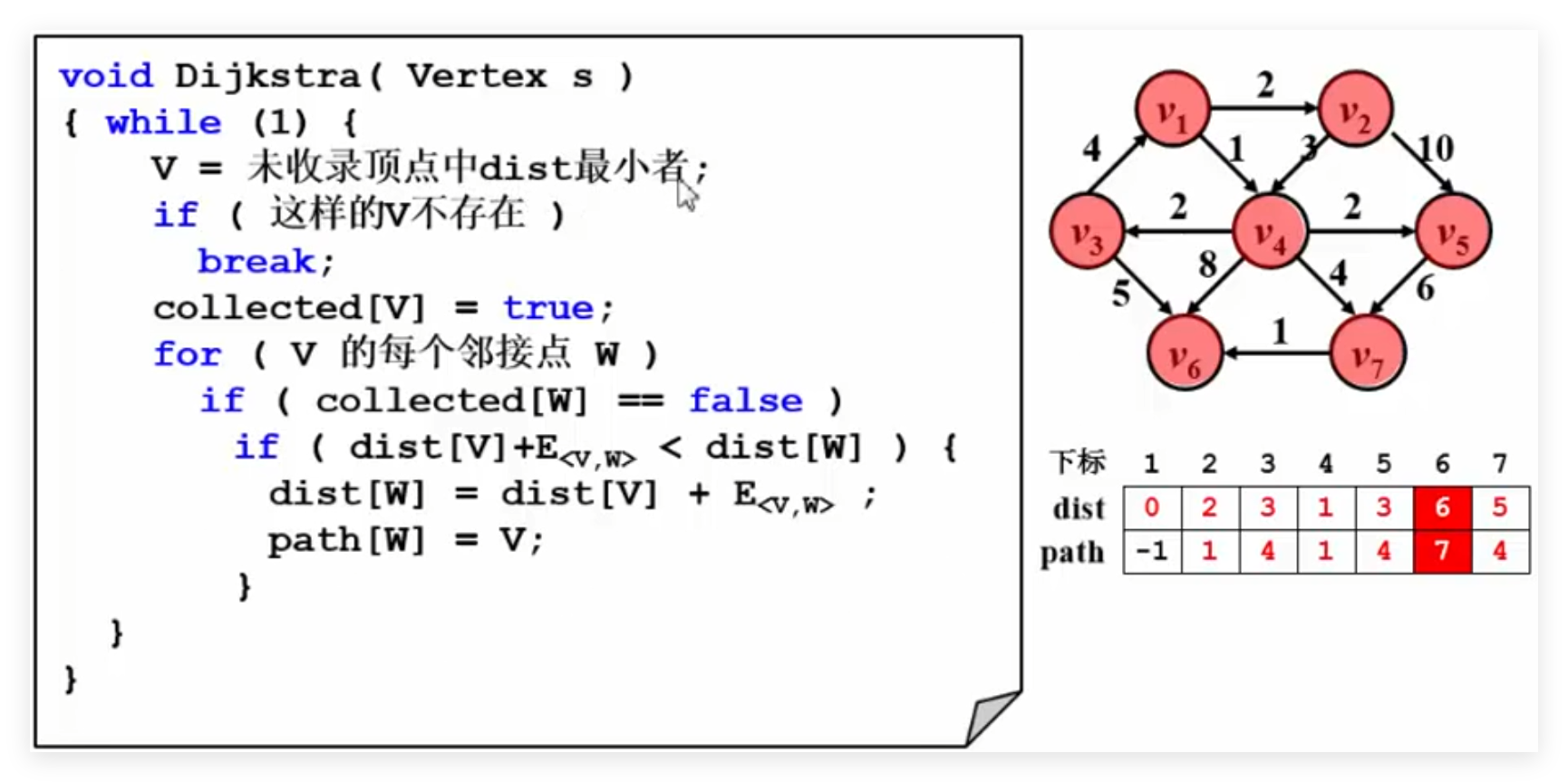
练习 旅游问题 核心算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 void Dijkstra (Vertex s) {while (1 ){if (这样的V不存在)break ;true ;for (V 的每个邻接点 W)if (collected[W] == false )if (dist[V] + E<v,w> < dist[W]){else if ((dist[V] + E<v,w> == dist[W])&&(cost[V] + C<v,w> <cost[W])){
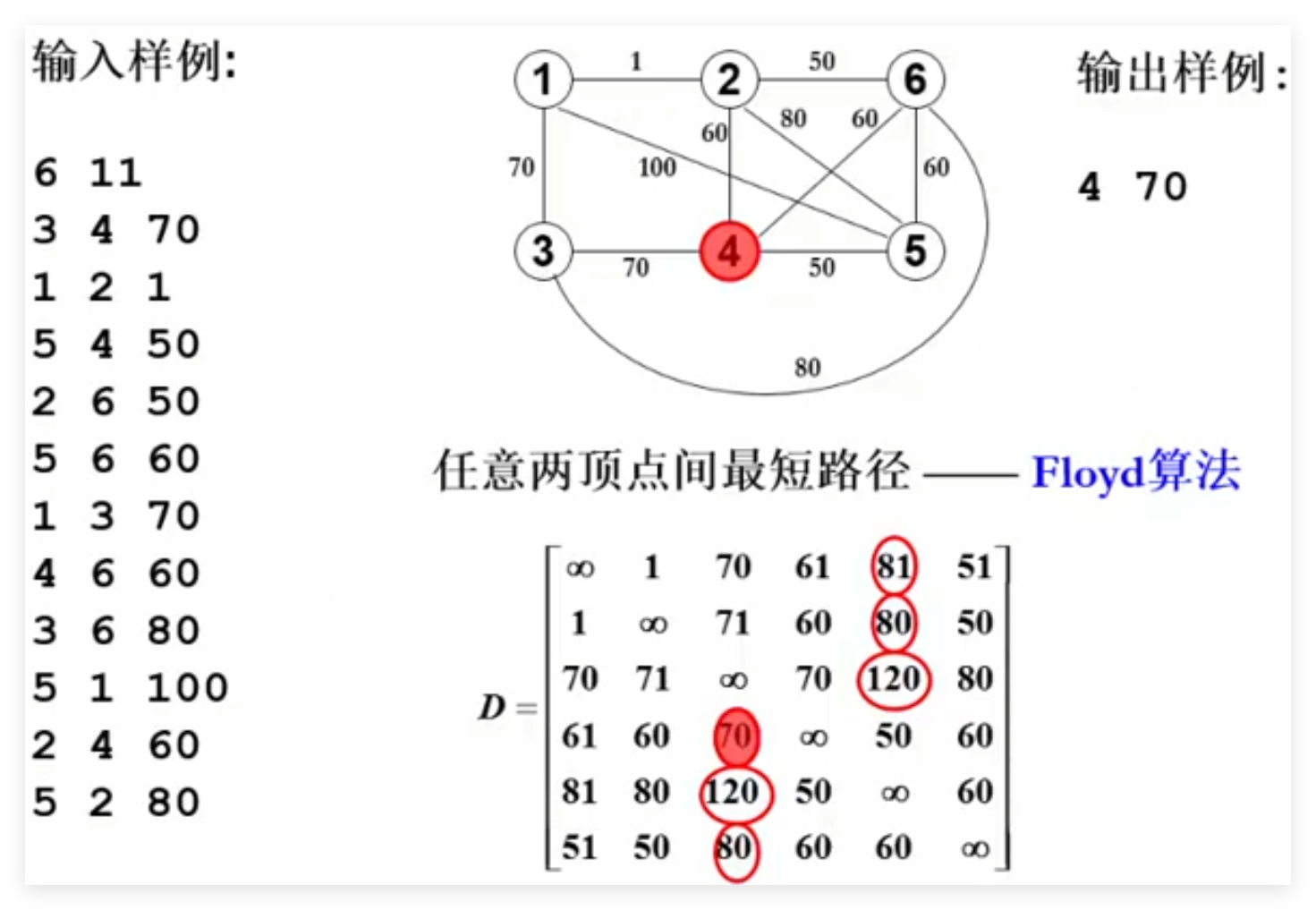
4.2 多源最短路径 Floyd算法(时间复杂度V³):
1 2 3 4 5 6 7 8 9 10 11 12 13 void Floyd () {for (i = 0 ; i < N; i++)for (j = 0 ; j < N; j++){for (k = 0 ; k < N; k++)for (i = 0 ; i < N; i++)for (j = 0 ; j < N; j++)if (D[i][k] + D[k][j] < D[i][j]){
4.3 练习 程序设计:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 void FindAnimal (MGraph Graph) {for (i = 0 ; i< Graph->Nv; i++){if (MaxDist == INFINITY){printf ("0\n" );return ;if (MinDist > MaxDist){1 ;printf ("%d %d\n" , Animal, MinDist);int main () {return 0 ;FindMaxDist ( WeightType D[][MaxVertexNum], Vertex i, int N) {0 ;for (j = 0 ; j < N; j++)if (i != j && D[i][j] > MaxDist )return MaxDistint VertexNum){malloc (sizeof (struct GNode));0 ;for (V = 0 ; V < Graph->Nv; V++)for (W = 0 ; W < Graph->Nv; W++)return Graph;void InsertEdge ( MGraph Graph, Edge E) {BuildGraph () {int Nv, i;scanf ("%d" , &Nv);"名d" , &(Graph->Ne));if (Graph->Ne != 0 ){malloc (sizeof (struct ENode)):for (i = 0 ; i < Graph->Ne; i++){scanf ("%d %d %d" , &E->V1, &E->V2, &E->Weight);for (V = 0 ; V<Graph->Nv; V++)scanf ("%c" , &(Graph->Data[V]));return Graph;void Floyd (MGraph Graph, WeightTypr D[][MaxVertexNum]) {for (i = 0 ; i < N; i++)for (j = 0 ; j < N; j++){for (k = 0 ; k < N; k++)for (i = 0 ; i < N; i++)for (j = 0 ; j < N; j++)if (D[i][k] + D[k][j] < D[i][j]){if ( i == j && D[i][j] < 0 )return false ;
五 相应算法 1 贪心算法 概念:每一步都要权重最小的边
约束:
只能用图里面有的边
只能正好用掉n-1条边
不能有回路
1.1 Prim算法(稠密图) 最小生成树——让一棵小树长大:
向生成树中加一条边都一定构成回路,最小生成树存在<->图连通
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void Prim () {while ( 1 ){if (这样的V不存在)break ;0 ;for ( V 的每个邻接点 W )if (dist[W] != 0 )if (E(v,w) < dist[W]){if (MST中收的顶点不到|V|个)
1.2 Kruskal算法 稀疏图——时间复杂度:|E|log|E|
1 2 3 4 5 6 7 8 9 10 11 12 13 void Kruskal ( Graph G ) {while ( MST中不到|V|-1 条边 && E中还有边){if (E(v,w)不在 MST 中构成回路)else if (MST中不到IV!-1 条边)
2 拓扑排序
拓扑序:如果图中从v到w有一条有向路径则V一定排在W之前。满足此条件的顶点序列称为一个拓扑序
获得一个拓扑序的过程就是拓扑排序
AOV(Activity On Vertex)如果有合理的拓扑序,则必定是有向无环图(Directed Acyclic Graph,DAG)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void Topsort () {for ( 图中每个顶点V )if (Indegree[V] == 0 )while ( !IsEmpty(Q) ){for ( V的每个邻接点W )if (--Indegree[w] == 0 )if (cnt != |V|)
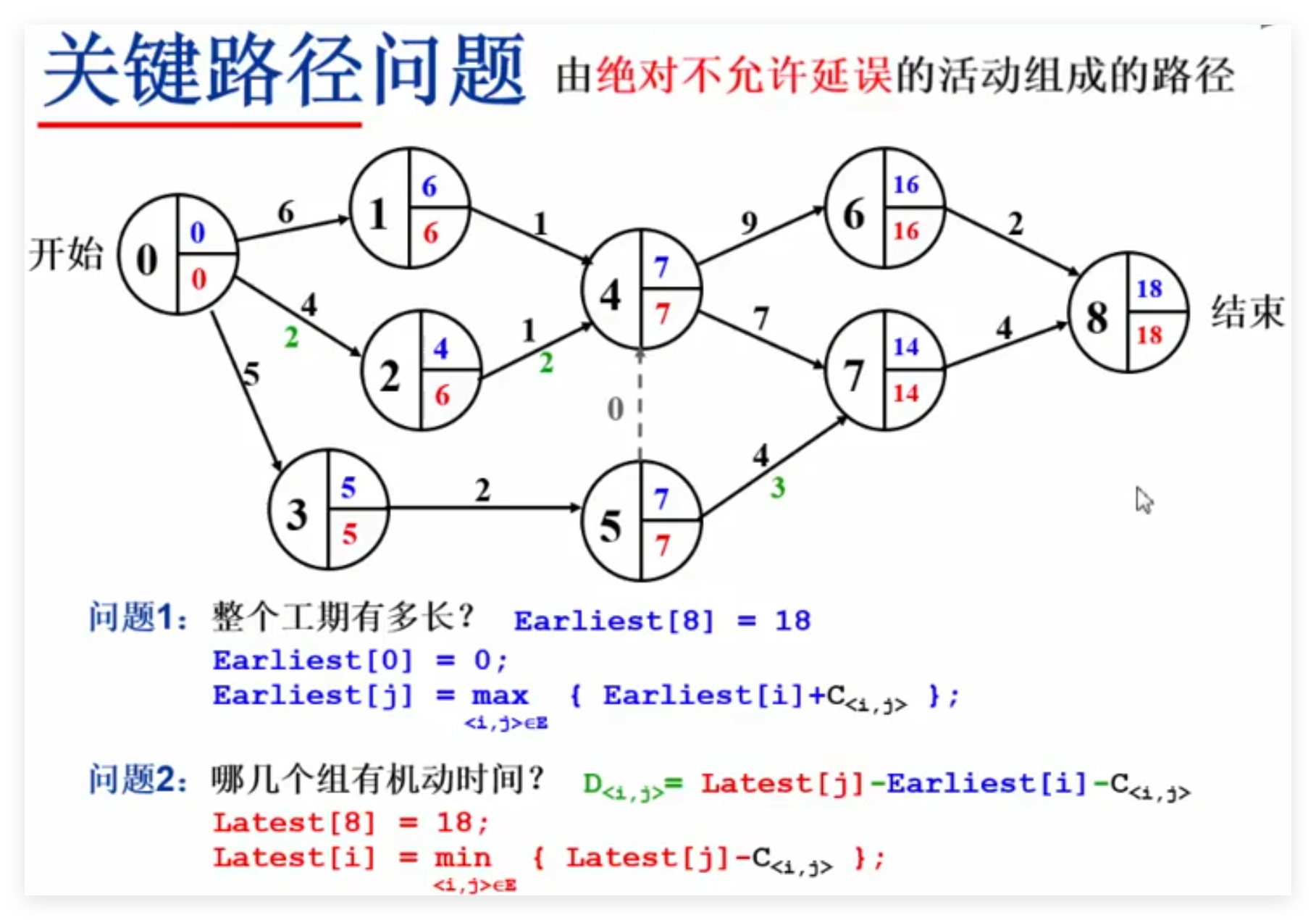
3 关键路径问题 AOE(Activity On Edge)网络:一般用于安排项目的工序
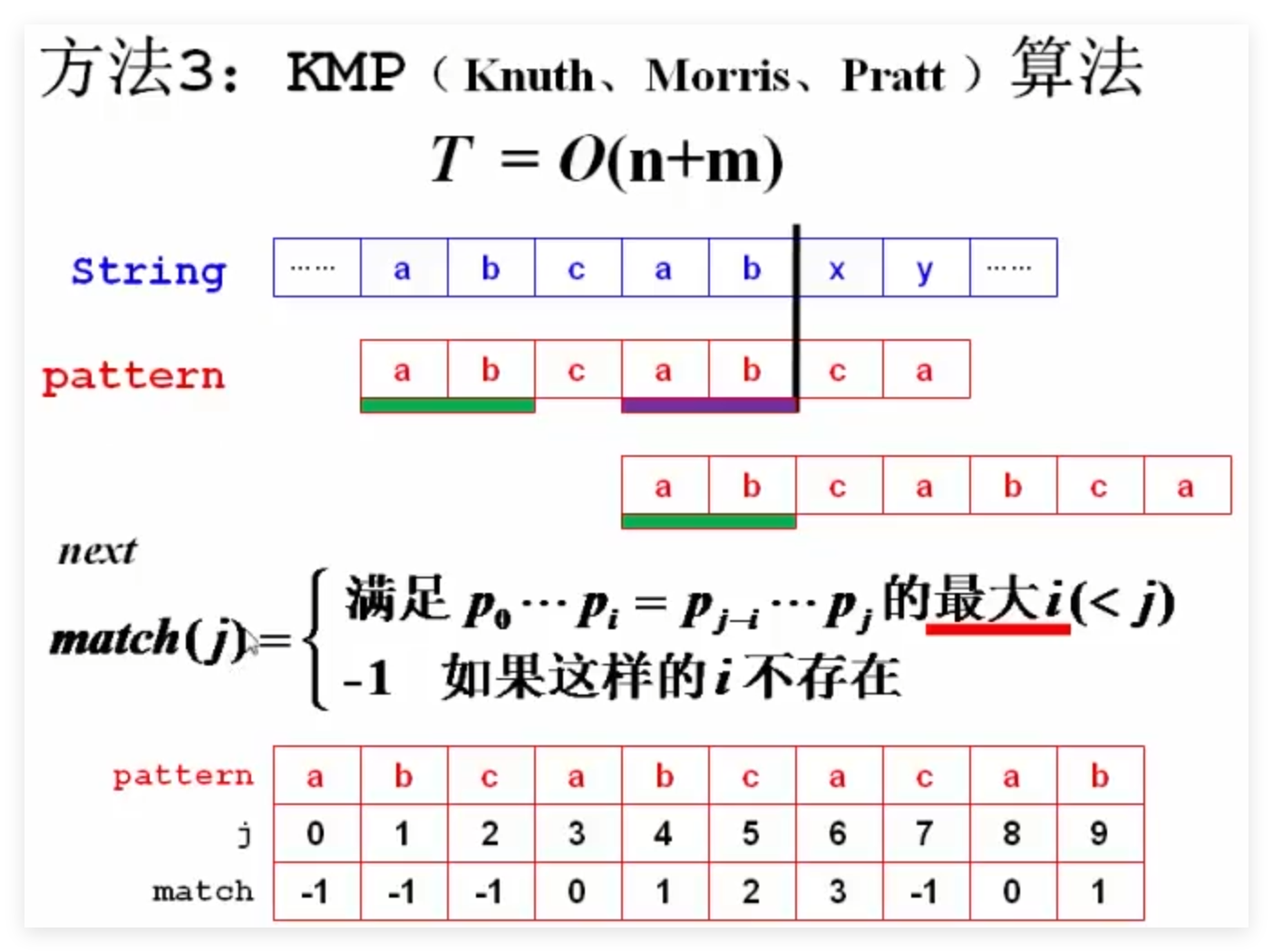
4 KMP算法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 #include <stdio.h> #include <string.h> typedef int Position;#define NotFound -1 int main () {char string [] = "This is a simple example." ;char pattern[] = "simple" ;string , pattern);if ( p == NotFound ) printf ("Not Found.\n" );else printf ("%s\n" , string + p);return 0 ;KMP (char *string , char *pattern) { int n = strlen (string );int m = strlen (pattern);int s, p, *match;if (n < m) return NotFound;int *)malloc (sizeof (int ) *m);0 ;while ( s < n && p < m){if (string [s] == pattern[p]){else if (p > 0 ) p = match[p-1 ] + 1 ;else s++;return ( p = m) ? (s - m) : NotFound;void BuildMatch (char *pattern, int *match) {int i, j;int m = strlen (pattern);0 ] = -1 ;for (j = 1 ; j < m; j++){-1 ];while ((i >= 0 ) && (pattern[i+1 ] != pattern[j]))if (pattern[i+1 ] == pattern[j])1 ;else match[j] = -1 ;
六、排序 没有一种排序是任何情况下都表现最好的
6.1 冒泡排序 优点:
在链表中排序性能比较好
在两个元素相等时候不做交换,一定程度上保证了稳定性
时间复杂度:
最好情况:顺序T=O(N)
最坏情况:逆序T=O(N²)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 void Bubble_Sort (ElementType A[], int N) {for (P=N-1 ;P>=0 ;P--){0 ;for (i = 0 ; i < P; i++){if (A[i] > A[i+1 ]){1 ]);1 ;if (flag==0 ) break ;
6.2 插入排序 时间复杂度:
最好情况:顺序T=O(N)
最坏情况:逆序T=O(N²)
1 2 3 4 5 6 7 8 9 void Insertion_Sort (ElementType A[], int N) {for (P = 1 ; P < N; P++){for (i = P; i > 0 && A[i-1 ] > Tmp; i--)-1 ];
6.3 希尔排序 最坏:T=O(N²)
1 2 3 4 5 6 7 8 9 10 11 12 void shell_sort (ElementType A[], int N) {for (D = N / 2 ; D > 0 ; D /= 2 ){for (P = D; P < N; P++){for (i = P; i >= D && A[i-D] > Tmp;i-=D)
6.4 堆排序 1 2 3 4 5 6 7 8 9 void Heap_Sort (ElementType A[], int N) {for (i = N/2 ; i >= 0 ; i--)for (i = N-1 ; i > 0 ; i--){0 ], &A[i]);0 , i);
6.5 快速排序 分而治之
伪码描述:
1 2 3 4 5 6 7 8 void Quicksort (ElementType A[], int N) {if (N < 2 ) return ; 2 个独立子集:
当递归的数据规模充分小,则停止递归,直接调用简单排序(例如插入排序)
代码实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 void Quicksort ( ElementType A[], int Left, int Right ) {if (Cutoff <= Right - Left){1 ;for ( ; ; ){while (A[++i] < Pivot){}while (A[--j] > Pivot){}if (i<j)else break ;-1 ]);-1 );1 , Right);else 1 );void Quick_sort (ElementType A[],int N) {0 , N-1 );Median3 ( ElementType A[], int left, int Right ) {int Center = (Left + Right) / 2 ;if (A[ Left ] > A[ Center ])if (A[ Left ] > A[ Right ])if ( A[Center] > A[ Right] )-1 ]);return A[ Right-1 ];
6.6 表排序 最好情况:初始即有序
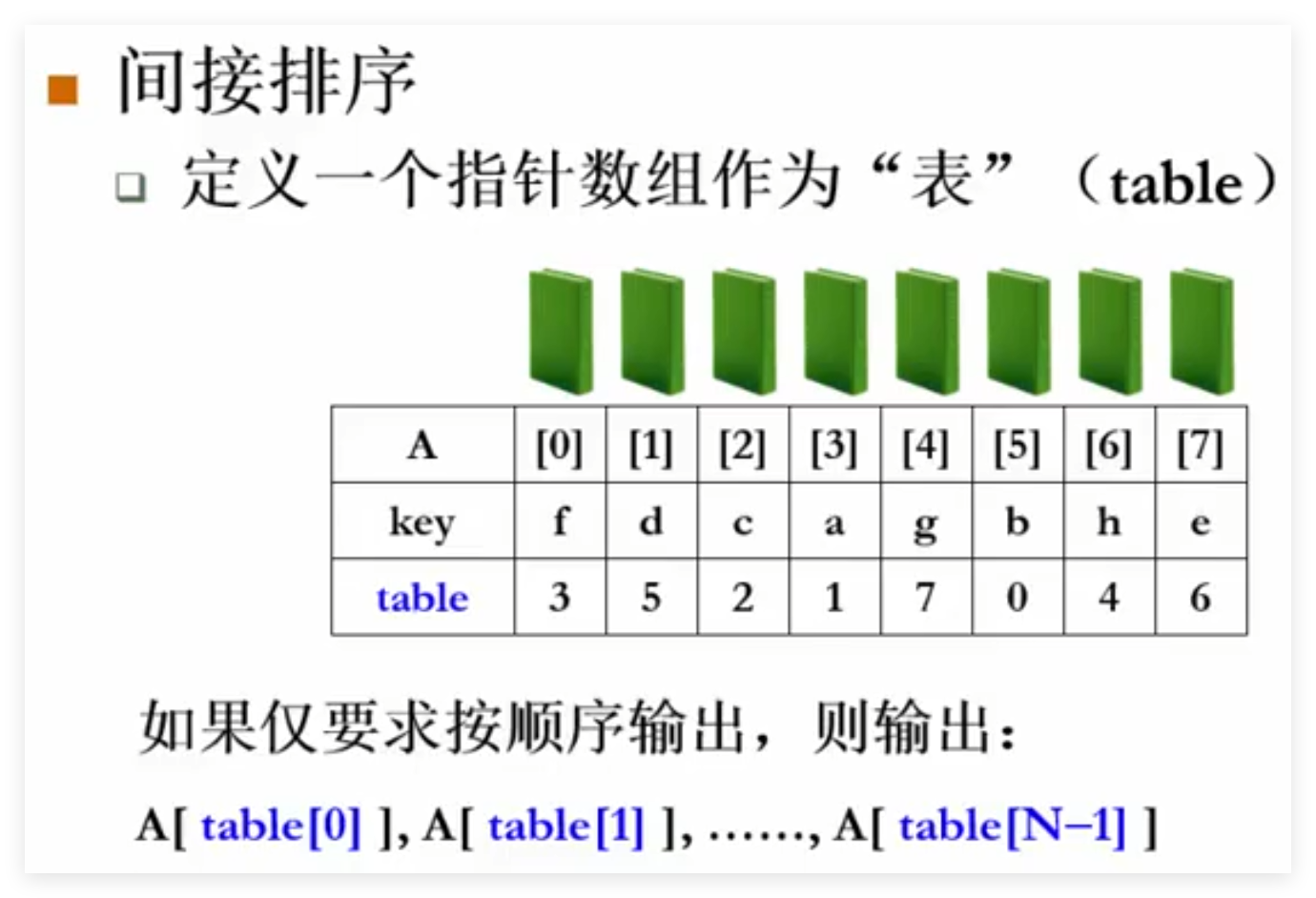
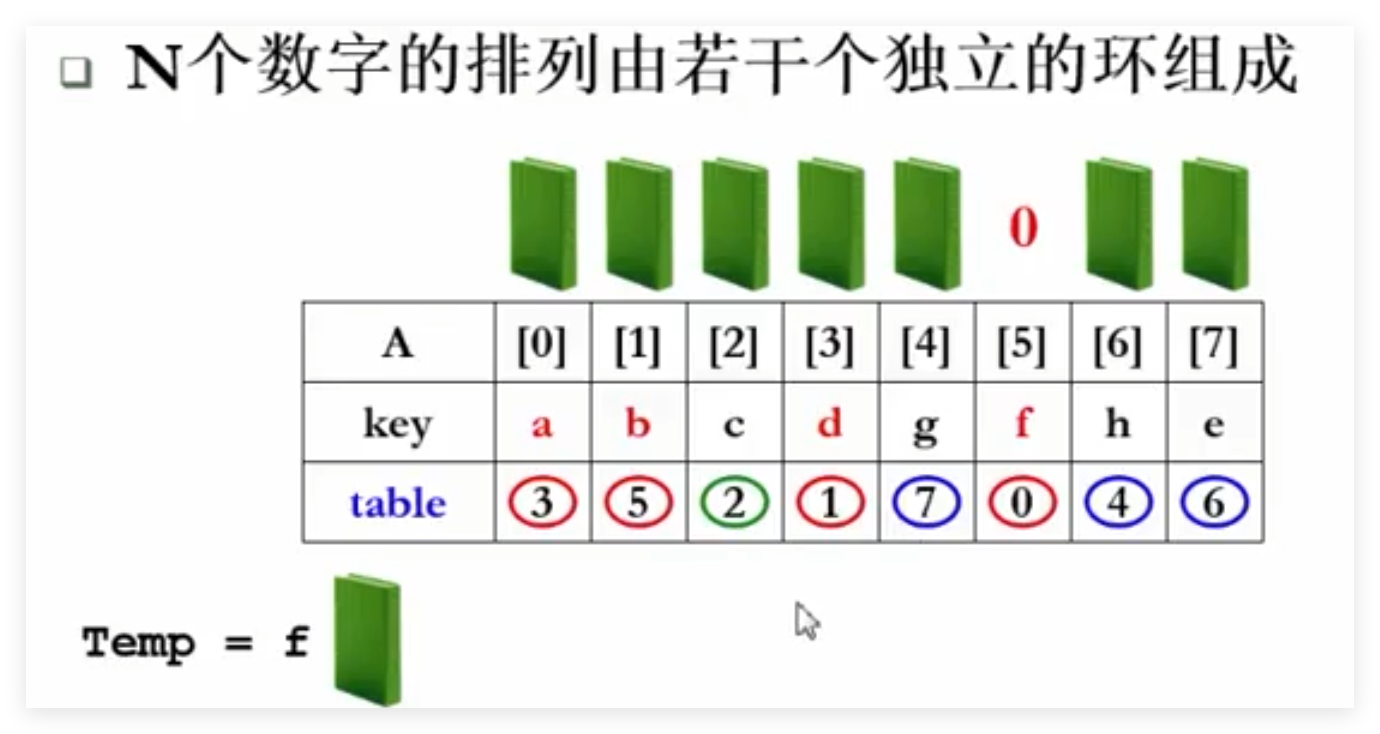
有⌊N/2⌋个环,每个环包含2个元素
需要⌊3N/2⌋次元素移动
T=O(m*N),m是每个A元素的复制时间。
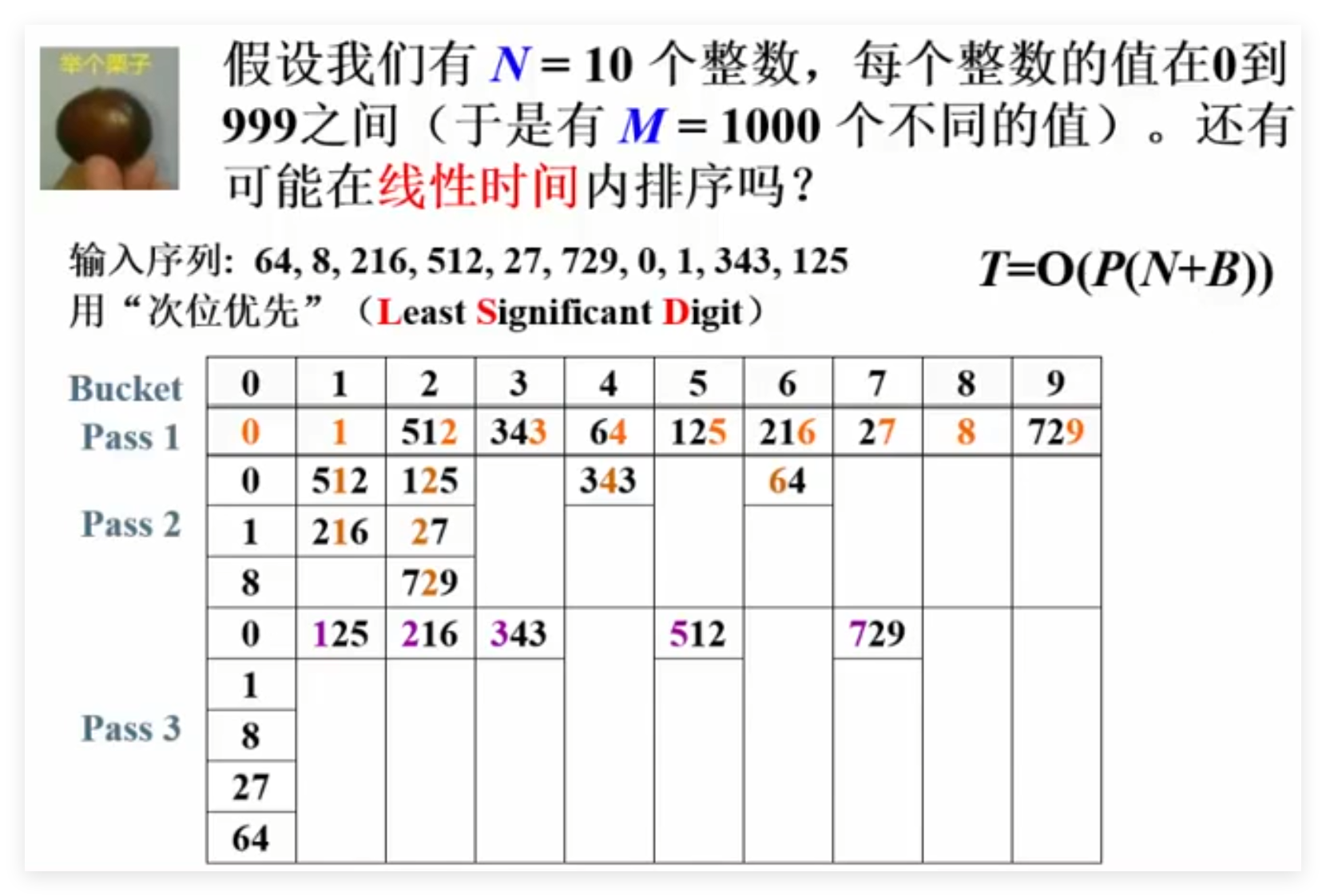
6.7 桶排序 假设我们有N个学生,他们的成绩是0到100之间的整数(于是有M=101个不同的成绩值)。如何在线性时间内将学生按成绩排序?
思想:将成绩分成101个桶,然后不停的插入学生成绩,并将其放入不同的桶中,用链表连接起来。
时间复杂度:T(N,M) = O(M+N)
1 2 3 4 5 6 7 8 9 void Bucket_Sort (ElementType A[],int N) {while (读入1 个学生成绩grade)for (i = 0 ; i < M; i++){if ( count[i])
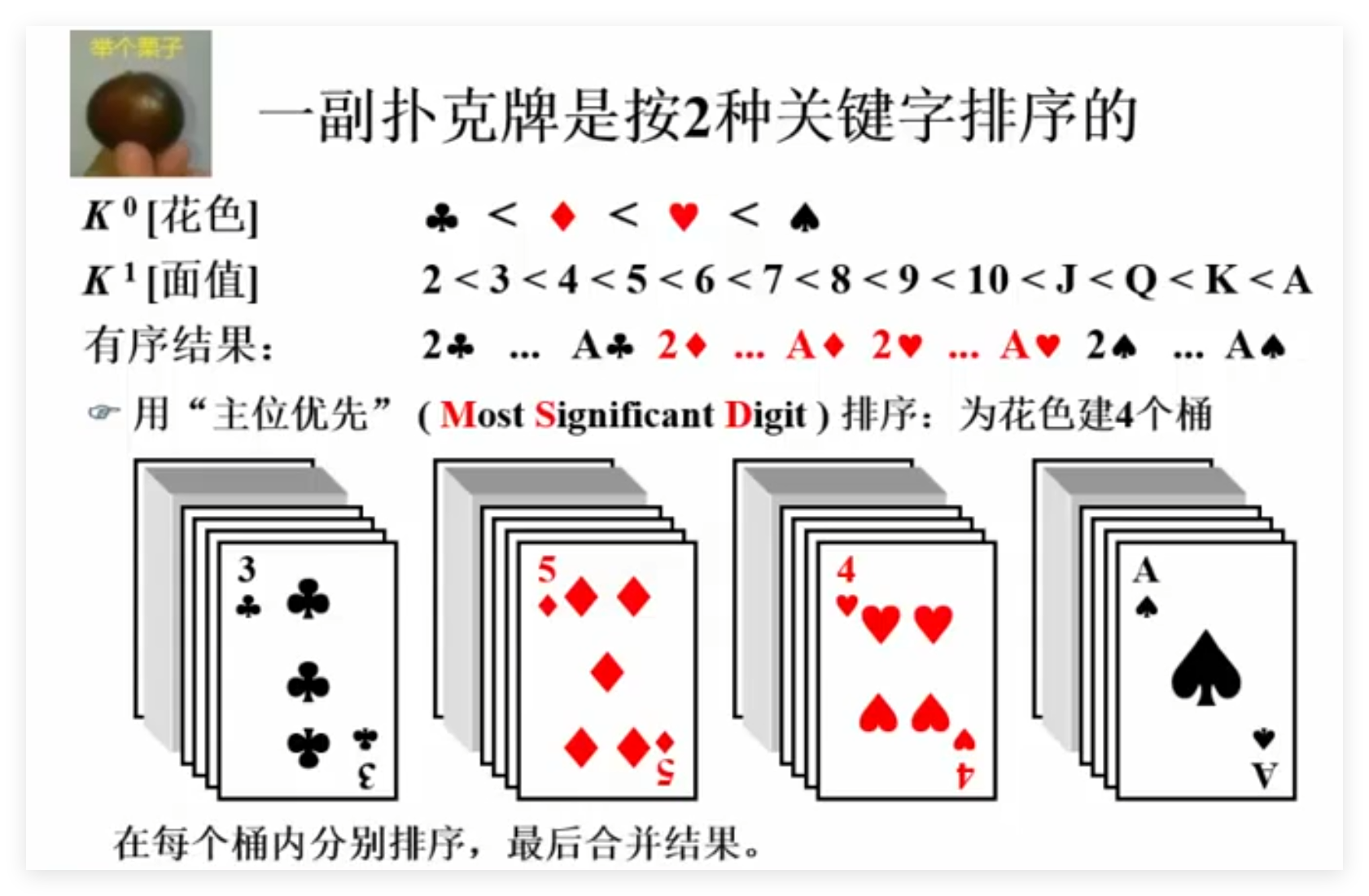
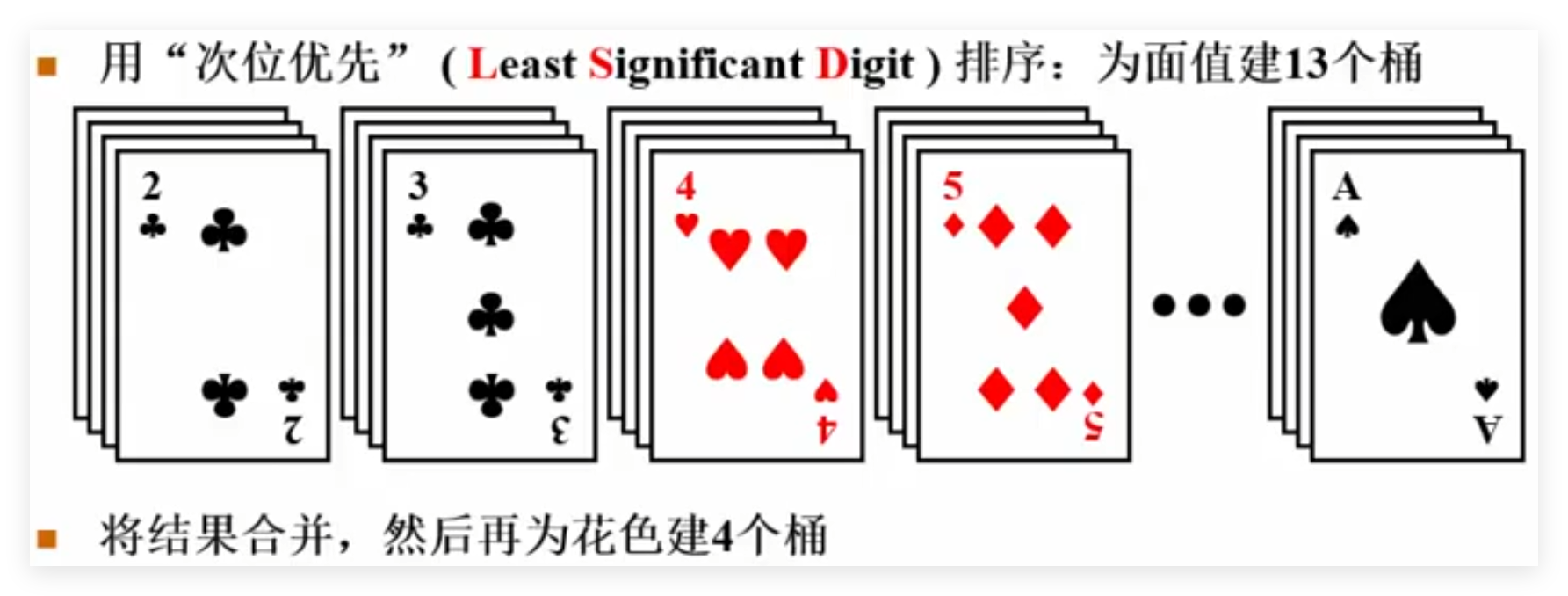
6.8 基数排序 6.9 多关键字排序 问题:LSD任何时候都比MSD快吗?
不一定。极端情况下,当主位可以一次性把元素都直接分开、而次位办不到的时候,显然MSD更好。一般情况下,如果主位的基数比次位大(例如扑克牌如果先按面值、同一面值内部按花色排序的话),则主位更有可能把元素分开,这时候用MSD就可能比LSD快。
6.10 排序算法的比较
排序方法
平均时间复杂度
最坏情况下时间复杂度
额外空间复杂度
稳定性
简单选择排序
O(N²)
O(N²)
O(1)
不稳定
冒泡排序
O(N²)
O(N²)
O(1)
稳定
直接插入排序
O(N²)
O(N²)
O(1)
稳定
希尔排序
O(Nᵈ)
O(N²)
O(1)
不稳定
堆排序
O(NlogN)
O(NlogN)
O(1)
不稳定
快速排序
O(NlogN)
O(N²)
O(logN)
不稳定
归并排序
O(NlogN)
O(NlogN)
O(N)
稳定
基数排序
O(P(N+B))
O(P(N+B))
O(N+B)
稳定
七、散列表 【问题】如何快速搜索到需要的关键词?如果关键词不方便比较怎么办?
查找的本质:已知对象找位置
有序安排对象:全序、半序
直接“算出”对象位置:散列
散列查找法的两项基本工作:
计算位置:构造散列函数确定关键词存储位置;
解决冲突:应用某种策略解决多个关键词位置相同的问题
时间复杂度几乎是常量:O(1), 即查找时间与间题规模无关!
7.1 基本概念 “散列函数”的基本思想:
(1)以关键字key为自变量,通过一个确定的函数h(散列函数)计算出对应的函数值h(key),作为数据对象的存储地址。
(2)可能不同的关键字会映射到同一个散列地址上,即h(keyi)= h(keyj)(当key¡≠keyj),称为“冲突(Collision)”
—需要某种冲突解决策略
好的散列函数需要考虑两个因素
计算简单,以便提高转换速度;
关键词对应的地址空间分布均匀,以尽量减少冲突。
1 2 3 4 5 选择合适的h (key),散列法的查找效率期望是常数0 (1 ),它几乎与关键字的空间的大小n无关!也适合于关键字直接比较计算量大的问题。a 为前提。因此,散列方法是一个以空间换时间
7.2 数字关键词的散列函数构造
直接地址法
取关键词的某个线性函数值为散列地址,即:h(key) = a * key + b
除留余数法
散列函数为:h(key) = key mod p
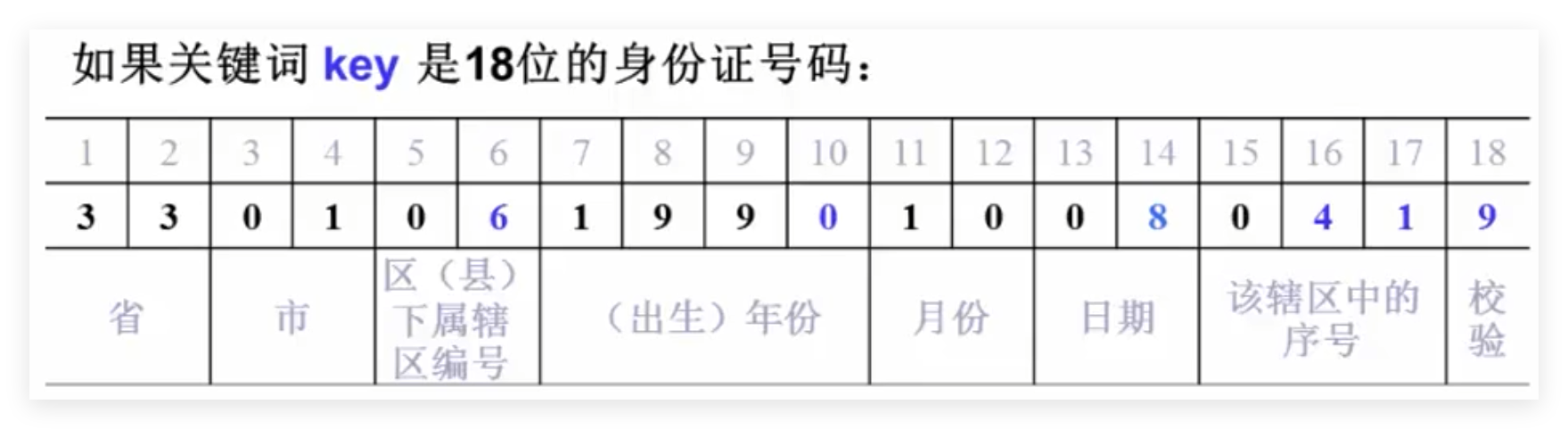
数字分析法
比如:取11位手机号码key的后4位作为地址:
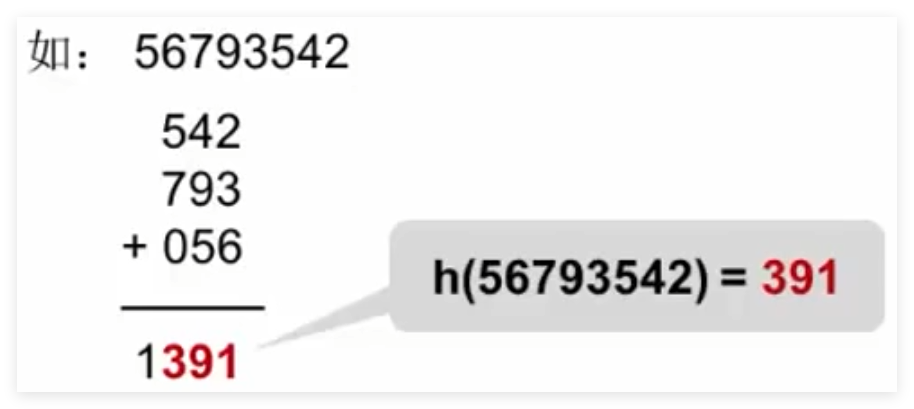
折叠法
平方取中法
一个简单的散列函数——ASCII码加和法
对字符型关键词key定义散列函数如下
简单的改进——前3个字符移位法
好的散列函数——移位法
涉及关键词所有n个字符,并且分布得很好:
7.3 冲突处理方法 常用处理冲突的思路:
换个位置:开放地址法
同一位置的冲突对象组织在一起:链地址法
7.3.1 开放定址法(OpenAddressing) 一旦产生了冲突(该地址已有其它元素),就按某种规则去寻找另一空地址
若发生了第i次冲突,试探的下一个地址将增加d,基本公式是:
hᵢ(key) = (h(key)+dᵢ) mod TableSize (1< i < TableSize)
dᵢ决定了不同的解决冲突方案:线性探测、平方探测、双散列
1 2 3 4 5 优点: 散列表是一个数组,存储效率高,随机查找 散列表有“聚集”现象
7.3.2 分离链接法(Separate Chaining) 将相应位置上冲突的所有关键词储存在同一个单链表中,将其相应的都串起来
1 2 3 4 5 散列表是顺序存储和链式存储的结合,链表部分的存储效率和查找效率都比较低。a 可能导致空间浪费,大的a 又将付出更多的时间代价。不均匀的链表长度导致时间效率的严重下降。